 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeed for Speed: Zero-Shot Depth Completion with Single-Step Diffusion
Mar 11, 2026We introduce Marigold-SSD, a single-step, late-fusion depth completion framework that leverages strong diffusion priors while eliminating the costly test-time optimization typically associated with diffusion-based methods. By shifting computational burden from inference to finetuning, our approach enables efficient and robust 3D perception under real-world latency constraints. Marigold-SSD achieves significantly faster inference with a training cost of only 4.5 GPU days. We evaluate our method across four indoor and two outdoor benchmarks, demonstrating strong cross-domain generalization and zero-shot performance compared to existing depth completion approaches. Our approach significantly narrows the efficiency gap between diffusion-based and discriminative models. Finally, we challenge common evaluation protocols by analyzing performance under varying input sparsity levels. Page: https://dtu-pas.github.io/marigold-ssd/
Interactive4D: Interactive 4D LiDAR Segmentation
Oct 10, 2024



Interactive segmentation has an important role in facilitating the annotation process of future LiDAR datasets. Existing approaches sequentially segment individual objects at each LiDAR scan, repeating the process throughout the entire sequence, which is redundant and ineffective. In this work, we propose interactive 4D segmentation, a new paradigm that allows segmenting multiple objects on multiple LiDAR scans simultaneously, and Interactive4D, the first interactive 4D segmentation model that segments multiple objects on superimposed consecutive LiDAR scans in a single iteration by utilizing the sequential nature of LiDAR data. While performing interactive segmentation, our model leverages the entire space-time volume, leading to more efficient segmentation. Operating on the 4D volume, it directly provides consistent instance IDs over time and also simplifies tracking annotations. Moreover, we show that click simulations are crucial for successful model training on LiDAR point clouds. To this end, we design a click simulation strategy that is better suited for the characteristics of LiDAR data. To demonstrate its accuracy and effectiveness, we evaluate Interactive4D on multiple LiDAR datasets, where Interactive4D achieves a new state-of-the-art by a large margin. Upon acceptance, we will publicly release the code and models at https://vision.rwth-aachen.de/Interactive4D.
Is Continual Learning Ready for Real-world Challenges?
Feb 15, 2024Despite continual learning's long and well-established academic history, its application in real-world scenarios remains rather limited. This paper contends that this gap is attributable to a misalignment between the actual challenges of continual learning and the evaluation protocols in use, rendering proposed solutions ineffective for addressing the complexities of real-world setups. We validate our hypothesis and assess progress to date, using a new 3D semantic segmentation benchmark, OCL-3DSS. We investigate various continual learning schemes from the literature by utilizing more realistic protocols that necessitate online and continual learning for dynamic, real-world scenarios (eg., in robotics and 3D vision applications). The outcomes are sobering: all considered methods perform poorly, significantly deviating from the upper bound of joint offline training. This raises questions about the applicability of existing methods in realistic settings. Our paper aims to initiate a paradigm shift, advocating for the adoption of continual learning methods through new experimental protocols that better emulate real-world conditions to facilitate breakthroughs in the field.
Automated forest inventory: analysis of high-density airborne LiDAR point clouds with 3D deep learning
Dec 22, 2023



Detailed forest inventories are critical for sustainable and flexible management of forest resources, to conserve various ecosystem services. Modern airborne laser scanners deliver high-density point clouds with great potential for fine-scale forest inventory and analysis, but automatically partitioning those point clouds into meaningful entities like individual trees or tree components remains a challenge. The present study aims to fill this gap and introduces a deep learning framework that is able to perform such a segmentation across diverse forest types and geographic regions. From the segmented data, we then derive relevant biophysical parameters of individual trees as well as stands. The system has been tested on FOR-Instance, a dataset of point clouds that have been acquired in five different countries using surveying drones. The segmentation back-end achieves over 85% F-score for individual trees, respectively over 73% mean IoU across five semantic categories: ground, low vegetation, stems, live branches and dead branches. Building on the segmentation results our pipeline then densely calculates biophysical features of each individual tree (height, crown diameter, crown volume, DBH, and location) and properties per stand (digital terrain model and stand density). Especially crown-related features are in most cases retrieved with high accuracy, whereas the estimates for DBH and location are less reliable, due to the airborne scanning setup.
