 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Human Maze: Real-Time Robot Pathfinding with Generative Imitation Learning
Aug 07, 2024



This paper addresses navigation in crowded environments by integrating goal-conditioned generative models with Sampling-based Model Predictive Control (SMPC). We introduce goal-conditioned autoregressive models to generate crowd behaviors, capturing intricate interactions among individuals. The model processes potential robot trajectory samples and predicts the reactions of surrounding individuals, enabling proactive robotic navigation in complex scenarios. Extensive experiments show that this algorithm enables real-time navigation, significantly reducing collision rates and path lengths, and outperforming selected baseline methods. The practical effectiveness of this algorithm is validated on an actual robotic platform, demonstrating its capability in dynamic settings.
Efficient fine-grained road segmentation using superpixel-based CNN and CRF models
Jun 22, 2022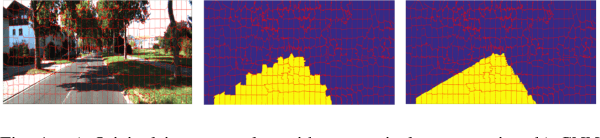
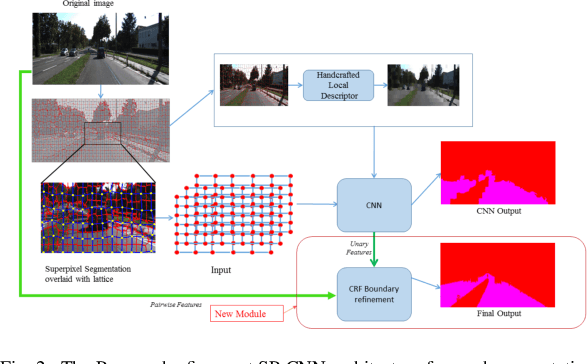

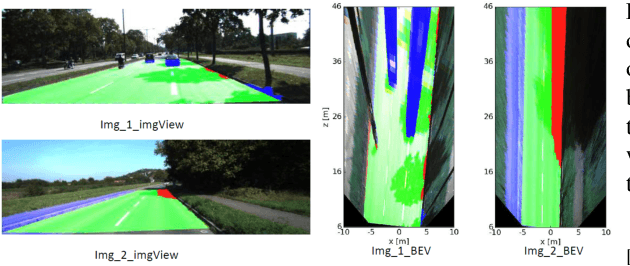
Towards a safe and comfortable driving, road scene segmentation is a rudimentary problem in camera-based advance driver assistance systems (ADAS). Despite of the great achievement of Convolutional Neural Networks (CNN) for semantic segmentation task, the high computational efforts of CNN based methods is still a challenging area. In recent work, we proposed a novel approach to utilise the advantages of CNNs for the task of road segmentation at reasonable computational effort. The runtime benefits from using irregular super pixels as basis for the input for the CNN rather than the image grid, which tremendously reduces the input size. Although, this method achieved remarkable low computational time in both training and testing phases, the lower resolution of the super pixel domain yields naturally lower accuracy compared to high cost state of the art methods. In this work, we focus on a refinement of the road segmentation utilising a Conditional Random Field (CRF).The refinement procedure is limited to the super pixels touching the predicted road boundary to keep the additional computational effort low. Reducing the input to the super pixel domain allows the CNNs structure to stay small and efficient to compute while keeping the advantage of convolutional layers and makes them eligible for ADAS. Applying CRF compensate the trade off between accuracy and computational efficiency. The proposed system obtained comparable performance among the top performing algorithms on the KITTI road benchmark and its fast inference makes it particularly suitable for realtime applications.
