 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric and Physical Constraints for Head Plane Crowd Density Estimation in Videos
Paper and Code
Mar 23, 2018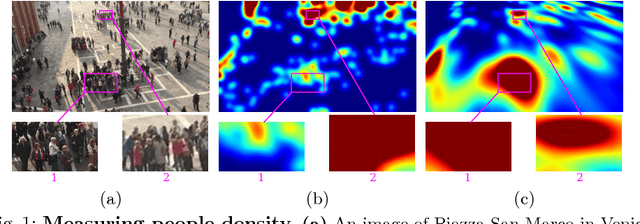
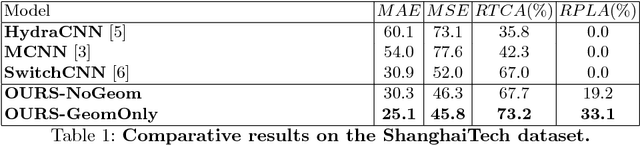
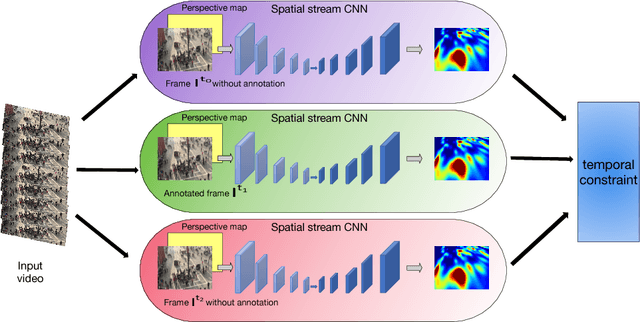
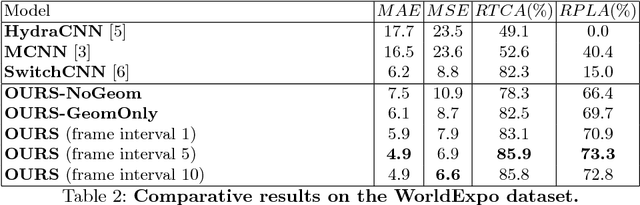
State-of-the-art methods of people counting in crowded scenes rely on deep networks to estimate people density in the image plane. Perspective distortion effects are handled implicitly by either learning scale-invariant features or estimating density in patches of different sizes, neither of which accounts for the fact that scale changes must be consistent over the whole scene. In this paper, we show that feeding an explicit model of the scale changes to the network considerably increases performance. An added benefit is that it lets us reason in terms of number of people per square meter on the ground, allowing us to enforce physically-inspired temporal consistency constraints that do not have to be learned. This yields an algorithm that outperforms state-of-the-art methods on crowded scenes, especially when perspective effects are strong.