 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultispectral airborne laser scanning for tree species classification: a benchmark of machine learning and deep learning algorithms
Apr 19, 2025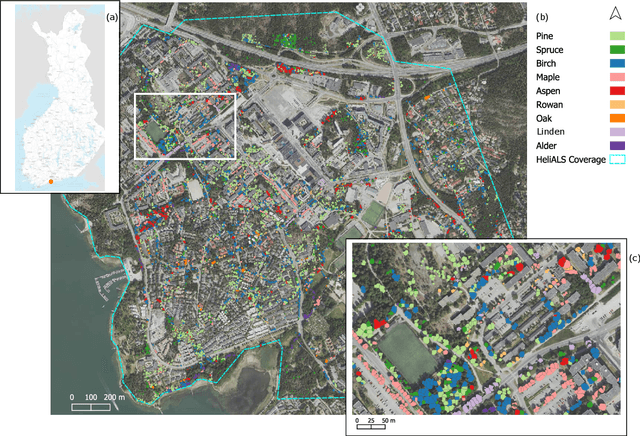


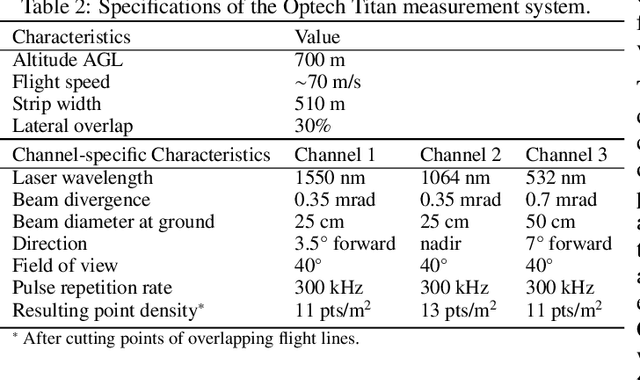
Climate-smart and biodiversity-preserving forestry demands precise information on forest resources, extending to the individual tree level. Multispectral airborne laser scanning (ALS) has shown promise in automated point cloud processing and tree segmentation, but challenges remain in identifying rare tree species and leveraging deep learning techniques. This study addresses these gaps by conducting a comprehensive benchmark of machine learning and deep learning methods for tree species classification. For the study, we collected high-density multispectral ALS data (>1000 pts/m$^2$) at three wavelengths using the FGI-developed HeliALS system, complemented by existing Optech Titan data (35 pts/m$^2$), to evaluate the species classification accuracy of various algorithms in a test site located in Southern Finland. Based on 5261 test segments, our findings demonstrate that point-based deep learning methods, particularly a point transformer model, outperformed traditional machine learning and image-based deep learning approaches on high-density multispectral point clouds. For the high-density ALS dataset, a point transformer model provided the best performance reaching an overall (macro-average) accuracy of 87.9% (74.5%) with a training set of 1065 segments and 92.0% (85.1%) with 5000 training segments. The best image-based deep learning method, DetailView, reached an overall (macro-average) accuracy of 84.3% (63.9%), whereas a random forest (RF) classifier achieved an overall (macro-average) accuracy of 83.2% (61.3%). Importantly, the overall classification accuracy of the point transformer model on the HeliALS data increased from 73.0% with no spectral information to 84.7% with single-channel reflectance, and to 87.9% with spectral information of all the three channels.
