 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCM1 -- A Dataset for Evaluating Few-Shot Information Extraction with Large Vision Language Models
May 07, 2025The automatic extraction of key-value information from handwritten documents is a key challenge in document analysis. A reliable extraction is a prerequisite for the mass digitization efforts of many archives. Large Vision Language Models (LVLM) are a promising technology to tackle this problem especially in scenarios where little annotated training data is available. In this work, we present a novel dataset specifically designed to evaluate the few-shot capabilities of LVLMs. The CM1 documents are a historic collection of forms with handwritten entries created in Europe to administer the Care and Maintenance program after World War Two. The dataset establishes three benchmarks on extracting name and birthdate information and, furthermore, considers different training set sizes. We provide baseline results for two different LVLMs and compare performances to an established full-page extraction model. While the traditional full-page model achieves highly competitive performances, our experiments show that when only a few training samples are available the considered LVLMs benefit from their size and heavy pretraining and outperform the classical approach.
Multi-Channel Time-Series Person and Soft-Biometric Identification
Apr 04, 2023Multi-channel time-series datasets are popular in the context of human activity recognition (HAR). On-body device (OBD) recordings of human movements are often preferred for HAR applications not only for their reliability but as an approach for identity protection, e.g., in industrial settings. Contradictory, the gait activity is a biometric, as the cyclic movement is distinctive and collectable. In addition, the gait cycle has proven to contain soft-biometric information of human groups, such as age and height. Though general human movements have not been considered a biometric, they might contain identity information. This work investigates person and soft-biometrics identification from OBD recordings of humans performing different activities using deep architectures. Furthermore, we propose the use of attribute representation for soft-biometric identification. We evaluate the method on four datasets of multi-channel time-series HAR, measuring the performance of a person and soft-biometrics identification and its relation concerning performed activities. We find that person identification is not limited to gait activity. The impact of activities on the identification performance was found to be training and dataset specific. Soft-biometric based attribute representation shows promising results and emphasis the necessity of larger datasets.
Dataset Bias in Human Activity Recognition
Jan 19, 2023



When creating multi-channel time-series datasets for Human Activity Recognition (HAR), researchers are faced with the issue of subject selection criteria. It is unknown what physical characteristics and/or soft-biometrics, such as age, height, and weight, need to be taken into account to train a classifier to achieve robustness towards heterogeneous populations in the training and testing data. This contribution statistically curates the training data to assess to what degree the physical characteristics of humans influence HAR performance. We evaluate the performance of a state-of-the-art convolutional neural network on two HAR datasets that vary in the sensors, activities, and recording for time-series HAR. The training data is intentionally biased with respect to human characteristics to determine the features that impact motion behaviour. The evaluations brought forth the impact of the subjects' characteristics on HAR. Thus, providing insights regarding the robustness of the classifier with respect to heterogeneous populations. The study is a step forward in the direction of fair and trustworthy artificial intelligence by attempting to quantify representation bias in multi-channel time series HAR data.
Video-based Pose-Estimation Data as Source for Transfer Learning in Human Activity Recognition
Dec 02, 2022



Human Activity Recognition (HAR) using on-body devices identifies specific human actions in unconstrained environments. HAR is challenging due to the inter and intra-variance of human movements; moreover, annotated datasets from on-body devices are scarce. This problem is mainly due to the difficulty of data creation, i.e., recording, expensive annotation, and lack of standard definitions of human activities. Previous works demonstrated that transfer learning is a good strategy for addressing scenarios with scarce data. However, the scarcity of annotated on-body device datasets remains. This paper proposes using datasets intended for human-pose estimation as a source for transfer learning; specifically, it deploys sequences of annotated pixel coordinates of human joints from video datasets for HAR and human pose estimation. We pre-train a deep architecture on four benchmark video-based source datasets. Finally, an evaluation is carried out on three on-body device datasets improving HAR performance.
