 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytical Uncertainty-Based Loss Weighting in Multi-Task Learning
Aug 15, 2024With the rise of neural networks in various domains, multi-task learning (MTL) gained significant relevance. A key challenge in MTL is balancing individual task losses during neural network training to improve performance and efficiency through knowledge sharing across tasks. To address these challenges, we propose a novel task-weighting method by building on the most prevalent approach of Uncertainty Weighting and computing analytically optimal uncertainty-based weights, normalized by a softmax function with tunable temperature. Our approach yields comparable results to the combinatorially prohibitive, brute-force approach of Scalarization while offering a more cost-effective yet high-performing alternative. We conduct an extensive benchmark on various datasets and architectures. Our method consistently outperforms six other common weighting methods. Furthermore, we report noteworthy experimental findings for the practical application of MTL. For example, larger networks diminish the influence of weighting methods, and tuning the weight decay has a low impact compared to the learning rate.
Challenging Common Assumptions in Multi-task Learning
Nov 10, 2023While multi-task learning (MTL) has gained significant attention in recent years, its underlying mechanisms remain poorly understood. Recent methods did not yield consistent performance improvements over single task learning (STL) baselines, underscoring the importance of gaining more profound insights about challenges specific to MTL. In our study, we challenge common assumptions in MTL in the context of STL: First, the choice of optimizer has only been mildly investigated in MTL. We show the pivotal role of common STL tools such as the Adam optimizer in MTL. We deduce the effectiveness of Adam to its partial loss-scale invariance. Second, the notion of gradient conflicts has often been phrased as a specific problem in MTL. We delve into the role of gradient conflicts in MTL and compare it to STL. For angular gradient alignment we find no evidence that this is a unique problem in MTL. We emphasize differences in gradient magnitude as the main distinguishing factor. Lastly, we compare the transferability of features learned through MTL and STL on common image corruptions, and find no conclusive evidence that MTL leads to superior transferability. Overall, we find surprising similarities between STL and MTL suggesting to consider methods from both fields in a broader context.
Learning-based Relational Object Matching Across Views
May 03, 2023



Intelligent robots require object-level scene understanding to reason about possible tasks and interactions with the environment. Moreover, many perception tasks such as scene reconstruction, image retrieval, or place recognition can benefit from reasoning on the level of objects. While keypoint-based matching can yield strong results for finding correspondences for images with small to medium view point changes, for large view point changes, matching semantically on the object-level becomes advantageous. In this paper, we propose a learning-based approach which combines local keypoints with novel object-level features for matching object detections between RGB images. We train our object-level matching features based on appearance and inter-frame and cross-frame spatial relations between objects in an associative graph neural network. We demonstrate our approach in a large variety of views on realistically rendered synthetic images. Our approach compares favorably to previous state-of-the-art object-level matching approaches and achieves improved performance over a pure keypoint-based approach for large view-point changes.
Semi-Supervised Learning of Multi-Object 3D Scene Representations
Oct 08, 2020
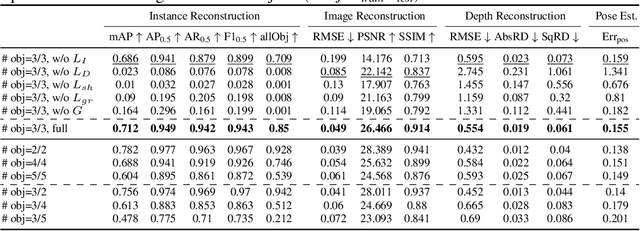
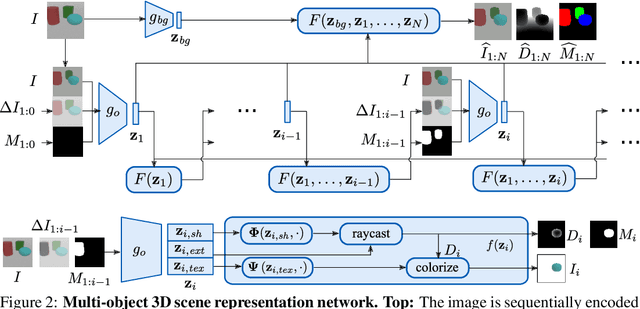
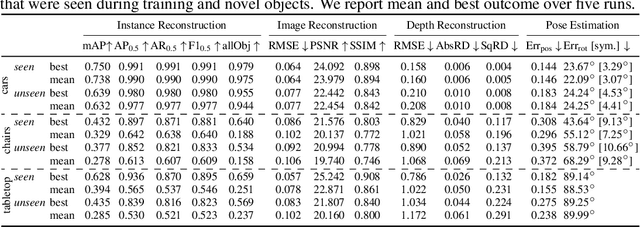
Representing scenes at the granularity of objects is a prerequisite for scene understanding and decision making. We propose a novel approach for learning multi-object 3D scene representations from images. A recurrent encoder regresses a latent representation of 3D shapes, poses and texture of each object from an input RGB image. The 3D shapes are represented continuously in function-space as signed distance functions (SDF) which we efficiently pre-train from example shapes in a supervised way. By differentiable rendering we then train our model to decompose scenes self-supervised from RGB-D images. Our approach learns to decompose images into the constituent objects of the scene and to infer their shape, pose and texture from a single view. We evaluate the accuracy of our model in inferring the 3D scene layout and demonstrate its generative capabilities.
