 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Novelties with Empty Classes
Apr 30, 2023
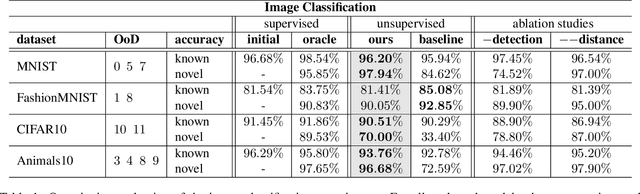
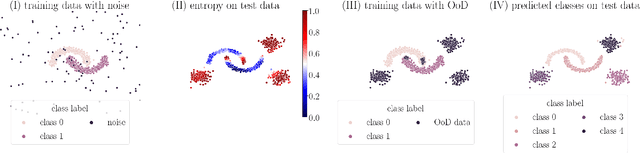
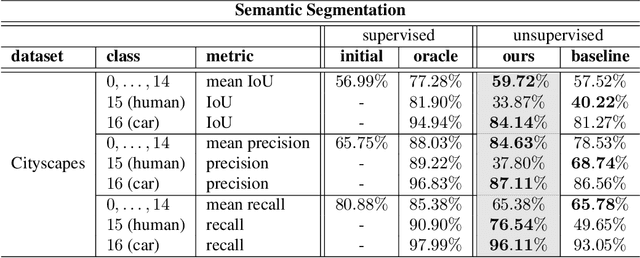
For open world applications, deep neural networks (DNNs) need to be aware of previously unseen data and adaptable to evolving environments. Furthermore, it is desirable to detect and learn novel classes which are not included in the DNNs underlying set of semantic classes in an unsupervised fashion. The method proposed in this article builds upon anomaly detection to retrieve out-of-distribution (OoD) data as candidates for new classes. We thereafter extend the DNN by $k$ empty classes and fine-tune it on the OoD data samples. To this end, we introduce two loss functions, which 1) entice the DNN to assign OoD samples to the empty classes and 2) to minimize the inner-class feature distances between them. Thus, instead of ground truth which contains labels for the different novel classes, the DNN obtains a single OoD label together with a distance matrix, which is computed in advance. We perform several experiments for image classification and semantic segmentation, which demonstrate that a DNN can extend its own semantic space by multiple classes without having access to ground truth.
Perception Datasets for Anomaly Detection in Autonomous Driving: A Survey
Feb 06, 2023



Deep neural networks (DNN) which are employed in perception systems for autonomous driving require a huge amount of data to train on, as they must reliably achieve high performance in all kinds of situations. However, these DNN are usually restricted to a closed set of semantic classes available in their training data, and are therefore unreliable when confronted with previously unseen instances. Thus, multiple perception datasets have been created for the evaluation of anomaly detection methods, which can be categorized into three groups: real anomalies in real-world, synthetic anomalies augmented into real-world and completely synthetic scenes. This survey provides a structured and, to the best of our knowledge, complete overview and comparison of perception datasets for anomaly detection in autonomous driving. Each chapter provides information about tasks and ground truth, context information, and licenses. Additionally, we discuss current weaknesses and gaps in existing datasets to underline the importance of developing further data.
Two Video Data Sets for Tracking and Retrieval of Out of Distribution Objects
Oct 05, 2022
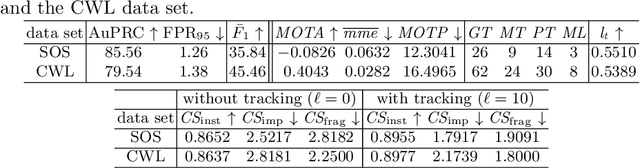
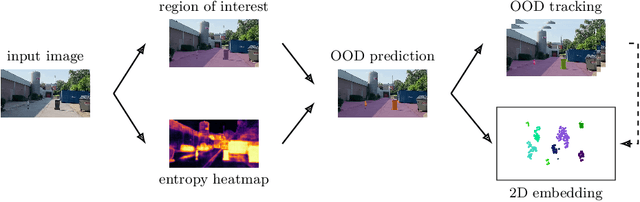