Benchmarking tree species classification from proximally-sensed laser scanning data: introducing the FOR-species20K dataset
Aug 12, 2024Proximally-sensed laser scanning offers significant potential for automated forest data capture, but challenges remain in automatically identifying tree species without additional ground data. Deep learning (DL) shows promise for automation, yet progress is slowed by the lack of large, diverse, openly available labeled datasets of single tree point clouds. This has impacted the robustness of DL models and the ability to establish best practices for species classification. To overcome these challenges, the FOR-species20K benchmark dataset was created, comprising over 20,000 tree point clouds from 33 species, captured using terrestrial (TLS), mobile (MLS), and drone laser scanning (ULS) across various European forests, with some data from other regions. This dataset enables the benchmarking of DL models for tree species classification, including both point cloud-based (PointNet++, MinkNet, MLP-Mixer, DGCNNs) and multi-view image-based methods (SimpleView, DetailView, YOLOv5). 2D image-based models generally performed better (average OA = 0.77) than 3D point cloud-based models (average OA = 0.72), with consistent results across different scanning platforms and sensors. The top model, DetailView, was particularly robust, handling data imbalances well and generalizing effectively across tree sizes. The FOR-species20K dataset, available at https://zenodo.org/records/13255198, is a key resource for developing and benchmarking DL models for tree species classification using laser scanning data, providing a foundation for future advancements in the field.
SegmentAnyTree: A sensor and platform agnostic deep learning model for tree segmentation using laser scanning data
Jan 28, 2024



This research advances individual tree crown (ITC) segmentation in lidar data, using a deep learning model applicable to various laser scanning types: airborne (ULS), terrestrial (TLS), and mobile (MLS). It addresses the challenge of transferability across different data characteristics in 3D forest scene analysis. The study evaluates the model's performance based on platform (ULS, MLS) and data density, testing five scenarios with varying input data, including sparse versions, to gauge adaptability and canopy layer efficacy. The model, based on PointGroup architecture, is a 3D CNN with separate heads for semantic and instance segmentation, validated on diverse point cloud datasets. Results show point cloud sparsification enhances performance, aiding sparse data handling and improving detection in dense forests. The model performs well with >50 points per sq. m densities but less so at 10 points per sq. m due to higher omission rates. It outperforms existing methods (e.g., Point2Tree, TLS2trees) in detection, omission, commission rates, and F1 score, setting new benchmarks on LAUTx, Wytham Woods, and TreeLearn datasets. In conclusion, this study shows the feasibility of a sensor-agnostic model for diverse lidar data, surpassing sensor-specific approaches and setting new standards in tree segmentation, particularly in complex forests. This contributes to future ecological modeling and forest management advancements.
Automated forest inventory: analysis of high-density airborne LiDAR point clouds with 3D deep learning
Dec 22, 2023



Detailed forest inventories are critical for sustainable and flexible management of forest resources, to conserve various ecosystem services. Modern airborne laser scanners deliver high-density point clouds with great potential for fine-scale forest inventory and analysis, but automatically partitioning those point clouds into meaningful entities like individual trees or tree components remains a challenge. The present study aims to fill this gap and introduces a deep learning framework that is able to perform such a segmentation across diverse forest types and geographic regions. From the segmented data, we then derive relevant biophysical parameters of individual trees as well as stands. The system has been tested on FOR-Instance, a dataset of point clouds that have been acquired in five different countries using surveying drones. The segmentation back-end achieves over 85% F-score for individual trees, respectively over 73% mean IoU across five semantic categories: ground, low vegetation, stems, live branches and dead branches. Building on the segmentation results our pipeline then densely calculates biophysical features of each individual tree (height, crown diameter, crown volume, DBH, and location) and properties per stand (digital terrain model and stand density). Especially crown-related features are in most cases retrieved with high accuracy, whereas the estimates for DBH and location are less reliable, due to the airborne scanning setup.
Multi-Sensor Terrestrial SLAM for Real-Time, Large-Scale, and GNSS-Interrupted Forest Mapping
Oct 02, 2023



Forests, as critical components of our ecosystem, demand effective monitoring and management. However, conducting real-time forest inventory in large-scale and GNSS-interrupted forest environments has long been a formidable challenge. In this paper, we present a novel solution that leverages robotics and sensor-fusion technologies to overcome these challenges and enable real-time forest inventory with higher accuracy and efficiency. The proposed solution consists of a new SLAM algorithm to create an accurate 3D map of large-scale forest stands with detailed estimation about the number of trees and the corresponding DBH, solely with the consecutive scans of a 3D lidar and an imu. This method utilized a hierarchical unsupervised clustering algorithm to detect the trees and measure the DBH from the lidar point cloud. The algorithm can run simultaneously as the data is being recorded or afterwards on the recorded dataset. Furthermore, due to the proposed fast feature extraction and transform estimation modules, the recorded data can be fed to the SLAM with higher frequency than common SLAM algorithms. The performance of the proposed solution was tested through filed data collection with hand-held sensor platform as well as a mobile forestry robot. The accuracy of the results was also compared to the state-of-the-art SLAM solutions.