Self-Training of Handwritten Word Recognition for Synthetic-to-Real Adaptation
Jun 07, 2022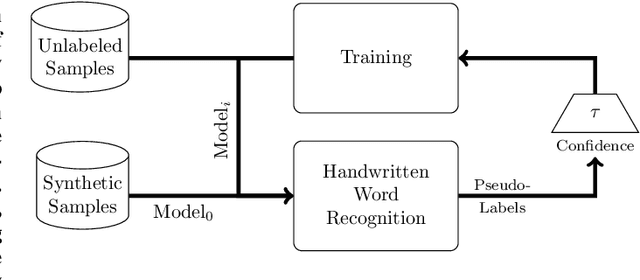
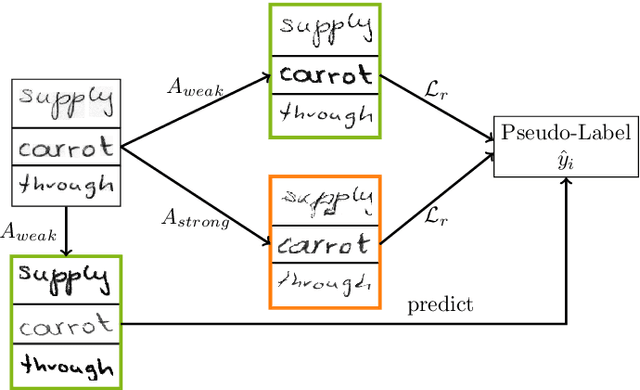

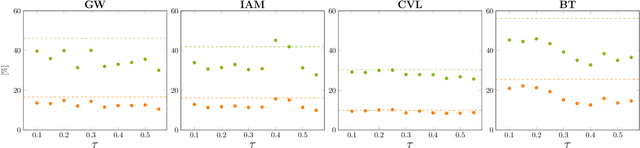
Performances of Handwritten Text Recognition (HTR) models are largely determined by the availability of labeled and representative training samples. However, in many application scenarios labeled samples are scarce or costly to obtain. In this work, we propose a self-training approach to train a HTR model solely on synthetic samples and unlabeled data. The proposed training scheme uses an initial model trained on synthetic data to make predictions for the unlabeled target dataset. Starting from this initial model with rather poor performance, we show that a considerable adaptation is possible by training against the predicted pseudo-labels. Moreover, the investigated self-training strategy does not require any manually annotated training samples. We evaluate the proposed method on four widely used benchmark datasets and show its effectiveness on closing the gap to a model trained in a fully-supervised manner.
Recognition-free Question Answering on Handwritten Document Collections
Feb 12, 2022In recent years, considerable progress has been made in the research area of Question Answering (QA) on document images. Current QA approaches from the Document Image Analysis community are mainly focusing on machine-printed documents and perform rather limited on handwriting. This is mainly due to the reduced recognition performance on handwritten documents. To tackle this problem, we propose a recognition-free QA approach, especially designed for handwritten document image collections. We present a robust document retrieval method, as well as two QA models. Our approaches outperform the state-of-the-art recognition-free models on the challenging BenthamQA and HW-SQuAD datasets.
UQGAN: A Unified Model for Uncertainty Quantification of Deep Classifiers trained via Conditional GANs
Jan 31, 2022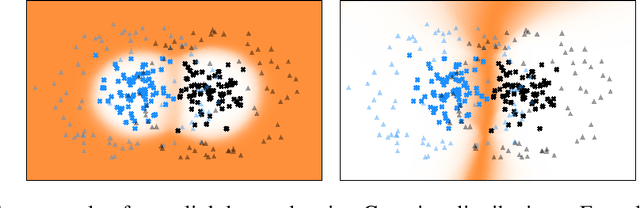
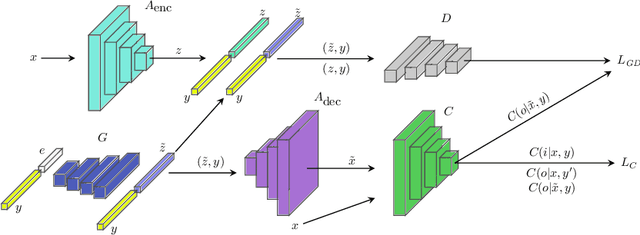
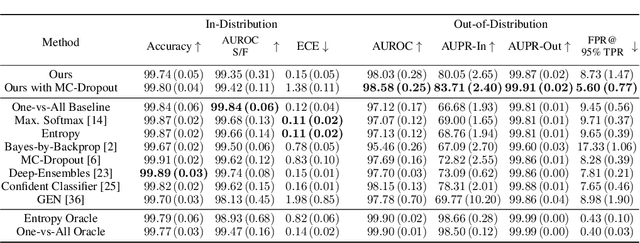

We present an approach to quantifying both aleatoric and epistemic uncertainty for deep neural networks in image classification, based on generative adversarial networks (GANs). While most works in the literature that use GANs to generate out-of-distribution (OoD) examples only focus on the evaluation of OoD detection, we present a GAN based approach to learn a classifier that exhibits proper uncertainties for OoD examples as well as for false positives (FPs). Instead of shielding the entire in-distribution data with GAN generated OoD examples which is state-of-the-art, we shield each class separately with out-of-class examples generated by a conditional GAN and complement this with a one-vs-all image classifier. In our experiments, in particular on CIFAR10, we improve over the OoD detection and FP detection performance of state-of-the-art GAN-training based classifiers. Furthermore, we also find that the generated GAN examples do not significantly affect the calibration error of our classifier and result in a significant gain in model accuracy.
