 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Detection in Indian Food Platters using Transfer Learning with YOLOv4
May 10, 2022
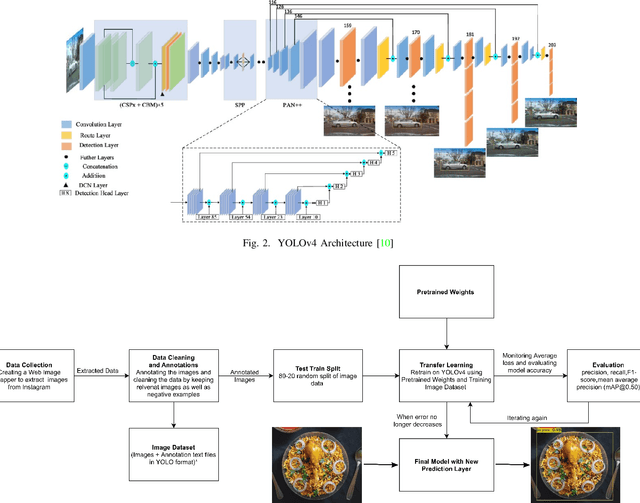

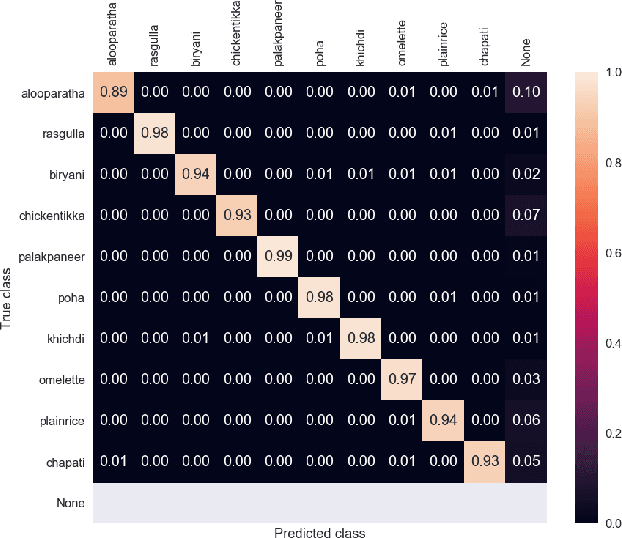
Object detection is a well-known problem in computer vision. Despite this, its usage and pervasiveness in the traditional Indian food dishes has been limited. Particularly, recognizing Indian food dishes present in a single photo is challenging due to three reasons: 1. Lack of annotated Indian food datasets 2. Non-distinct boundaries between the dishes 3. High intra-class variation. We solve these issues by providing a comprehensively labelled Indian food dataset- IndianFood10, which contains 10 food classes that appear frequently in a staple Indian meal and using transfer learning with YOLOv4 object detector model. Our model is able to achieve an overall mAP score of 91.8% and f1-score of 0.90 for our 10 class dataset. We also provide an extension of our 10 class dataset- IndianFood20, which contains 10 more traditional Indian food classes.
Transformer Assisted Convolutional Network for Cell Instance Segmentation
Oct 05, 2021

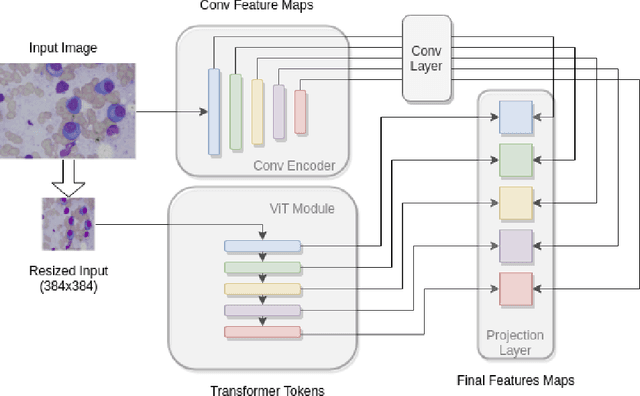
Region proposal based methods like R-CNN and Faster R-CNN models have proven to be extremely successful in object detection and segmentation tasks. Recently, Transformers have also gained popularity in the domain of Computer Vision, and are being utilised to improve the performance of conventional models. In this paper, we present a relatively new transformer based approach to enhance the performance of the conventional convolutional feature extractor in the existing region proposal based methods. Our approach merges the convolutional feature maps with transformer-based token embeddings by applying a projection operation similar to self-attention in transformers. The results of our experiments show that transformer assisted feature extractor achieves a significant improvement in mIoU (mean Intersection over Union) scores compared to vanilla convolutional backbone.
