 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUQGAN: A Unified Model for Uncertainty Quantification of Deep Classifiers trained via Conditional GANs
Jan 31, 2022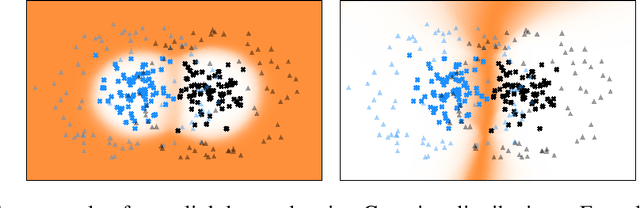
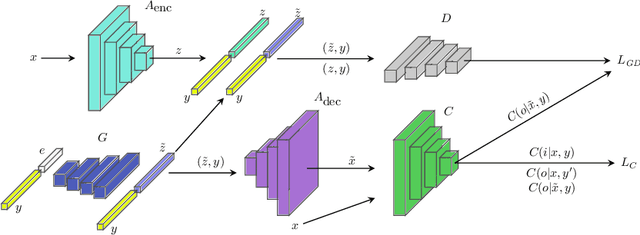
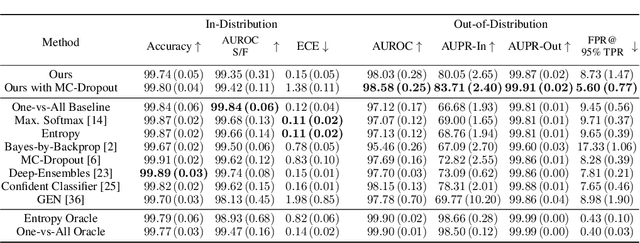

We present an approach to quantifying both aleatoric and epistemic uncertainty for deep neural networks in image classification, based on generative adversarial networks (GANs). While most works in the literature that use GANs to generate out-of-distribution (OoD) examples only focus on the evaluation of OoD detection, we present a GAN based approach to learn a classifier that exhibits proper uncertainties for OoD examples as well as for false positives (FPs). Instead of shielding the entire in-distribution data with GAN generated OoD examples which is state-of-the-art, we shield each class separately with out-of-class examples generated by a conditional GAN and complement this with a one-vs-all image classifier. In our experiments, in particular on CIFAR10, we improve over the OoD detection and FP detection performance of state-of-the-art GAN-training based classifiers. Furthermore, we also find that the generated GAN examples do not significantly affect the calibration error of our classifier and result in a significant gain in model accuracy.
Detection and Retrieval of Out-of-Distribution Objects in Semantic Segmentation
May 14, 2020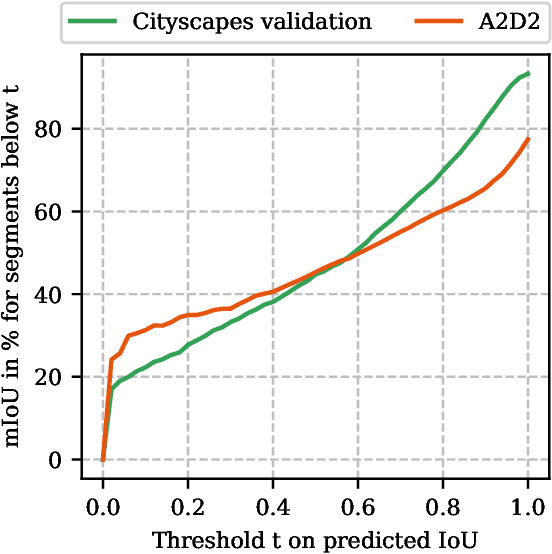


