 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentAnyTree: A sensor and platform agnostic deep learning model for tree segmentation using laser scanning data
Jan 28, 2024



This research advances individual tree crown (ITC) segmentation in lidar data, using a deep learning model applicable to various laser scanning types: airborne (ULS), terrestrial (TLS), and mobile (MLS). It addresses the challenge of transferability across different data characteristics in 3D forest scene analysis. The study evaluates the model's performance based on platform (ULS, MLS) and data density, testing five scenarios with varying input data, including sparse versions, to gauge adaptability and canopy layer efficacy. The model, based on PointGroup architecture, is a 3D CNN with separate heads for semantic and instance segmentation, validated on diverse point cloud datasets. Results show point cloud sparsification enhances performance, aiding sparse data handling and improving detection in dense forests. The model performs well with >50 points per sq. m densities but less so at 10 points per sq. m due to higher omission rates. It outperforms existing methods (e.g., Point2Tree, TLS2trees) in detection, omission, commission rates, and F1 score, setting new benchmarks on LAUTx, Wytham Woods, and TreeLearn datasets. In conclusion, this study shows the feasibility of a sensor-agnostic model for diverse lidar data, surpassing sensor-specific approaches and setting new standards in tree segmentation, particularly in complex forests. This contributes to future ecological modeling and forest management advancements.
Automated forest inventory: analysis of high-density airborne LiDAR point clouds with 3D deep learning
Dec 22, 2023



Detailed forest inventories are critical for sustainable and flexible management of forest resources, to conserve various ecosystem services. Modern airborne laser scanners deliver high-density point clouds with great potential for fine-scale forest inventory and analysis, but automatically partitioning those point clouds into meaningful entities like individual trees or tree components remains a challenge. The present study aims to fill this gap and introduces a deep learning framework that is able to perform such a segmentation across diverse forest types and geographic regions. From the segmented data, we then derive relevant biophysical parameters of individual trees as well as stands. The system has been tested on FOR-Instance, a dataset of point clouds that have been acquired in five different countries using surveying drones. The segmentation back-end achieves over 85% F-score for individual trees, respectively over 73% mean IoU across five semantic categories: ground, low vegetation, stems, live branches and dead branches. Building on the segmentation results our pipeline then densely calculates biophysical features of each individual tree (height, crown diameter, crown volume, DBH, and location) and properties per stand (digital terrain model and stand density). Especially crown-related features are in most cases retrieved with high accuracy, whereas the estimates for DBH and location are less reliable, due to the airborne scanning setup.
Towards accurate instance segmentation in large-scale LiDAR point clouds
Jul 06, 2023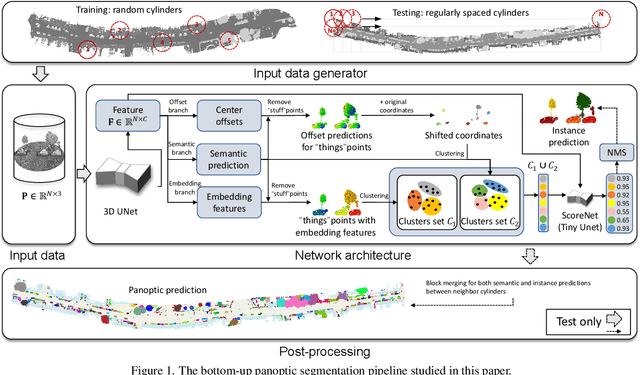
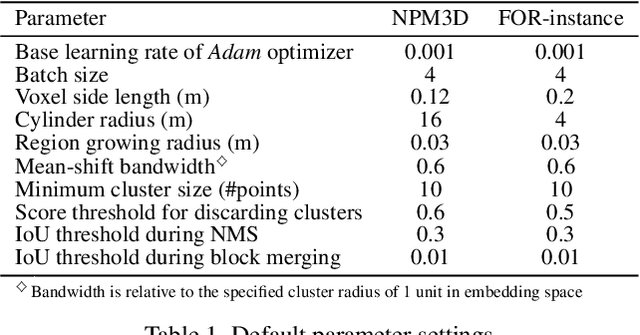
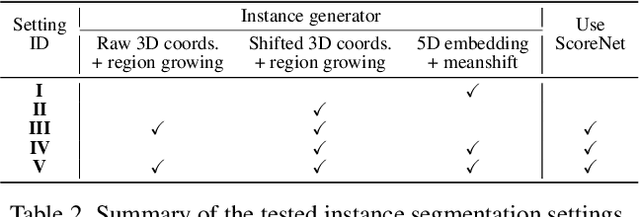
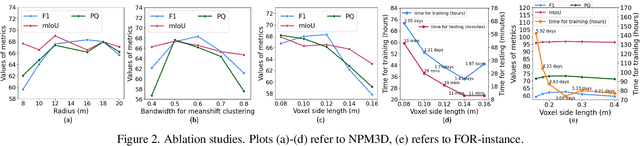
Panoptic segmentation is the combination of semantic and instance segmentation: assign the points in a 3D point cloud to semantic categories and partition them into distinct object instances. It has many obvious applications for outdoor scene understanding, from city mapping to forest management. Existing methods struggle to segment nearby instances of the same semantic category, like adjacent pieces of street furniture or neighbouring trees, which limits their usability for inventory- or management-type applications that rely on object instances. This study explores the steps of the panoptic segmentation pipeline concerned with clustering points into object instances, with the goal to alleviate that bottleneck. We find that a carefully designed clustering strategy, which leverages multiple types of learned point embeddings, significantly improves instance segmentation. Experiments on the NPM3D urban mobile mapping dataset and the FOR-instance forest dataset demonstrate the effectiveness and versatility of the proposed strategy.
A Review of Panoptic Segmentation for Mobile Mapping Point Clouds
Apr 27, 2023
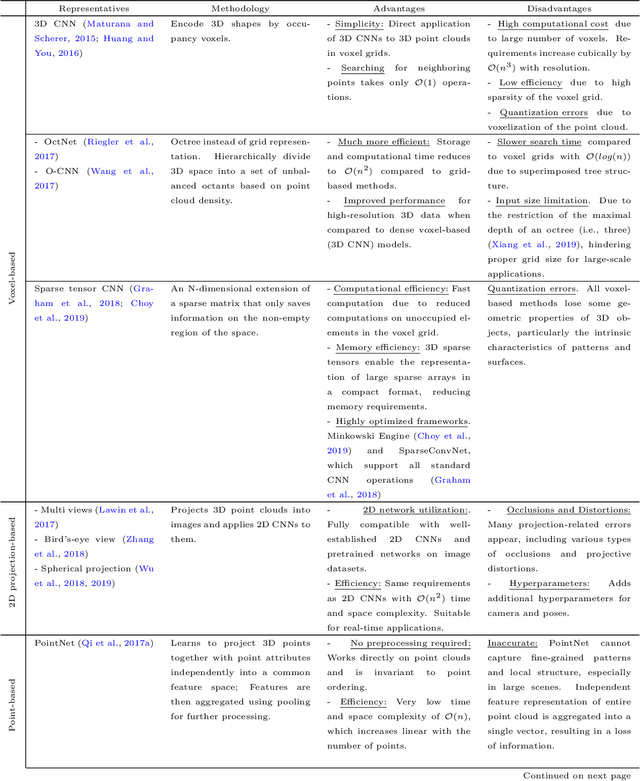
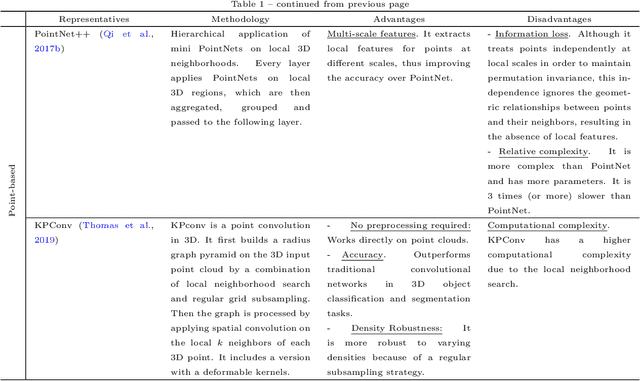