CHAOS Challenge -- Combined (CT-MR) Healthy Abdominal Organ Segmentation
Jan 17, 2020
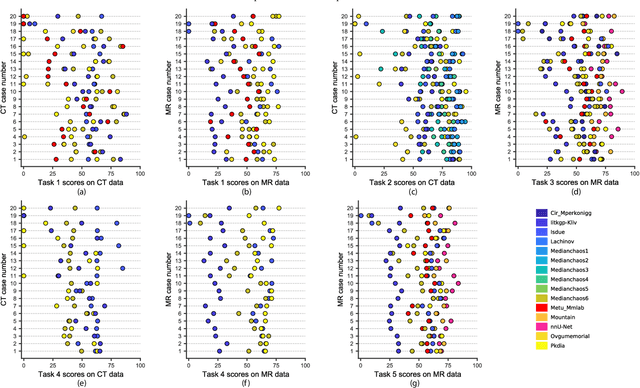
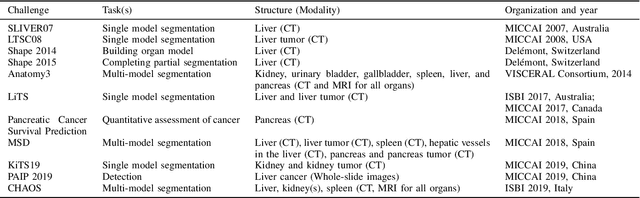
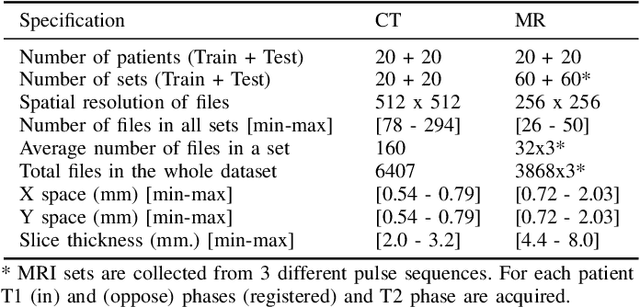
Segmentation of abdominal organs has been a comprehensive, yet unresolved, research field for many years. In the last decade, intensive developments in deep learning (DL) have introduced new state-of-the-art segmentation systems. Despite outperforming the overall accuracy of existing systems, the effects of DL model properties and parameters on the performance is hard to interpret. This makes comparative analysis a necessary tool to achieve explainable studies and systems. Moreover, the performance of DL for emerging learning approaches such as cross-modality and multi-modal tasks have been rarely discussed. In order to expand the knowledge in these topics, CHAOS -- Combined (CT-MR) Healthy Abdominal Organ Segmentation challenge has been organized in the IEEE International Symposium on Biomedical Imaging (ISBI), 2019, in Venice, Italy. Despite a large number of the previous abdomen related challenges, the majority of which are focused on tumor/lesion detection and/or classification with a single modality, CHAOS provides both abdominal CT and MR data from healthy subjects. Five different and complementary tasks have been designed to analyze the capabilities of the current approaches from multiple perspectives. The results are investigated thoroughly, compared with manual annotations and interactive methods. The outcomes are reported in detail to reflect the latest advancements in the field. CHAOS challenge and data will be available online to provide a continuous benchmark resource for segmentation.
