 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting the Unexpected via Image Resynthesis
Apr 17, 2019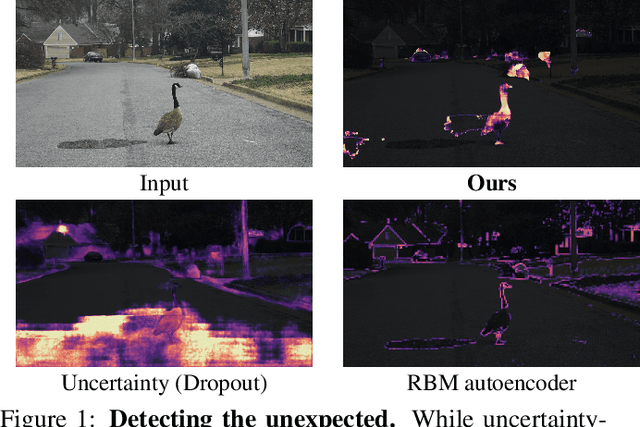
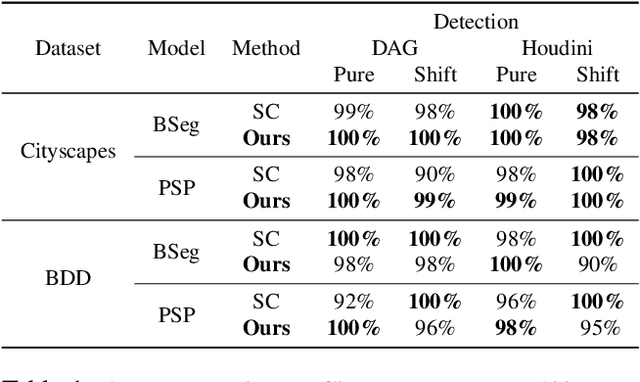
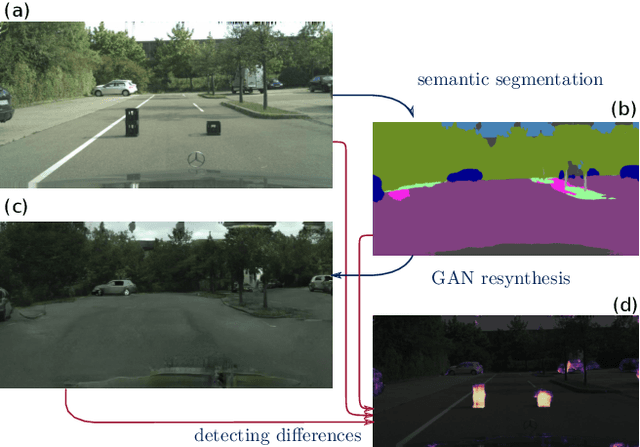
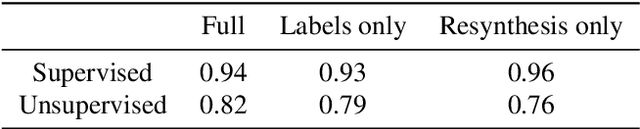
Classical semantic segmentation methods, including the recent deep learning ones, assume that all classes observed at test time have been seen during training. In this paper, we tackle the more realistic scenario where unexpected objects of unknown classes can appear at test time. The main trends in this area either leverage the notion of prediction uncertainty to flag the regions with low confidence as unknown, or rely on autoencoders and highlight poorly-decoded regions. Having observed that, in both cases, the detected regions typically do not correspond to unexpected objects, in this paper, we introduce a drastically different strategy: It relies on the intuition that the network will produce spurious labels in regions depicting unexpected objects. Therefore, resynthesizing the image from the resulting semantic map will yield significant appearance differences with respect to the input image. In other words, we translate the problem of detecting unknown classes to one of identifying poorly-resynthesized image regions. We show that this outperforms both uncertainty- and autoencoder-based methods.