In this work we present two video test data sets for the novel computer vision (CV) task of out of distribution tracking (OOD tracking). Here, OOD objects are understood as objects with a semantic class outside the semantic space of an underlying image segmentation algorithm, or an instance within the semantic space which however looks decisively different from the instances contained in the training data. OOD objects occurring on video sequences should be detected on single frames as early as possible and tracked over their time of appearance as long as possible. During the time of appearance, they should be segmented as precisely as possible. We present the SOS data set containing 20 video sequences of street scenes and more than 1000 labeled frames with up to two OOD objects. We furthermore publish the synthetic CARLA-WildLife data set that consists of 26 video sequences containing up to four OOD objects on a single frame. We propose metrics to measure the success of OOD tracking and develop a baseline algorithm that efficiently tracks the OOD objects. As an application that benefits from OOD tracking, we retrieve OOD sequences from unlabeled videos of street scenes containing OOD objects.
Detecting and Learning the Unknown in Semantic Segmentation
Feb 17, 2022


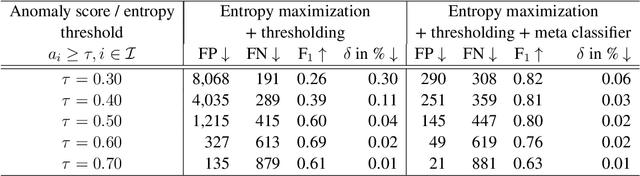
Semantic segmentation is a crucial component for perception in automated driving. Deep neural networks (DNNs) are commonly used for this task and they are usually trained on a closed set of object classes appearing in a closed operational domain. However, this is in contrast to the open world assumption in automated driving that DNNs are deployed to. Therefore, DNNs necessarily face data that they have never encountered previously, also known as anomalies, which are extremely safety-critical to properly cope with. In this work, we first give an overview about anomalies from an information-theoretic perspective. Next, we review research in detecting semantically unknown objects in semantic segmentation. We demonstrate that training for high entropy responses on anomalous objects outperforms other recent methods, which is in line with our theoretical findings. Moreover, we examine a method to assess the occurrence frequency of anomalies in order to select anomaly types to include into a model's set of semantic categories. We demonstrate that these anomalies can then be learned in an unsupervised fashion, which is particularly suitable in online applications based on deep learning.
Towards Unsupervised Open World Semantic Segmentation
Jan 04, 2022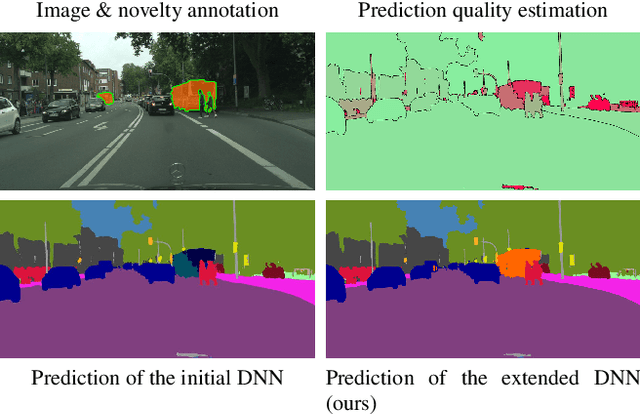
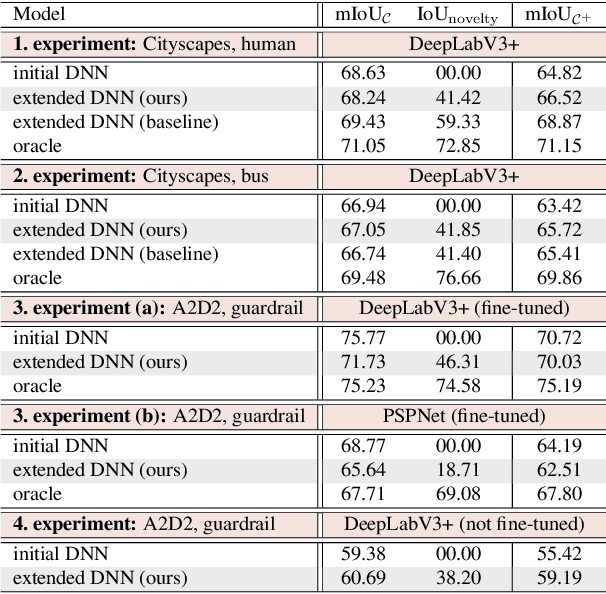