Deep Learning with Anatomical Priors: Imitating Enhanced Autoencoders in Latent Space for Improved Pelvic Bone Segmentation in MRI
Mar 21, 2019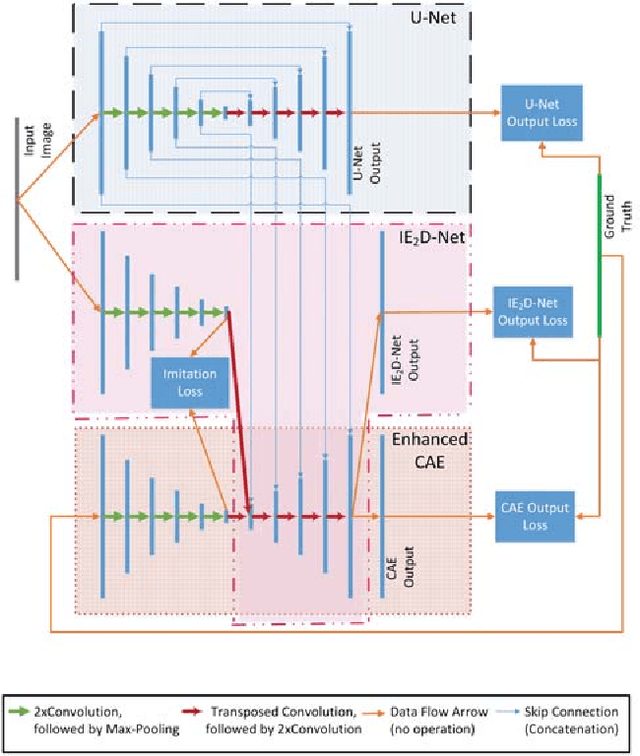
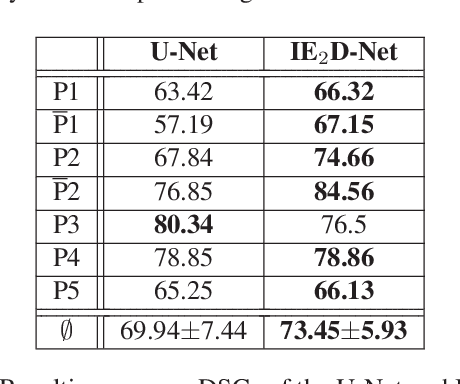
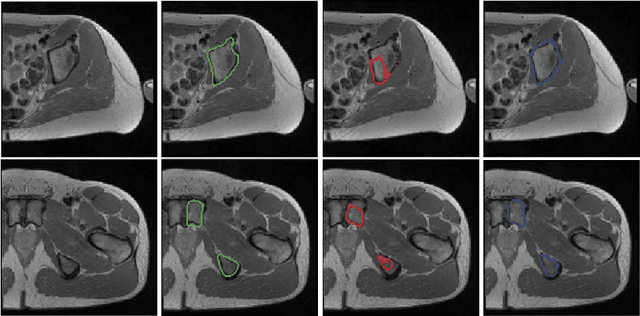
We propose a 2D Encoder-Decoder based deep learning architecture for semantic segmentation, that incorporates anatomical priors by imitating the encoder component of an autoencoder in latent space. The autoencoder is additionally enhanced by means of hierarchical features, extracted by an U-Net module. Our suggested architecture is trained in an end-to-end manner and is evaluated on the example of pelvic bone segmentation in MRI. A comparison to the standard U-Net architecture shows promising improvements.
Online Vision- and Action-Based Object Classification Using Both Symbolic and Subsymbolic Knowledge Representations
Oct 02, 2015
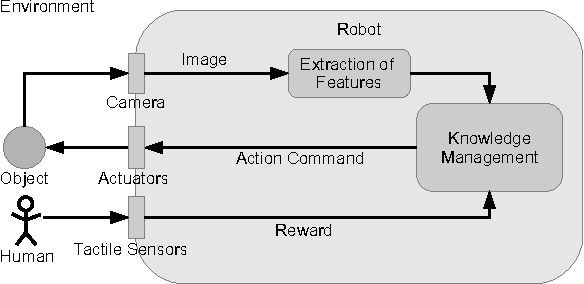


If a robot is supposed to roam an environment and interact with objects, it is often necessary to know all possible objects in advance, so that a database with models of all objects can be generated for visual identification. However, this constraint cannot always be fulfilled. Due to that reason, a model based object recognition cannot be used to guide the robot's interactions. Therefore, this paper proposes a system that analyzes features of encountered objects and then uses these features to compare unknown objects to already known ones. From the resulting similarity appropriate actions can be derived. Moreover, the system enables the robot to learn object categories by grouping similar objects or by splitting existing categories. To represent the knowledge a hybrid form is used, consisting of both symbolic and subsymbolic representations.