FOR-instance: a UAV laser scanning benchmark dataset for semantic and instance segmentation of individual trees
Sep 03, 2023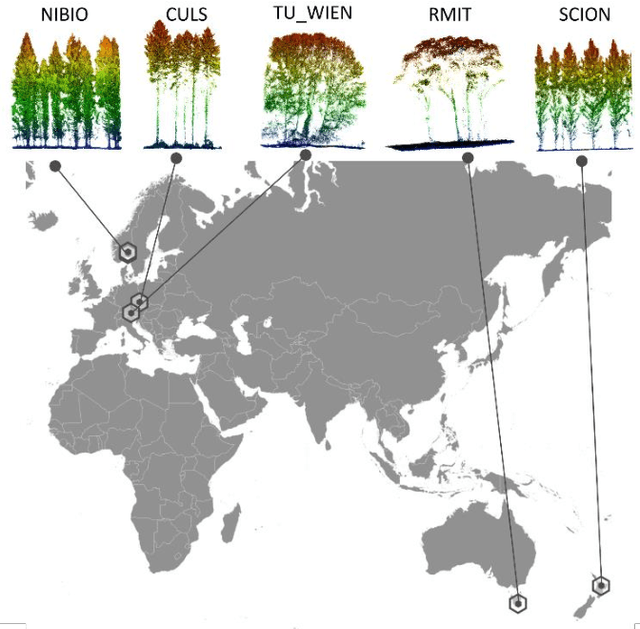

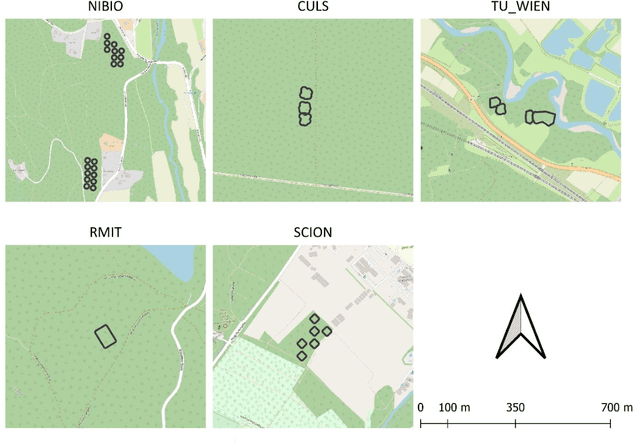

The FOR-instance dataset (available at https://doi.org/10.5281/zenodo.8287792) addresses the challenge of accurate individual tree segmentation from laser scanning data, crucial for understanding forest ecosystems and sustainable management. Despite the growing need for detailed tree data, automating segmentation and tracking scientific progress remains difficult. Existing methodologies often overfit small datasets and lack comparability, limiting their applicability. Amid the progress triggered by the emergence of deep learning methodologies, standardized benchmarking assumes paramount importance in these research domains. This data paper introduces a benchmarking dataset for dense airborne laser scanning data, aimed at advancing instance and semantic segmentation techniques and promoting progress in 3D forest scene segmentation. The FOR-instance dataset comprises five curated and ML-ready UAV-based laser scanning data collections from diverse global locations, representing various forest types. The laser scanning data were manually annotated into individual trees (instances) and different semantic classes (e.g. stem, woody branches, live branches, terrain, low vegetation). The dataset is divided into development and test subsets, enabling method advancement and evaluation, with specific guidelines for utilization. It supports instance and semantic segmentation, offering adaptability to deep learning frameworks and diverse segmentation strategies, while the inclusion of diameter at breast height data expands its utility to the measurement of a classic tree variable. In conclusion, the FOR-instance dataset contributes to filling a gap in the 3D forest research, enhancing the development and benchmarking of segmentation algorithms for dense airborne laser scanning data.