Towards accurate instance segmentation in large-scale LiDAR point clouds
Jul 06, 2023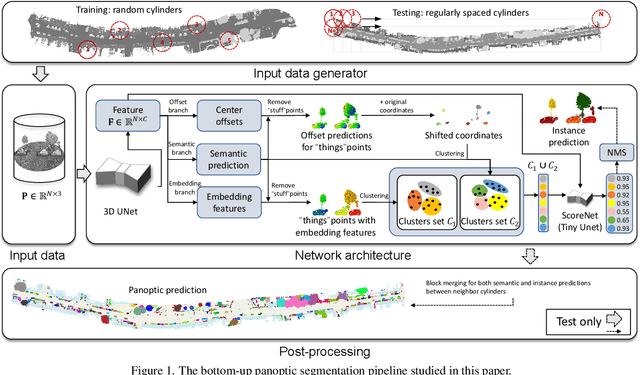
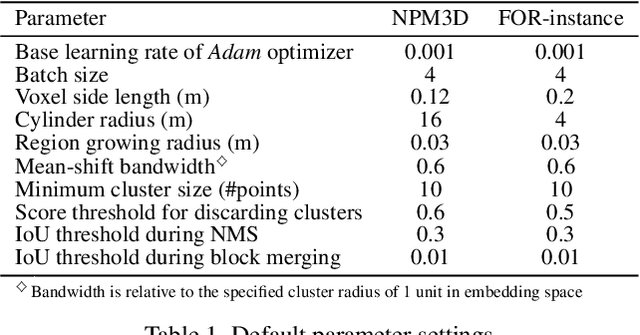
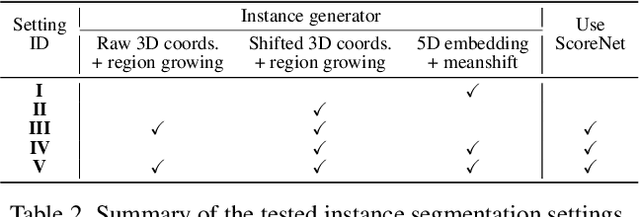
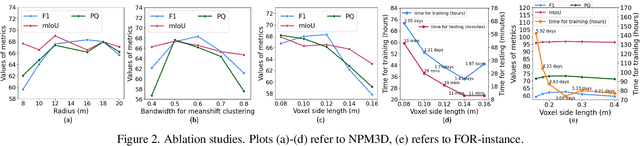
Panoptic segmentation is the combination of semantic and instance segmentation: assign the points in a 3D point cloud to semantic categories and partition them into distinct object instances. It has many obvious applications for outdoor scene understanding, from city mapping to forest management. Existing methods struggle to segment nearby instances of the same semantic category, like adjacent pieces of street furniture or neighbouring trees, which limits their usability for inventory- or management-type applications that rely on object instances. This study explores the steps of the panoptic segmentation pipeline concerned with clustering points into object instances, with the goal to alleviate that bottleneck. We find that a carefully designed clustering strategy, which leverages multiple types of learned point embeddings, significantly improves instance segmentation. Experiments on the NPM3D urban mobile mapping dataset and the FOR-instance forest dataset demonstrate the effectiveness and versatility of the proposed strategy.
AGILE3D: Attention Guided Interactive Multi-object 3D Segmentation
Jun 01, 2023



During interactive segmentation, a model and a user work together to delineate objects of interest in a 3D point cloud. In an iterative process, the model assigns each data point to an object (or the background), while the user corrects errors in the resulting segmentation and feeds them back into the model. From a machine learning perspective the goal is to design the model and the feedback mechanism in a way that minimizes the required user input. The current best practice segments objects one at a time, and asks the user to provide positive clicks to indicate regions wrongly assigned to the background and negative clicks to indicate regions wrongly assigned to the object (foreground). Sequentially visiting objects is wasteful, since it disregards synergies between objects: a positive click for a given object can, by definition, serve as a negative click for nearby objects, moreover a direct competition between adjacent objects can speed up the identification of their common boundary. We introduce AGILE3D, an efficient, attention-based model that (1) supports simultaneous segmentation of multiple 3D objects, (2) yields more accurate segmentation masks with fewer user clicks, and (3) offers faster inference. We encode the point cloud into a latent feature representation, and view user clicks as queries and employ cross-attention to represent contextual relations between different click locations as well as between clicks and the 3D point cloud features. Every time new clicks are added, we only need to run a lightweight decoder that produces updated segmentation masks. In experiments with four different point cloud datasets, AGILE3D sets a new state of the art, moreover, we also verify its practicality in real-world setups with a real user study.
Connecting the Dots: Floorplan Reconstruction Using Two-Level Queries
Nov 28, 2022



We address 2D floorplan reconstruction from 3D scans. Existing approaches typically employ heuristically designed multi-stage pipelines. Instead, we formulate floorplan reconstruction as a single-stage structured prediction task: find a variable-size set of polygons, which in turn are variable-length sequences of ordered vertices. To solve it we develop a novel Transformer architecture that generates polygons of multiple rooms in parallel, in a holistic manner without hand-crafted intermediate stages. The model features two-level queries for polygons and corners, and includes polygon matching to make the network end-to-end trainable. Our method achieves a new state-of-the-art for two challenging datasets, Structured3D and SceneCAD, along with significantly faster inference than previous methods. Moreover, it can readily be extended to predict additional information, i.e., semantic room types and architectural elements like doors and windows. Our code and models will be available at: https://github.com/ywyue/RoomFormer.
