 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttEntropy: Segmenting Unknown Objects in Complex Scenes using the Spatial Attention Entropy of Semantic Segmentation Transformers
Dec 29, 2022Vision transformers have emerged as powerful tools for many computer vision tasks. It has been shown that their features and class tokens can be used for salient object segmentation. However, the properties of segmentation transformers remain largely unstudied. In this work we conduct an in-depth study of the spatial attentions of different backbone layers of semantic segmentation transformers and uncover interesting properties. The spatial attentions of a patch intersecting with an object tend to concentrate within the object, whereas the attentions of larger, more uniform image areas rather follow a diffusive behavior. In other words, vision transformers trained to segment a fixed set of object classes generalize to objects well beyond this set. We exploit this by extracting heatmaps that can be used to segment unknown objects within diverse backgrounds, such as obstacles in traffic scenes. Our method is training-free and its computational overhead negligible. We use off-the-shelf transformers trained for street-scene segmentation to process other scene types.
Perspective Aware Road Obstacle Detection
Oct 04, 2022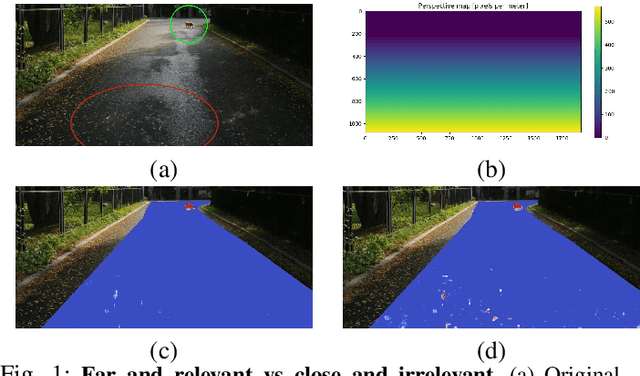

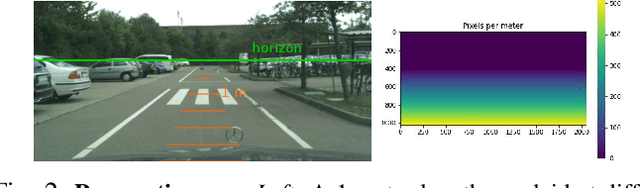

While road obstacle detection techniques have become increasingly effective, they typically ignore the fact that, in practice, the apparent size of the obstacles decreases as their distance to the vehicle increases. In this paper, we account for this by computing a scale map encoding the apparent size of a hypothetical object at every image location. We then leverage this perspective map to (i) generate training data by injecting synthetic objects onto the road in a more realistic fashion than existing methods; and (ii) incorporate perspective information in the decoding part of the detection network to guide the obstacle detector. Our results on standard benchmarks show that, together, these two strategies significantly boost the obstacle detection performance, allowing our approach to consistently outperform state-of-the-art methods in terms of instance-level obstacle detection.
SegmentMeIfYouCan: A Benchmark for Anomaly Segmentation
Apr 30, 2021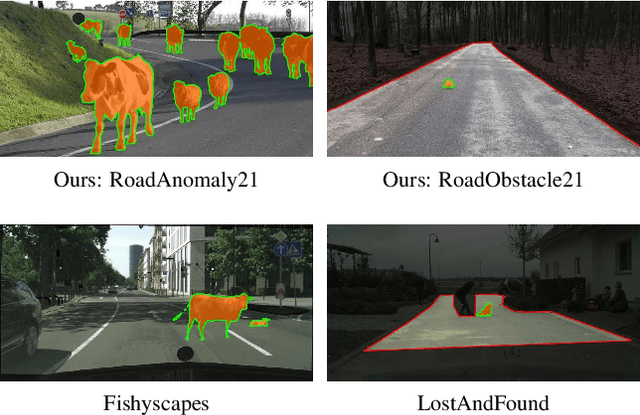
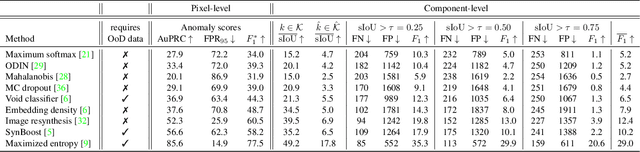

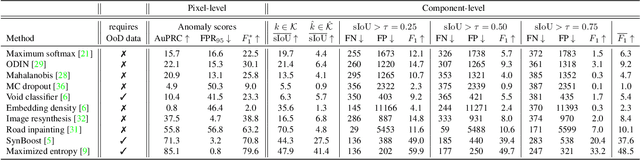
State-of-the-art semantic or instance segmentation deep neural networks (DNNs) are usually trained on a closed set of semantic classes. As such, they are ill-equipped to handle previously-unseen objects. However, detecting and localizing such objects is crucial for safety-critical applications such as perception for automated driving, especially if they appear on the road ahead. While some methods have tackled the tasks of anomalous or out-of-distribution object segmentation, progress remains slow, in large part due to the lack of solid benchmarks; existing datasets either consist of synthetic data, or suffer from label inconsistencies. In this paper, we bridge this gap by introducing the "SegmentMeIfYouCan" benchmark. Our benchmark addresses two tasks: Anomalous object segmentation, which considers any previously-unseen object category; and road obstacle segmentation, which focuses on any object on the road, may it be known or unknown. We provide two corresponding datasets together with a test suite performing an in-depth method analysis, considering both established pixel-wise performance metrics and recent component-wise ones, which are insensitive to object sizes. We empirically evaluate multiple state-of-the-art baseline methods, including several specifically designed for anomaly / obstacle segmentation, on our datasets as well as on public ones, using our benchmark suite. The anomaly and obstacle segmentation results show that our datasets contribute to the diversity and challengingness of both dataset landscapes.
