 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytical Uncertainty-Based Loss Weighting in Multi-Task Learning
Aug 15, 2024With the rise of neural networks in various domains, multi-task learning (MTL) gained significant relevance. A key challenge in MTL is balancing individual task losses during neural network training to improve performance and efficiency through knowledge sharing across tasks. To address these challenges, we propose a novel task-weighting method by building on the most prevalent approach of Uncertainty Weighting and computing analytically optimal uncertainty-based weights, normalized by a softmax function with tunable temperature. Our approach yields comparable results to the combinatorially prohibitive, brute-force approach of Scalarization while offering a more cost-effective yet high-performing alternative. We conduct an extensive benchmark on various datasets and architectures. Our method consistently outperforms six other common weighting methods. Furthermore, we report noteworthy experimental findings for the practical application of MTL. For example, larger networks diminish the influence of weighting methods, and tuning the weight decay has a low impact compared to the learning rate.
Challenging Common Assumptions in Multi-task Learning
Nov 10, 2023While multi-task learning (MTL) has gained significant attention in recent years, its underlying mechanisms remain poorly understood. Recent methods did not yield consistent performance improvements over single task learning (STL) baselines, underscoring the importance of gaining more profound insights about challenges specific to MTL. In our study, we challenge common assumptions in MTL in the context of STL: First, the choice of optimizer has only been mildly investigated in MTL. We show the pivotal role of common STL tools such as the Adam optimizer in MTL. We deduce the effectiveness of Adam to its partial loss-scale invariance. Second, the notion of gradient conflicts has often been phrased as a specific problem in MTL. We delve into the role of gradient conflicts in MTL and compare it to STL. For angular gradient alignment we find no evidence that this is a unique problem in MTL. We emphasize differences in gradient magnitude as the main distinguishing factor. Lastly, we compare the transferability of features learned through MTL and STL on common image corruptions, and find no conclusive evidence that MTL leads to superior transferability. Overall, we find surprising similarities between STL and MTL suggesting to consider methods from both fields in a broader context.
Weakly-supervised localization of diabetic retinopathy lesions in retinal fundus images
Jun 29, 2017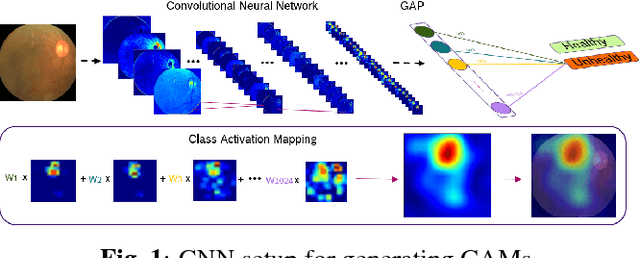

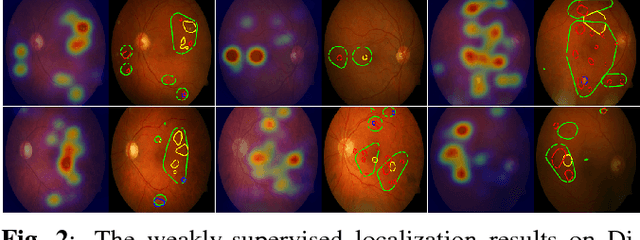

Convolutional neural networks (CNNs) show impressive performance for image classification and detection, extending heavily to the medical image domain. Nevertheless, medical experts are sceptical in these predictions as the nonlinear multilayer structure resulting in a classification outcome is not directly graspable. Recently, approaches have been shown which help the user to understand the discriminative regions within an image which are decisive for the CNN to conclude to a certain class. Although these approaches could help to build trust in the CNNs predictions, they are only slightly shown to work with medical image data which often poses a challenge as the decision for a class relies on different lesion areas scattered around the entire image. Using the DiaretDB1 dataset, we show that on retina images different lesion areas fundamental for diabetic retinopathy are detected on an image level with high accuracy, comparable or exceeding supervised methods. On lesion level, we achieve few false positives with high sensitivity, though, the network is solely trained on image-level labels which do not include information about existing lesions. Classifying between diseased and healthy images, we achieve an AUC of 0.954 on the DiaretDB1.