 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Attention for Consistent Video Semantic Segmentation in Automated Driving
Feb 10, 2026Deep neural networks, especially transformer-based architectures, have achieved remarkable success in semantic segmentation for environmental perception. However, existing models process video frames independently, thus failing to leverage temporal consistency, which could significantly improve both accuracy and stability in dynamic scenes. In this work, we propose a Spatio-Temporal Attention (STA) mechanism that extends transformer attention blocks to incorporate multi-frame context, enabling robust temporal feature representations for video semantic segmentation. Our approach modifies standard self-attention to process spatio-temporal feature sequences while maintaining computational efficiency and requiring minimal changes to existing architectures. STA demonstrates broad applicability across diverse transformer architectures and remains effective across both lightweight and larger-scale models. A comprehensive evaluation on the Cityscapes and BDD100k datasets shows substantial improvements of 9.20 percentage points in temporal consistency metrics and up to 1.76 percentage points in mean intersection over union compared to single-frame baselines. These results demonstrate STA as an effective architectural enhancement for video-based semantic segmentation applications.
Out-of-Distribution Segmentation via Wasserstein-Based Evidential Uncertainty
Dec 12, 2025Deep neural networks achieve superior performance in semantic segmentation, but are limited to a predefined set of classes, which leads to failures when they encounter unknown objects in open-world scenarios. Recognizing and segmenting these out-of-distribution (OOD) objects is crucial for safety-critical applications such as automated driving. In this work, we present an evidence segmentation framework using a Wasserstein loss, which captures distributional distances while respecting the probability simplex geometry. Combined with Kullback-Leibler regularization and Dice structural consistency terms, our approach leads to improved OOD segmentation performance compared to uncertainty-based approaches.
Towards Reliable Detection of Empty Space: Conditional Marked Point Processes for Object Detection
Jun 26, 2025Deep neural networks have set the state-of-the-art in computer vision tasks such as bounding box detection and semantic segmentation. Object detectors and segmentation models assign confidence scores to predictions, reflecting the model's uncertainty in object detection or pixel-wise classification. However, these confidence estimates are often miscalibrated, as their architectures and loss functions are tailored to task performance rather than probabilistic foundation. Even with well calibrated predictions, object detectors fail to quantify uncertainty outside detected bounding boxes, i.e., the model does not make a probability assessment of whether an area without detected objects is truly free of obstacles. This poses a safety risk in applications such as automated driving, where uncertainty in empty areas remains unexplored. In this work, we propose an object detection model grounded in spatial statistics. Bounding box data matches realizations of a marked point process, commonly used to describe the probabilistic occurrence of spatial point events identified as bounding box centers, where marks are used to describe the spatial extension of bounding boxes and classes. Our statistical framework enables a likelihood-based training and provides well-defined confidence estimates for whether a region is drivable, i.e., free of objects. We demonstrate the effectiveness of our method through calibration assessments and evaluation of performance.
Multi-Scale Foreground-Background Confidence for Out-of-Distribution Segmentation
Dec 22, 2024
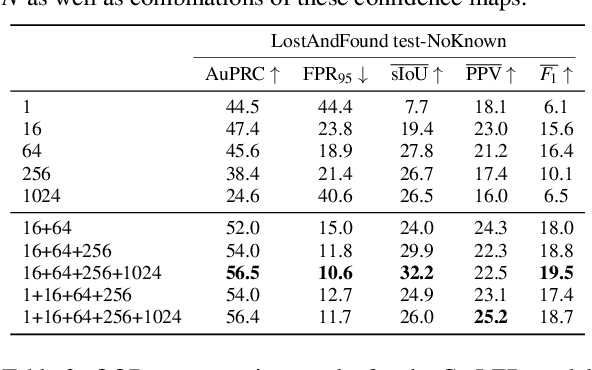
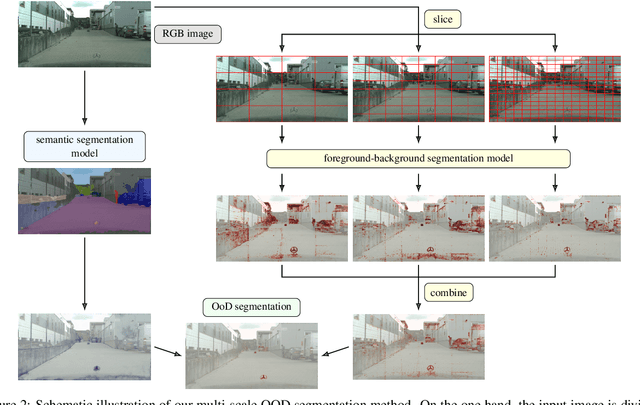