Human Activity Recognition using Attribute-Based Neural Networks and Context Information
Oct 28, 2021
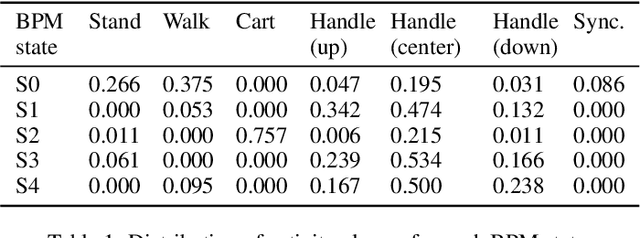
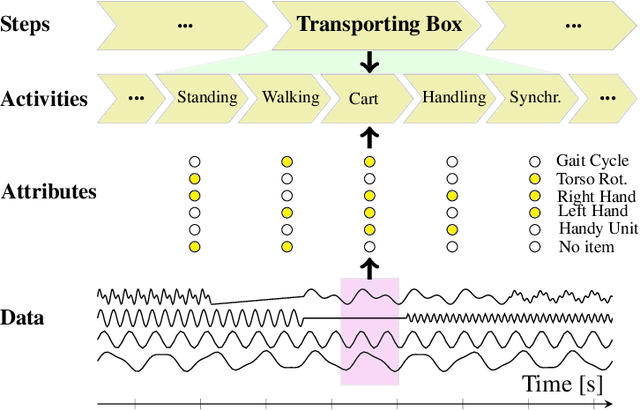
We consider human activity recognition (HAR) from wearable sensor data in manual-work processes, like warehouse order-picking. Such structured domains can often be partitioned into distinct process steps, e.g., packaging or transporting. Each process step can have a different prior distribution over activity classes, e.g., standing or walking, and different system dynamics. Here, we show how such context information can be integrated systematically into a deep neural network-based HAR system. Specifically, we propose a hybrid architecture that combines a deep neural network-that estimates high-level movement descriptors, attributes, from the raw-sensor data-and a shallow classifier, which predicts activity classes from the estimated attributes and (optional) context information, like the currently executed process step. We empirically show that our proposed architecture increases HAR performance, compared to state-of-the-art methods. Additionally, we show that HAR performance can be further increased when information about process steps is incorporated, even when that information is only partially correct.