3D point cloud panoptic segmentation is the combined task to (i) assign each point to a semantic class and (ii) separate the points in each class into object instances. Recently there has been an increased interest in such comprehensive 3D scene understanding, building on the rapid advances of semantic segmentation due to the advent of deep 3D neural networks. Yet, to date there is very little work about panoptic segmentation of outdoor mobile-mapping data, and no systematic comparisons. The present paper tries to close that gap. It reviews the building blocks needed to assemble a panoptic segmentation pipeline and the related literature. Moreover, a modular pipeline is set up to perform comprehensive, systematic experiments to assess the state of panoptic segmentation in the context of street mapping. As a byproduct, we also provide the first public dataset for that task, by extending the NPM3D dataset to include instance labels.
Multiple Combined Constraints for Image Stitching
Sep 18, 2018



Several approaches to image stitching use different constraints to estimate the motion model between image pairs. These constraints can be roughly divided into two categories: geometric constraints and photometric constraints. In this paper, geometric and photometric constraints are combined to improve the alignment quality, which is based on the observation that these two kinds of constraints are complementary. On the one hand, geometric constraints (e.g., point and line correspondences) are usually spatially biased and are insufficient in some extreme scenes, while photometric constraints are always evenly and densely distributed. On the other hand, photometric constraints are sensitive to displacements and are not suitable for images with large parallaxes, while geometric constraints are usually imposed by feature matching and are more robust to handle parallaxes. The proposed method therefore combines them together in an efficient mesh-based image warping framework. It achieves better alignment quality than methods only with geometric constraints, and can handle larger parallax than photometric-constraint-based method. Experimental results on various images illustrate that the proposed method outperforms representative state-of-the-art image stitching methods reported in the literature.