 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Hate Speech in Memes Using Multimodal Deep Learning Approaches: Prize-winning solution to Hateful Memes Challenge
Dec 23, 2020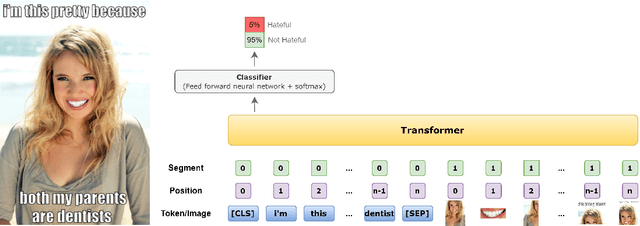
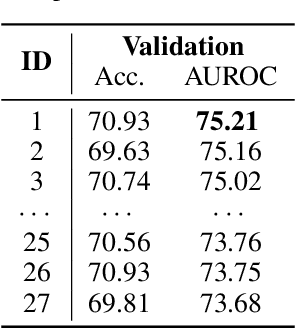

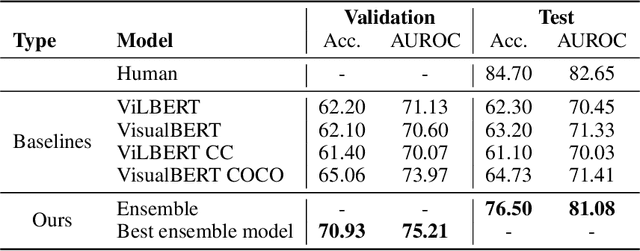
Memes on the Internet are often harmless and sometimes amusing. However, by using certain types of images, text, or combinations of both, the seemingly harmless meme becomes a multimodal type of hate speech -- a hateful meme. The Hateful Memes Challenge is a first-of-its-kind competition which focuses on detecting hate speech in multimodal memes and it proposes a new data set containing 10,000+ new examples of multimodal content. We utilize VisualBERT -- which meant to be the BERT of vision and language -- that was trained multimodally on images and captions and apply Ensemble Learning. Our approach achieves 0.811 AUROC with an accuracy of 0.765 on the challenge test set and placed third out of 3,173 participants in the Hateful Memes Challenge.