3D-BEVIS: Birds-Eye-View Instance Segmentation
May 17, 2019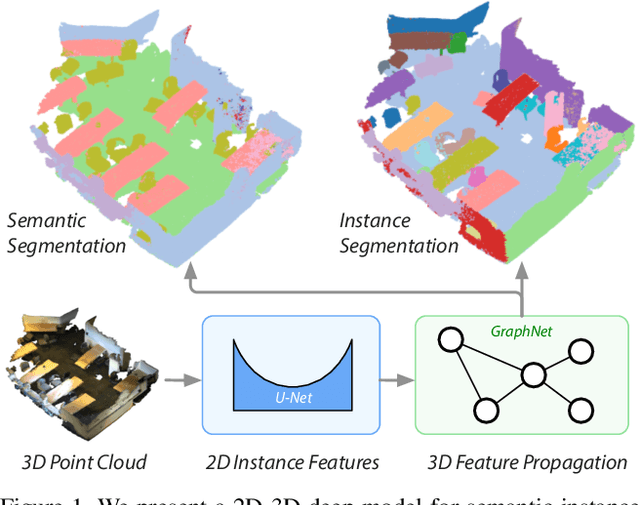
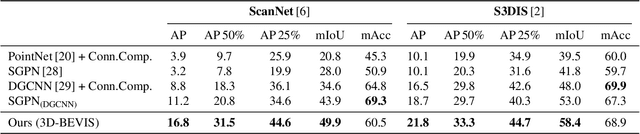

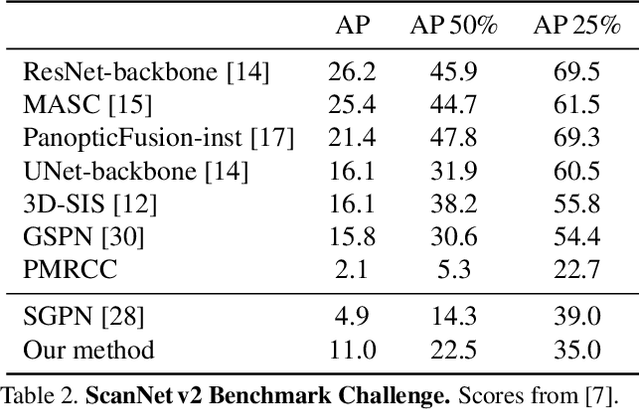
Recent deep learning models achieve impressive results on 3D scene analysis tasks by operating directly on unstructured point clouds. A lot of progress was made in the field of object classification and semantic segmentation. However, the task of instance segmentation is less explored. In this work, we present 3D-BEVIS, a deep learning framework for 3D semantic instance segmentation on point clouds. Following the idea of previous proposal-free instance segmentation approaches, our model learns a feature embedding and groups the obtained feature space into semantic instances. Current point-based methods scale linearly with the number of points by processing local sub-parts of a scene individually. However, to perform instance segmentation by clustering, globally consistent features are required. Therefore, we propose to combine local point geometry with global context information from an intermediate bird's-eye view representation.