Detecting Road Obstacles by Erasing Them
Dec 25, 2020
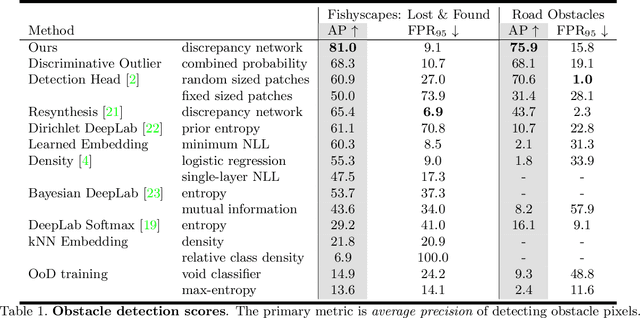

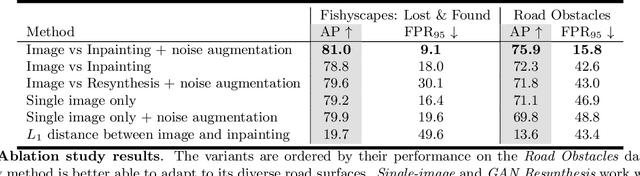
Vehicles can encounter a myriad of obstacles on the road, and it is not feasible to record them all beforehand to train a detector. Our method selects image patches and inpaints them with the surrounding road texture, which tends to remove obstacles from those patches. It them uses a network trained to recognize discrepancies between the original patch and the inpainted one, which signals an erased obstacle. We also contribute a new dataset for monocular road obstacle detection, and show that our approach outperforms the state-of-the-art methods on both our new dataset and the standard Fishyscapes Lost & Found benchmark.
Detecting the Unexpected via Image Resynthesis
Apr 17, 2019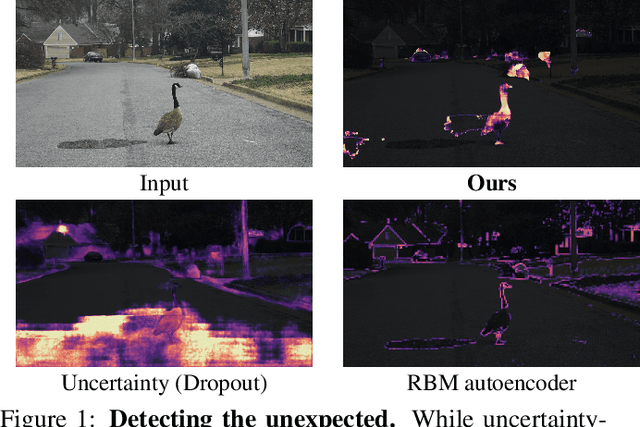
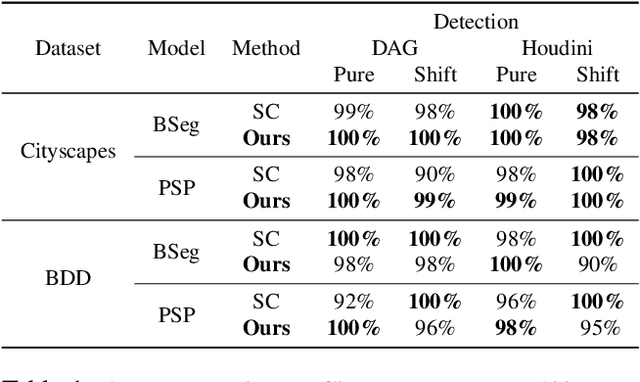
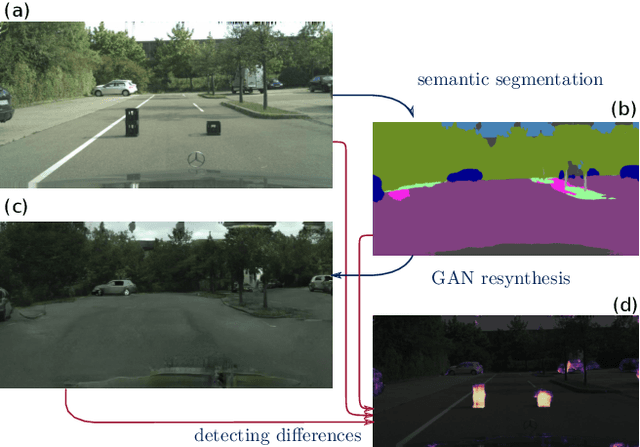
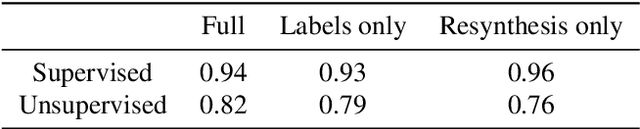
Classical semantic segmentation methods, including the recent deep learning ones, assume that all classes observed at test time have been seen during training. In this paper, we tackle the more realistic scenario where unexpected objects of unknown classes can appear at test time. The main trends in this area either leverage the notion of prediction uncertainty to flag the regions with low confidence as unknown, or rely on autoencoders and highlight poorly-decoded regions. Having observed that, in both cases, the detected regions typically do not correspond to unexpected objects, in this paper, we introduce a