 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeedsGalore: A Multispectral and Multitemporal UAV-based Dataset for Crop and Weed Segmentation in Agricultural Maize Fields
Feb 18, 2025
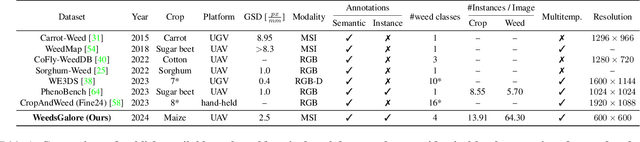


Weeds are one of the major reasons for crop yield loss but current weeding practices fail to manage weeds in an efficient and targeted manner. Effective weed management is especially important for crops with high worldwide production such as maize, to maximize crop yield for meeting increasing global demands. Advances in near-sensing and computer vision enable the development of new tools for weed management. Specifically, state-of-the-art segmentation models, coupled with novel sensing technologies, can facilitate timely and accurate weeding and monitoring systems. However, learning-based approaches require annotated data and show a lack of generalization to aerial imaging for different crops. We present a novel dataset for semantic and instance segmentation of crops and weeds in agricultural maize fields. The multispectral UAV-based dataset contains images with RGB, red-edge, and near-infrared bands, a large number of plant instances, dense annotations for maize and four weed classes, and is multitemporal. We provide extensive baseline results for both tasks, including probabilistic methods to quantify prediction uncertainty, improve model calibration, and demonstrate the approach's applicability to out-of-distribution data. The results show the effectiveness of the two additional bands compared to RGB only, and better performance in our target domain than models trained on existing datasets. We hope our dataset advances research on methods and operational systems for fine-grained weed identification, enhancing the robustness and applicability of UAV-based weed management. The dataset and code are available at https://github.com/GFZ/weedsgalore
Interactive Object Segmentation in 3D Point Clouds
Apr 14, 2022
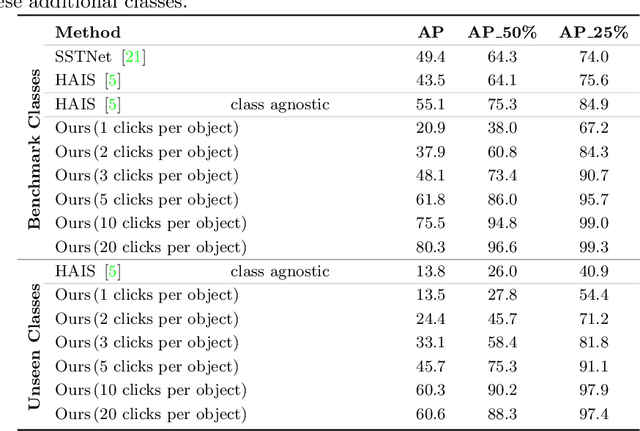

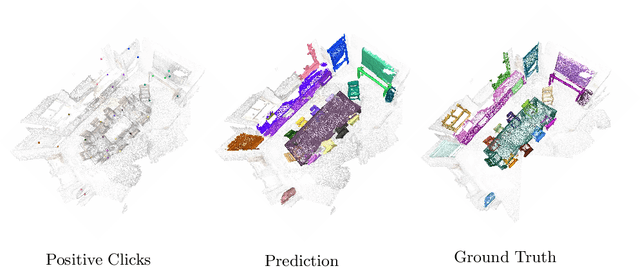
Deep learning depends on large amounts of labeled training data. Manual labeling is expensive and represents a bottleneck, especially for tasks such as segmentation, where labels must be assigned down to the level of individual points. That challenge is even more daunting for 3D data: 3D point clouds contain millions of points per scene, and their accurate annotation is markedly more time-consuming. The situation is further aggravated by the added complexity of user interfaces for 3D point clouds, which slows down annotation even more. For the case of 2D image segmentation, interactive techniques have become common, where user feedback in the form of a few clicks guides a segmentation algorithm -- nowadays usually a neural network -- to achieve an accurate labeling with minimal effort. Surprisingly, interactive segmentation of 3D scenes has not been explored much. Previous work has attempted to obtain accurate 3D segmentation masks using human feedback from the 2D domain, which is only possible if correctly aligned images are available together with the 3D point cloud, and it involves switching between the 2D and 3D domains. Here, we present an interactive 3D object segmentation method in which the user interacts directly with the 3D point cloud. Importantly, our model does not require training data from the target domain: when trained on ScanNet, it performs well on several other datasets with different data characteristics as well as different object classes. Moreover, our method is orthogonal to supervised (instance) segmentation methods and can be combined with them to refine automatic segmentations with minimal human effort.