Deep neural networks have shown outstanding performance in computer vision tasks such as semantic segmentation and have defined the state-of-the-art. However, these segmentation models are trained on a closed and predefined set of semantic classes, which leads to significant prediction failures in open-world scenarios on unknown objects. As this behavior prevents the application in safety-critical applications such as automated driving, the detection and segmentation of these objects from outside their predefined semantic space (out-of-distribution (OOD) objects) is of the utmost importance. In this work, we present a multi-scale OOD segmentation method that exploits the confidence information of a foreground-background segmentation model. While semantic segmentation models are trained on specific classes, this restriction does not apply to foreground-background methods making them suitable for OOD segmentation. We consider the per pixel confidence score of the model prediction which is close to 1 for a pixel in a foreground object. By aggregating these confidence values for different sized patches, objects of various sizes can be identified in a single image. Our experiments show improved performance of our method in OOD segmentation compared to comparable baselines in the SegmentMeIfYouCan benchmark.
Integrating uncertainty quantification into randomized smoothing based robustness guarantees
Oct 27, 2024



Deep neural networks have proven to be extremely powerful, however, they are also vulnerable to adversarial attacks which can cause hazardous incorrect predictions in safety-critical applications. Certified robustness via randomized smoothing gives a probabilistic guarantee that the smoothed classifier's predictions will not change within an $\ell_2$-ball around a given input. On the other hand (uncertainty) score-based rejection is a technique often applied in practice to defend models against adversarial attacks. In this work, we fuse these two approaches by integrating a classifier that abstains from predicting when uncertainty is high into the certified robustness framework. This allows us to derive two novel robustness guarantees for uncertainty aware classifiers, namely (i) the radius of an $\ell_2$-ball around the input in which the same label is predicted and uncertainty remains low and (ii) the $\ell_2$-radius of a ball in which the predictions will either not change or be uncertain. While the former provides robustness guarantees with respect to attacks aiming at increased uncertainty, the latter informs about the amount of input perturbation necessary to lead the uncertainty aware model into a wrong prediction. Notably, this is on CIFAR10 up to 20.93% larger than for models not allowing for uncertainty based rejection. We demonstrate, that the novel framework allows for a systematic robustness evaluation of different network architectures and uncertainty measures and to identify desired properties of uncertainty quantification techniques. Moreover, we show that leveraging uncertainty in a smoothed classifier helps out-of-distribution detection.
Detecting Adversarial Attacks in Semantic Segmentation via Uncertainty Estimation: A Deep Analysis
Aug 19, 2024