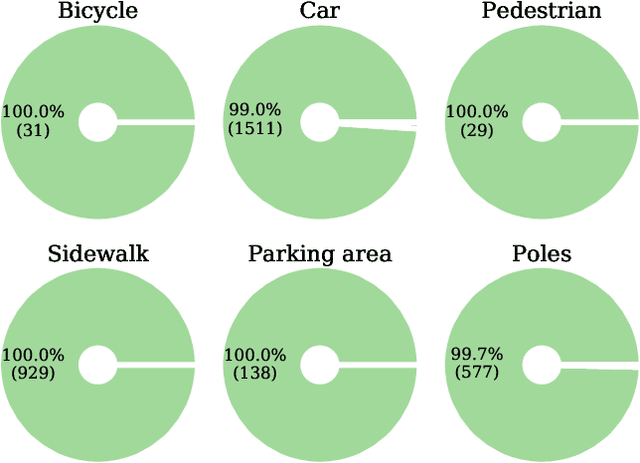
When deploying deep learning technology in self-driving cars, deep neural networks are constantly exposed to domain shifts. These include, e.g., changes in weather conditions, time of day, and long-term temporal shift. In this work we utilize a deep neural network trained on the Cityscapes dataset containing urban street scenes and infer images from a different dataset, the A2D2 dataset, containing also countryside and highway images. We present a novel pipeline for semantic segmenation that detects out-of-distribution (OOD) segments by means of the deep neural network's prediction and performs image retrieval after feature extraction and dimensionality reduction on image patches. In our experiments we demonstrate that the deployed OOD approach is suitable for detecting out-of-distribution concepts. Furthermore, we evaluate the image patch retrieval qualitatively as well as quantitatively by means of the semi-compatible A2D2 ground truth and obtain mAP values of up to 52.2%.
Exploring Confidence Measures for Word Spotting in Heterogeneous Datasets
Mar 26, 2019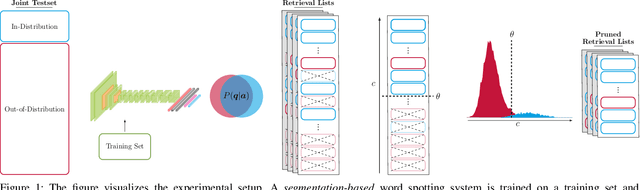
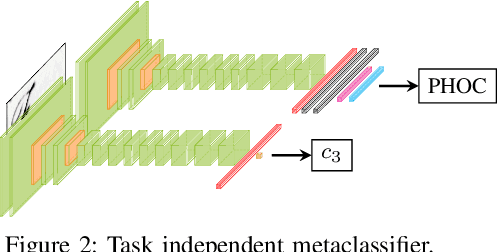
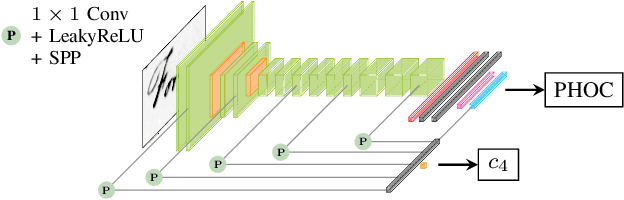
In recent years, convolutional neural networks (CNNs) took over the field of document analysis and they became the predominant model for word spotting. Especially attribute CNNs, which learn the mapping between a word image and an attribute representation, showed exceptional performances. The drawback of this approach is the overconfidence of neural networks when used out of their training distribution. In this paper, we explore different metrics for quantifying the confidence of a CNN in its predictions, specifically on the retrieval problem of word spotting. With these confidence measures, we limit the inability of a retrieval list to reject certain candidates. We investigate four different approaches that are either based on the network's attribute estimations or make use of a surrogate model. Our approach also aims at answering the question for which part of a dataset the retrieval system gives reliable results. We further show that there exists a direct relation between the proposed confidence measures and the quality of an estimated attribute representation.
Classification Uncertainty of Deep Neural Networks Based on Gradient Information
Jul 26, 2018
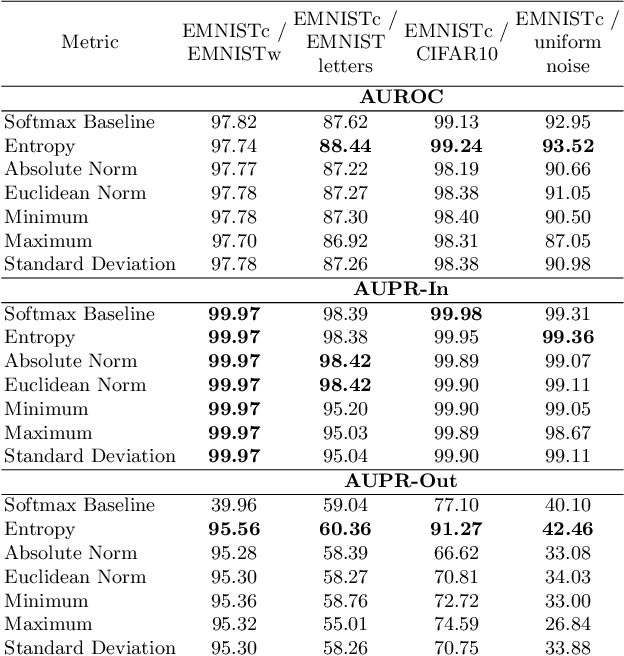

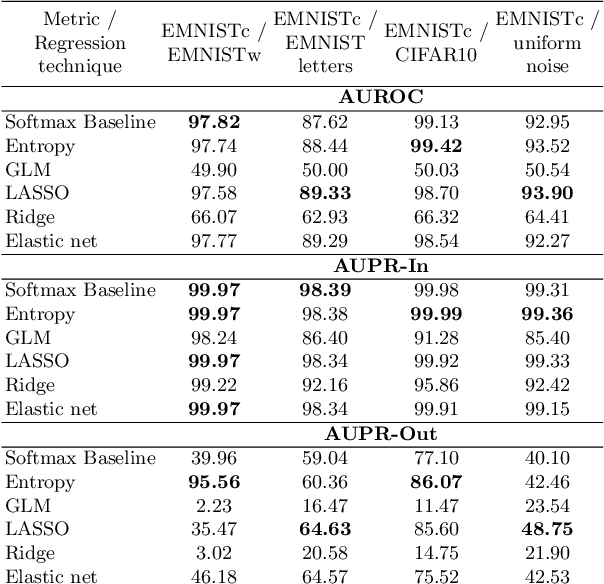
We study the quantification of uncertainty of Convolutional Neural Networks (CNNs) based on gradient metrics. Unlike the classical softmax entropy, such metrics gather information from all layers of the CNN. We show for the EMNIST digits data set that for several such metrics we achieve the same meta classification accuracy -- i.e. the task of classifying predictions as correct or incorrect without knowing the actual label -- as for entropy thresholding. We apply meta classification to unknown concepts (out-of-distribution samples) -- EMNIST/Omniglot letters, CIFAR10 and noise -- and demonstrate that meta classification rates for unknown concepts can be increased when using entropy together with several gradient based metrics as input quantities for a meta classifier. Meta classifiers only trained on the uncertainty metrics of known concepts, i.e. EMNIST digits, usually do not perform equally well for all unknown concepts. If we however allow the meta classifier to be trained on uncertainty metrics for some out-of-distribution samples, meta classification for concepts remote from EMNIST digits (then termed known unknowns) can be improved considerably.