For the semantic segmentation of images, state-of-the-art deep neural networks (DNNs) achieve high segmentation accuracy if that task is restricted to a closed set of classes. However, as of now DNNs have limited ability to operate in an open world, where they are tasked to identify pixels belonging to unknown objects and eventually to learn novel classes, incrementally. Humans have the capability to say: I don't know what that is, but I've already seen something like that. Therefore, it is desirable to perform such an incremental learning task in an unsupervised fashion. We introduce a method where unknown objects are clustered based on visual similarity. Those clusters are utilized to define new classes and serve as training data for unsupervised incremental learning. More precisely, the connected components of a predicted semantic segmentation are assessed by a segmentation quality estimate. connected components with a low estimated prediction quality are candidates for a subsequent clustering. Additionally, the component-wise quality assessment allows for obtaining predicted segmentation masks for the image regions potentially containing unknown objects. The respective pixels of such masks are pseudo-labeled and afterwards used for re-training the DNN, i.e., without the use of ground truth generated by humans. In our experiments we demonstrate that, without access to ground truth and even with few data, a DNN's class space can be extended by a novel class, achieving considerable segmentation accuracy.
SegmentMeIfYouCan: A Benchmark for Anomaly Segmentation
Apr 30, 2021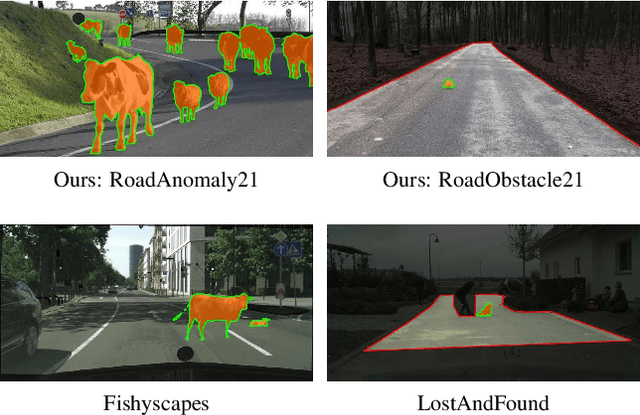
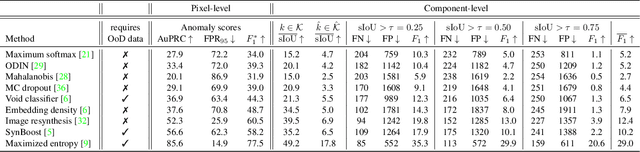

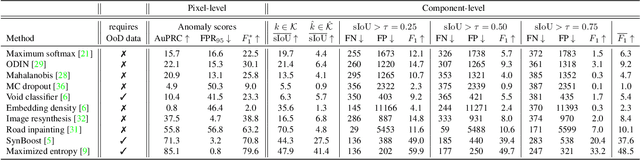
State-of-the-art semantic or instance segmentation deep neural networks (DNNs) are usually trained on a closed set of semantic classes. As such, they are ill-equipped to handle previously-unseen objects. However, detecting and localizing such objects is crucial for safety-critical applications such as perception for automated driving, especially if they appear on the road ahead. While some methods have tackled the tasks of anomalous or out-of-distribution object segmentation, progress remains slow, in large part due to the lack of solid benchmarks; existing datasets either consist of synthetic data, or suffer from label inconsistencies. In this paper, we bridge this gap by introducing the "SegmentMeIfYouCan" benchmark. Our benchmark addresses two tasks: Anomalous object segmentation, which considers any previously-unseen object category; and road obstacle segmentation, which focuses on any object on the road, may it be known or unknown. We provide two corresponding datasets together with a test suite performing an in-depth method analysis, considering both established pixel-wise performance metrics and recent component-wise ones, which are insensitive to object sizes. We empirically evaluate multiple state-of-the-art baseline methods, including several specifically designed for anomaly / obstacle segmentation, on our datasets as well as on public ones, using our benchmark suite. The anomaly and obstacle segmentation results show that our datasets contribute to the diversity and challengingness of both dataset landscapes.