Interactive Object Segmentation in 3D Point Clouds
Apr 14, 2022
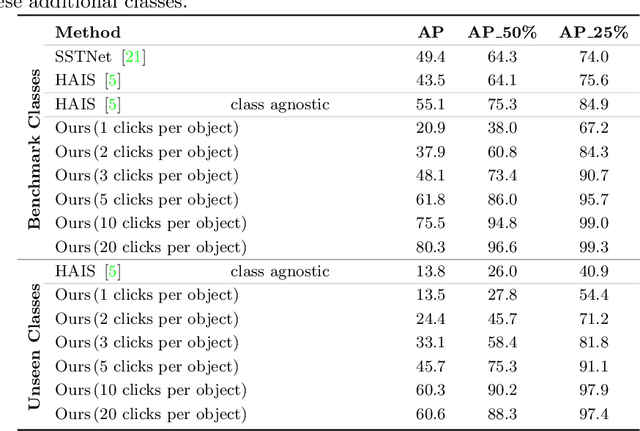

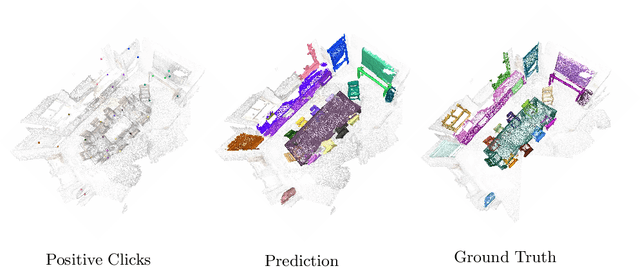
Deep learning depends on large amounts of labeled training data. Manual labeling is expensive and represents a bottleneck, especially for tasks such as segmentation, where labels must be assigned down to the level of individual points. That challenge is even more daunting for 3D data: 3D point clouds contain millions of points per scene, and their accurate annotation is markedly more time-consuming. The situation is further aggravated by the added complexity of user interfaces for 3D point clouds, which slows down annotation even more. For the case of 2D image segmentation, interactive techniques have become common, where user feedback in the form of a few clicks guides a segmentation algorithm -- nowadays usually a neural network -- to achieve an accurate labeling with minimal effort. Surprisingly, interactive segmentation of 3D scenes has not been explored much. Previous work has attempted to obtain accurate 3D segmentation masks using human feedback from the 2D domain, which is only possible if correctly aligned images are available together with the 3D point cloud, and it involves switching between the 2D and 3D domains. Here, we present an interactive 3D object segmentation method in which the user interacts directly with the 3D point cloud. Importantly, our model does not require training data from the target domain: when trained on ScanNet, it performs well on several other datasets with different data characteristics as well as different object classes. Moreover, our method is orthogonal to supervised (instance) segmentation methods and can be combined with them to refine automatic segmentations with minimal human effort.
DualConvMesh-Net: Joint Geodesic and Euclidean Convolutions on 3D Meshes
Apr 02, 2020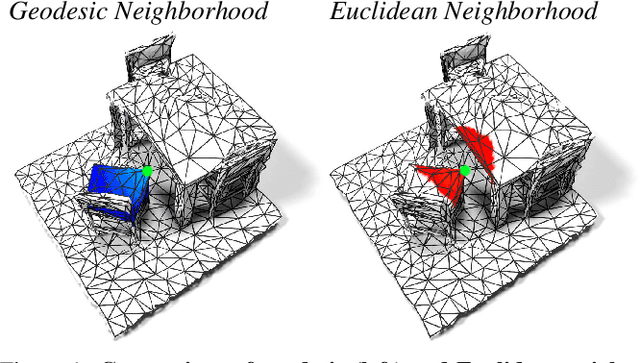
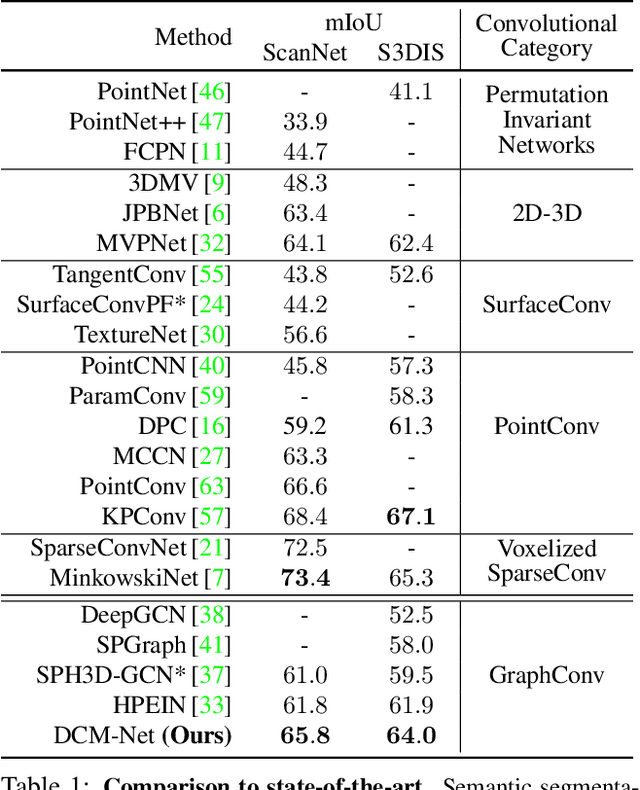
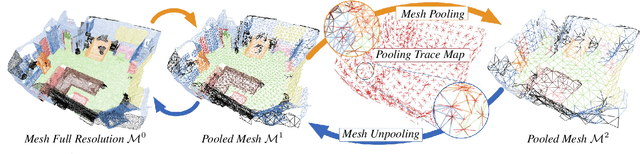
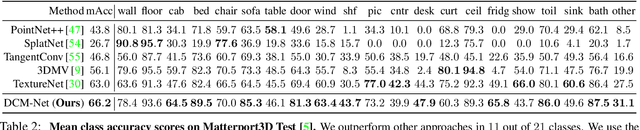