Deep neural networks have demonstrated remarkable effectiveness across a wide range of tasks such as semantic segmentation. Nevertheless, these networks are vulnerable to adversarial attacks that add imperceptible perturbations to the input image, leading to false predictions. This vulnerability is particularly dangerous in safety-critical applications like automated driving. While adversarial examples and defense strategies are well-researched in the context of image classification, there is comparatively less research focused on semantic segmentation. Recently, we have proposed an uncertainty-based method for detecting adversarial attacks on neural networks for semantic segmentation. We observed that uncertainty, as measured by the entropy of the output distribution, behaves differently on clean versus adversely perturbed images, and we utilize this property to differentiate between the two. In this extended version of our work, we conduct a detailed analysis of uncertainty-based detection of adversarial attacks including a diverse set of adversarial attacks and various state-of-the-art neural networks. Our numerical experiments show the effectiveness of the proposed uncertainty-based detection method, which is lightweight and operates as a post-processing step, i.e., no model modifications or knowledge of the adversarial example generation process are required.
Reducing Texture Bias of Deep Neural Networks via Edge Enhancing Diffusion
Feb 14, 2024Convolutional neural networks (CNNs) for image processing tend to focus on localized texture patterns, commonly referred to as texture bias. While most of the previous works in the literature focus on the task of image classification, we go beyond this and study the texture bias of CNNs in semantic segmentation. In this work, we propose to train CNNs on pre-processed images with less texture to reduce the texture bias. Therein, the challenge is to suppress image texture while preserving shape information. To this end, we utilize edge enhancing diffusion (EED), an anisotropic image diffusion method initially introduced for image compression, to create texture reduced duplicates of existing datasets. Extensive numerical studies are performed with both CNNs and vision transformer models trained on original data and EED-processed data from the Cityscapes dataset and the CARLA driving simulator. We observe strong texture-dependence of CNNs and moderate texture-dependence of transformers. Training CNNs on EED-processed images enables the models to become completely ignorant with respect to texture, demonstrating resilience with respect to texture re-introduction to any degree. Additionally we analyze the performance reduction in depth on a level of connected components in the semantic segmentation and study the influence of EED pre-processing on domain generalization as well as adversarial robustness.
Uncertainty-weighted Loss Functions for Improved Adversarial Attacks on Semantic Segmentation
Oct 26, 2023



State-of-the-art deep neural networks have been shown to be extremely powerful in a variety of perceptual tasks like semantic segmentation. However, these networks are vulnerable to adversarial perturbations of the input which are imperceptible for humans but lead to incorrect predictions. Treating image segmentation as a sum of pixel-wise classifications, adversarial attacks developed for classification models were shown to be applicable to segmentation models as well. In this work, we present simple uncertainty-based weighting schemes for the loss functions of such attacks that (i) put higher weights on pixel classifications which can more easily perturbed and (ii) zero-out the pixel-wise losses corresponding to those pixels that are already confidently misclassified. The weighting schemes can be easily integrated into the loss function of a range of well-known adversarial attackers with minimal additional computational overhead, but lead to significant improved perturbation performance, as we demonstrate in our empirical analysis on several datasets and models.
Uncertainty-based Detection of Adversarial Attacks in Semantic Segmentation
May 22, 2023



State-of-the-art deep neural networks have proven to be highly powerful in a broad range of tasks, including semantic image segmentation. However, these networks are vulnerable against adversarial attacks, i.e., non-perceptible perturbations added to the input image causing incorrect predictions, which is hazardous in safety-critical applications like automated driving. Adversarial examples and defense strategies are well studied for the image classification task, while there has been limited research in the context of semantic segmentation. First works however show that the segmentation outcome can be severely distorted by adversarial attacks. In this work, we introduce an uncertainty-based method for the detection of adversarial attacks in semantic segmentation. We observe that uncertainty as for example captured by the entropy of the output distribution behaves differently on clean and perturbed images using this property to distinguish between the two cases. Our method works in a light-weight and post-processing manner, i.e., we do not modify the model or need knowledge of the process used for generating adversarial examples. In a thorough empirical analysis, we demonstrate the ability of our approach to detect perturbed images across multiple types of adversarial attacks.
Pixel-wise Gradient Uncertainty for Convolutional Neural Networks applied to Out-of-Distribution Segmentation
Mar 13, 2023



In recent years, deep neural networks have defined the state-of-the-art in semantic segmentation where their predictions are constrained to a predefined set of semantic classes. They are to be deployed in applications such as automated driving, although their categorically confined expressive power runs contrary to such open world scenarios. Thus, the detection and segmentation of objects from outside their predefined semantic space, i.e., out-of-distribution (OoD) objects, is of highest interest. Since uncertainty estimation methods like softmax entropy or Bayesian models are sensitive to erroneous predictions, these methods are a natural baseline for OoD detection. Here, we present a method for obtaining uncertainty scores from pixel-wise loss gradients which can be computed efficiently during inference. Our approach is simple to implement for a large class of models, does not require any additional training or auxiliary data and can be readily used on pre-trained segmentation models. Our experiments show the ability of our method to identify wrong pixel classifications and to estimate prediction quality. In particular, we observe superior performance in terms of OoD segmentation to comparable baselines on the SegmentMeIfYouCan benchmark, clearly outperforming methods which are similarly flexible to implement.