drastically different strategy: It relies on the intuition that the network will produce spurious labels in regions depicting unexpected objects. Therefore, resynthesizing the image from the resulting semantic map will yield significant appearance differences with respect to the input image. In other words, we translate the problem of detecting unknown classes to one of identifying poorly-resynthesized image regions. We show that this outperforms both uncertainty- and autoencoder-based methods.
Geometric and Physical Constraints for Head Plane Crowd Density Estimation in Videos
Mar 23, 2018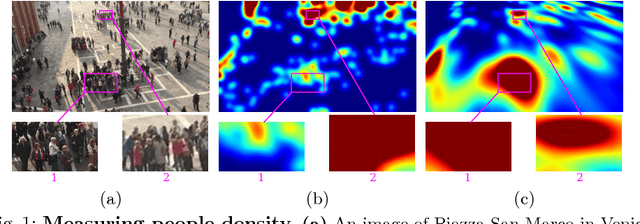
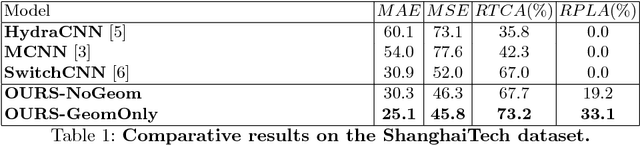
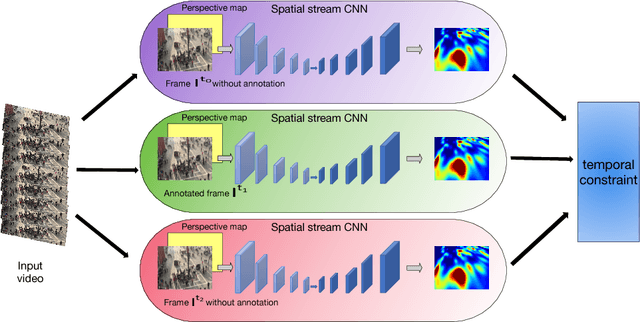
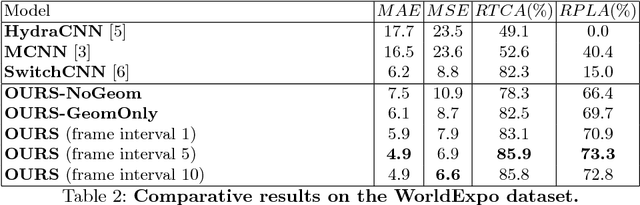
State-of-the-art methods of people counting in crowded scenes rely on deep networks to estimate people density in the image plane. Perspective distortion effects are handled implicitly by either learning scale-invariant features or estimating density in patches of different sizes, neither of which accounts for the fact that scale changes must be consistent over the whole scene. In this paper, we show that feeding an explicit model of the scale changes to the network considerably increases performance. An added benefit is that it lets us reason in terms of number of people per square meter on the ground, allowing us to enforce physically-inspired temporal consistency constraints that do not have to be learned. This yields an algorithm that outperforms state-of-the-art methods on crowded scenes, especially when perspective effects are strong.