Towards accurate instance segmentation in large-scale LiDAR point clouds
Jul 06, 2023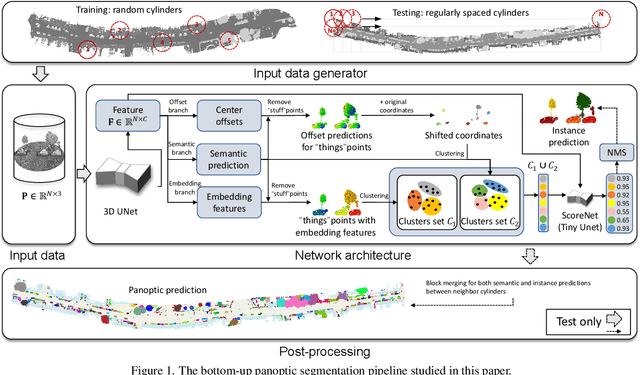
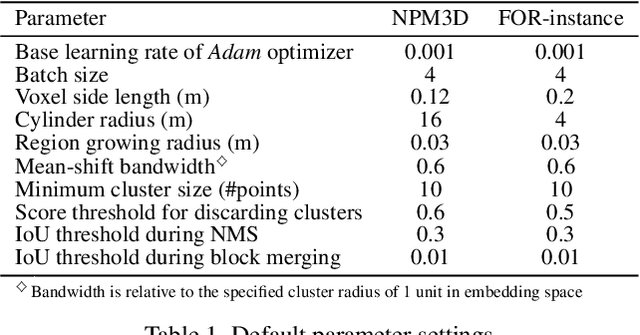
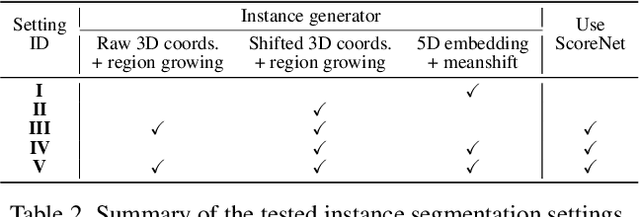
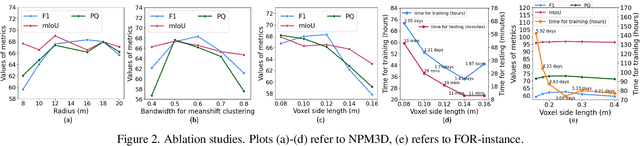
Panoptic segmentation is the combination of semantic and instance segmentation: assign the points in a 3D point cloud to semantic categories and partition them into distinct object instances. It has many obvious applications for outdoor scene understanding, from city mapping to forest management. Existing methods struggle to segment nearby instances of the same semantic category, like adjacent pieces of street furniture or neighbouring trees, which limits their usability for inventory- or management-type applications that rely on object instances. This study explores the steps of the panoptic segmentation pipeline concerned with clustering points into object instances, with the goal to alleviate that bottleneck. We find that a carefully designed clustering strategy, which leverages multiple types of learned point embeddings, significantly improves instance segmentation. Experiments on the NPM3D urban mobile mapping dataset and the FOR-instance forest dataset demonstrate the effectiveness and versatility of the proposed strategy.
