 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Person-to-Person Virtual Try-On with Multi-Garment Virtual Try-Off
Apr 17, 2025Computer vision is transforming fashion through Virtual Try-On (VTON) and Virtual Try-Off (VTOFF). VTON generates images of a person in a specified garment using a target photo and a standardized garment image, while a more challenging variant, Person-to-Person Virtual Try-On (p2p-VTON), uses a photo of another person wearing the garment. VTOFF, on the other hand, extracts standardized garment images from clothed individuals. We introduce TryOffDiff, a diffusion-based VTOFF model. Built on a latent diffusion framework with SigLIP image conditioning, it effectively captures garment properties like texture, shape, and patterns. TryOffDiff achieves state-of-the-art results on VITON-HD and strong performance on DressCode dataset, covering upper-body, lower-body, and dresses. Enhanced with class-specific embeddings, it pioneers multi-garment VTOFF, the first of its kind. When paired with VTON models, it improves p2p-VTON by minimizing unwanted attribute transfer, such as skin color. Code is available at: https://rizavelioglu.github.io/tryoffdiff/
TryOffDiff: Virtual-Try-Off via High-Fidelity Garment Reconstruction using Diffusion Models
Nov 27, 2024
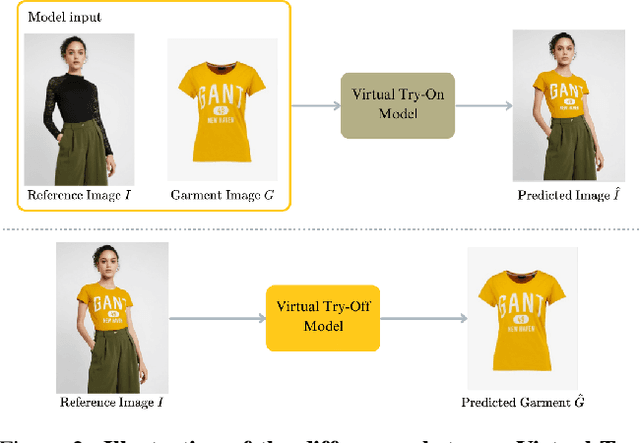


This paper introduces Virtual Try-Off (VTOFF), a novel task focused on generating standardized garment images from single photos of clothed individuals. Unlike traditional Virtual Try-On (VTON), which digitally dresses models, VTOFF aims to extract a canonical garment image, posing unique challenges in capturing garment shape, texture, and intricate patterns. This well-defined target makes VTOFF particularly effective for evaluating reconstruction fidelity in generative models. We present TryOffDiff, a model that adapts Stable Diffusion with SigLIP-based visual conditioning to ensure high fidelity and detail retention. Experiments on a modified VITON-HD dataset show that our approach outperforms baseline methods based on pose transfer and virtual try-on with fewer pre- and post-processing steps. Our analysis reveals that traditional image generation metrics inadequately assess reconstruction quality, prompting us to rely on DISTS for more accurate evaluation. Our results highlight the potential of VTOFF to enhance product imagery in e-commerce applications, advance generative model evaluation, and inspire future work on high-fidelity reconstruction. Demo, code, and models are available at: https://rizavelioglu.github.io/tryoffdiff/