We propose DualConvMesh-Nets (DCM-Net) a family of deep hierarchical convolutional networks over 3D geometric data that combines two types of convolutions. The first type, geodesic convolutions, defines the kernel weights over mesh surfaces or graphs. That is, the convolutional kernel weights are mapped to the local surface of a given mesh. The second type, Euclidean convolutions, is independent of any underlying mesh structure. The convolutional kernel is applied on a neighborhood obtained from a local affinity representation based on the Euclidean distance between 3D points. Intuitively, geodesic convolutions can easily separate objects that are spatially close but have disconnected surfaces, while Euclidean convolutions can represent interactions between nearby objects better, as they are oblivious to object surfaces. To realize a multi-resolution architecture, we borrow well-established mesh simplification methods from the geometry processing domain and adapt them to define mesh-preserving pooling and unpooling operations. We experimentally show that combining both types of convolutions in our architecture leads to significant performance gains for 3D semantic segmentation, and we report competitive results on three scene segmentation benchmarks. Our models and code are publicly available.
Continuous Adaptation for Interactive Object Segmentation by Learning from Corrections
Nov 28, 2019
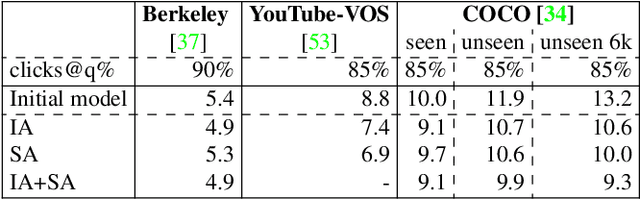

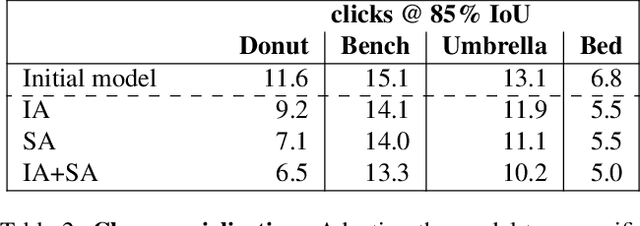
In interactive object segmentation a user collaborates with a computer vision model to segment an object. Recent works rely on convolutional neural networks to predict the segmentation, taking the image and the corrections made by the user as input. By training on large datasets they offer strong performance, but they keep model parameters fixed at test time. Instead, we treat user corrections as training examples to update our model on-the-fly to the data at hand. This enables it to successfully adapt to the appearance of a particular test image, to distributions shifts in the whole test set, and even to large domain changes, where the imaging modality changes between training and testing. We extensively evaluate our method on 8 diverse datasets and improve over a fixed model on all of them. Our method shows the most dramatic improvements when training and testing domains differ, where it produces segmentation masks of the desired quality from 60-70% less user input. Furthermore we achieve state-of-the-art on four standard interactive segmentation datasets: PASCAL VOC12, GrabCut, DAVIS16 and Berkeley.