 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Assisted Convolutional Network for Cell Instance Segmentation
Paper and Code


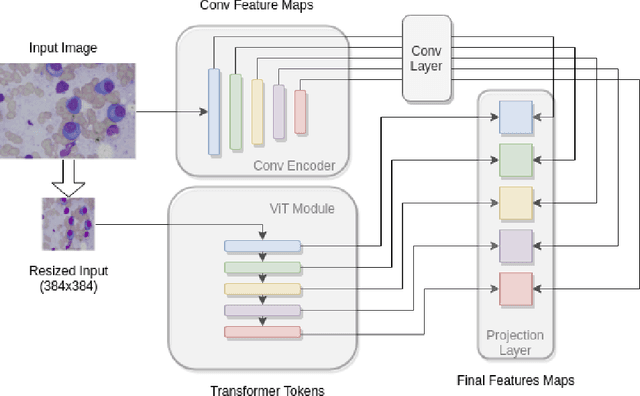
Region proposal based methods like R-CNN and Faster R-CNN models have proven to be extremely successful in object detection and segmentation tasks. Recently, Transformers have also gained popularity in the domain of Computer Vision, and are being utilised to improve the performance of conventional models. In this paper, we present a relatively new transformer based approach to enhance the performance of the conventional convolutional feature extractor in the existing region proposal based methods. Our approach merges the convolutional feature maps with transformer-based token embeddings by applying a projection operation similar to self-attention in transformers. The results of our experiments show that transformer assisted feature extractor achieves a significant improvement in mIoU (mean Intersection over Union) scores compared to vanilla convolutional backbone.