Improving non-deterministic uncertainty modelling in Industry 4.0 scheduling
Jan 08, 2021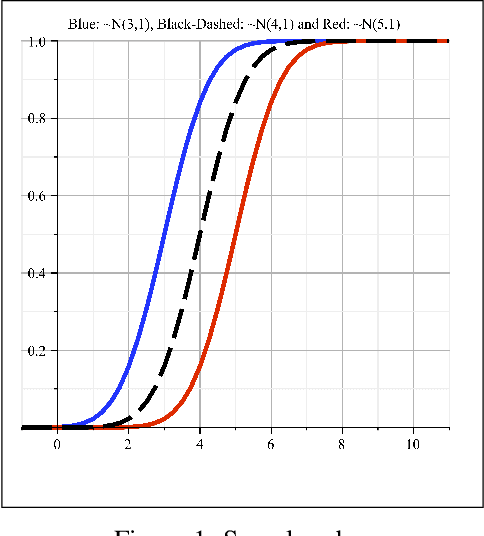
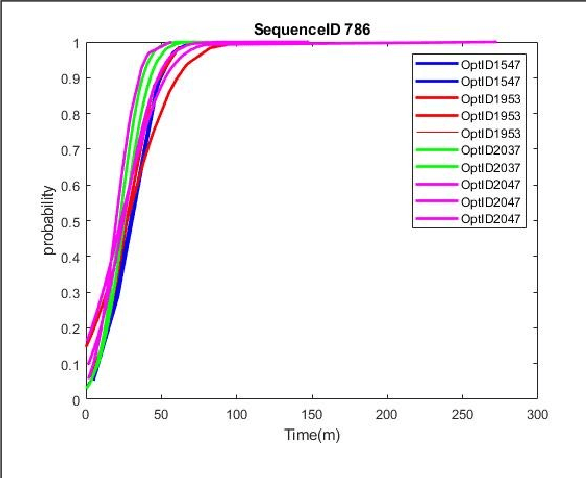
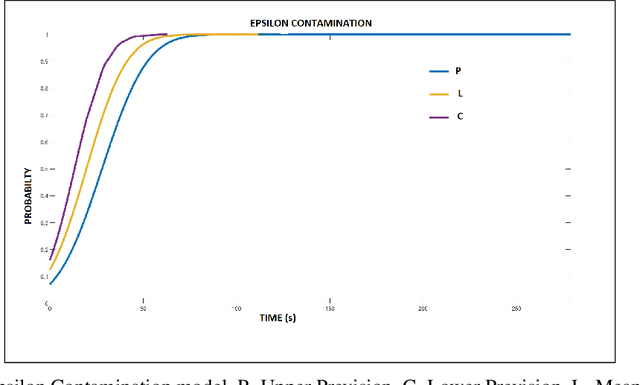
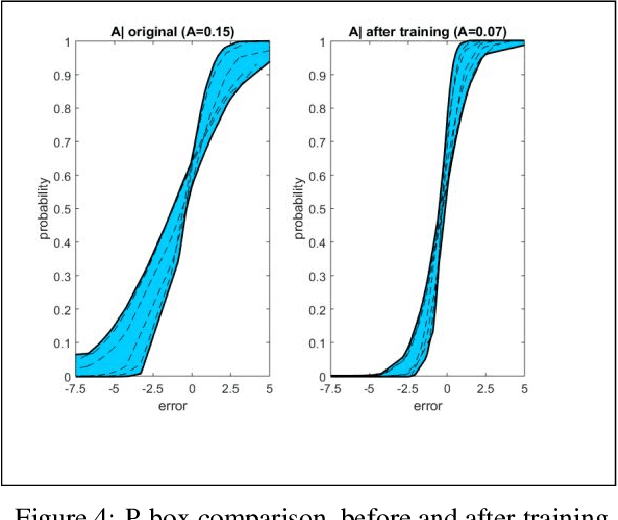
The latest Industrial revolution has helped industries in achieving very high rates of productivity and efficiency. It has introduced data aggregation and cyber-physical systems to optimize planning and scheduling. Although, uncertainty in the environment and the imprecise nature of human operators are not accurately considered for into the decision making process. This leads to delays in consignments and imprecise budget estimations. This widespread practice in the industrial models is flawed and requires rectification. Various other articles have approached to solve this problem through stochastic or fuzzy set model methods. This paper presents a comprehensive method to logically and realistically quantify the non-deterministic uncertainty through probabilistic uncertainty modelling. This method is applicable on virtually all Industrial data sets, as the model is self adjusting and uses epsilon-contamination to cater to limited or incomplete data sets. The results are numerically validated through an Industrial data set in Flanders, Belgium. The data driven results achieved through this robust scheduling method illustrate the improvement in performance.