Detection and Retrieval of Out-of-Distribution Objects in Semantic Segmentation
May 14, 2020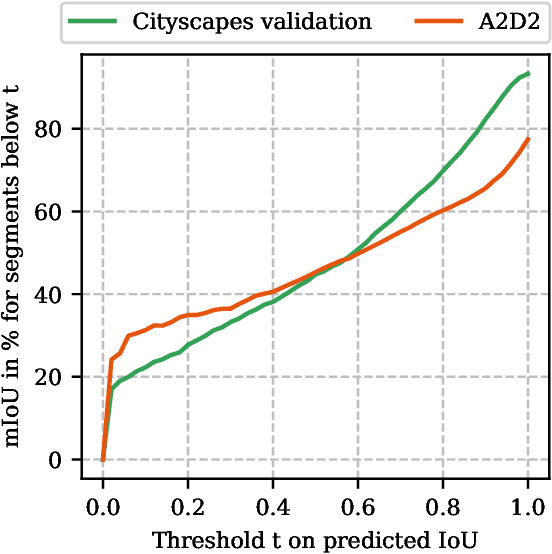


When deploying deep learning technology in self-driving cars, deep neural networks are constantly exposed to domain shifts. These include, e.g., changes in weather conditions, time of day, and long-term temporal shift. In this work we utilize a deep neural network trained on the Cityscapes dataset containing urban street scenes and infer images from a different dataset, the A2D2 dataset, containing also countryside and highway images. We present a novel pipeline for semantic segmenation that detects out-of-distribution (OOD) segments by means of the deep neural network's prediction and performs image retrieval after feature extraction and dimensionality reduction on image patches. In our experiments we demonstrate that the deployed OOD approach is suitable for detecting out-of-distribution concepts. Furthermore, we evaluate the image patch retrieval qualitatively as well as quantitatively by means of the semi-compatible A2D2 ground truth and obtain mAP values of up to 52.2%.
Annotation-free Learning of Deep Representations for Word Spotting using Synthetic Data and Self Labeling
Apr 09, 2020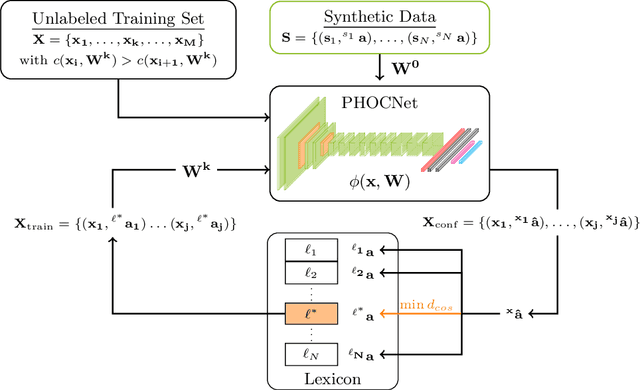
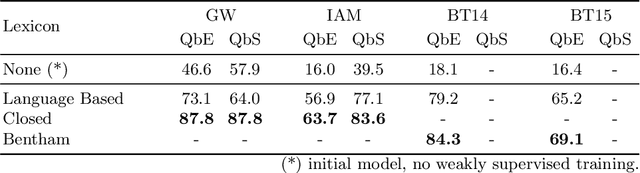
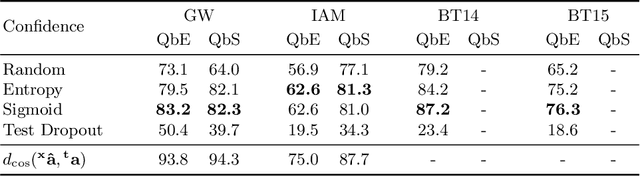
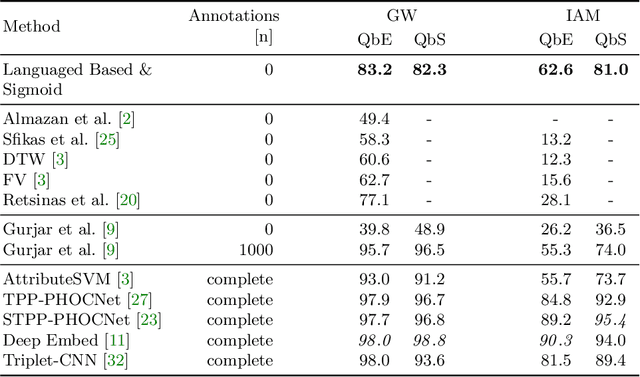
Word spotting is a popular tool for supporting the first exploration of historic, handwritten document collections. Today, the best performing methods rely on machine learning techniques, which require a high amount of annotated training material. As training data is usually not available in the application scenario, annotation-free methods aim at solving the retrieval task without representative training samples. In this work, we present an annotation-free method that still employs machine learning techniques and therefore outperforms other learning-free approaches. The weakly supervised training scheme relies on a lexicon, that does not need to precisely fit the dataset. In combination with a confidence based selection of pseudo-labeled training samples, we achieve state-of-the-art query-by-example performances. Furthermore, our method allows to perform query-by-string, which is usually not the case for other annotation-free methods.