Point2Tree(P2T) -- framework for parameter tuning of semantic and instance segmentation used with mobile laser scanning data in coniferous forest
May 04, 2023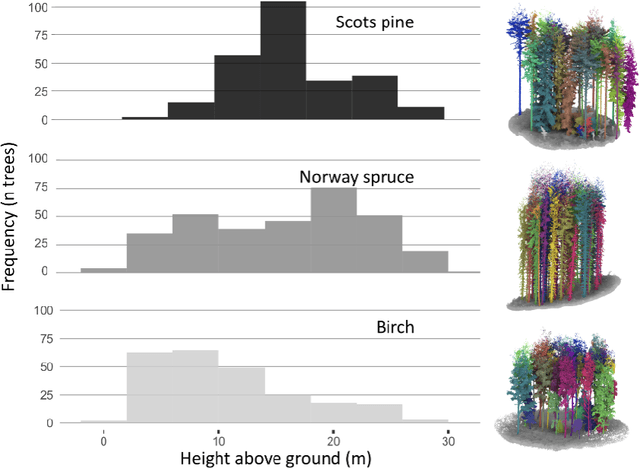



This article introduces Point2Tree, a novel framework that incorporates a three-stage process involving semantic segmentation, instance segmentation, optimization analysis of hyperparemeters importance. It introduces a comprehensive and modular approach to processing laser points clouds in Forestry. We tested it on two independent datasets. The first area was located in an actively managed boreal coniferous dominated forest in V{\aa}ler, Norway, 16 circular plots of 400 square meters were selected to cover a range of forest conditions in terms of species composition and stand density. We trained a model based on Pointnet++ architecture which achieves 0.92 F1-score in semantic segmentation. As a second step in our pipeline we used graph-based approach for instance segmentation which reached F1-score approx. 0.6. The optimization allowed to further boost the performance of the pipeline by approx. 4 \% points.
Prediction of butt rot volume in Norway spruce forest stands using harvester, remotely sensed and environmental data
Jul 09, 2021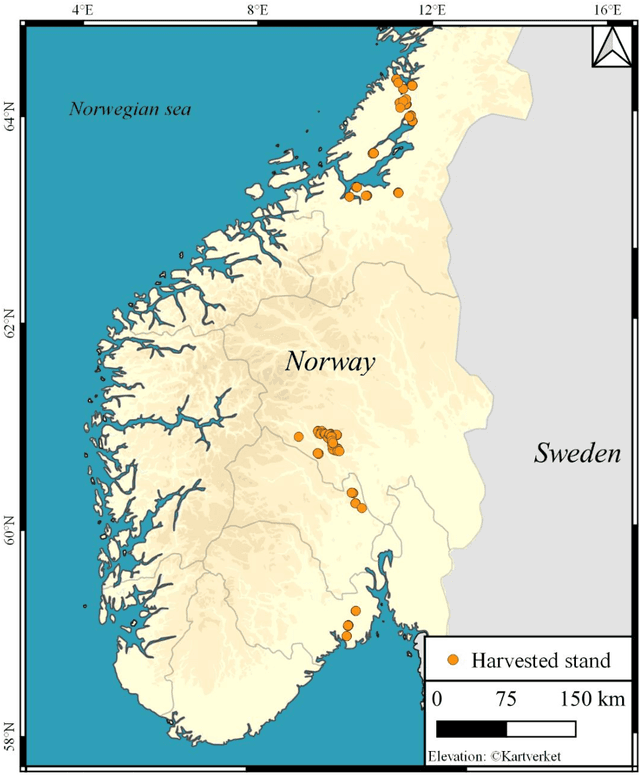
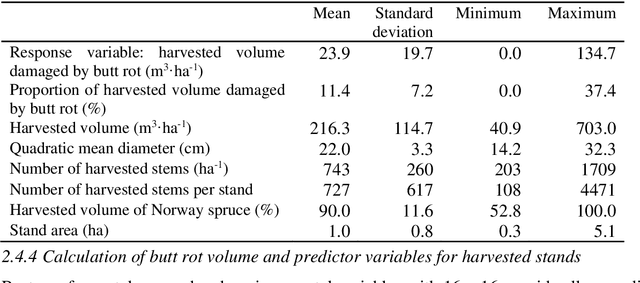
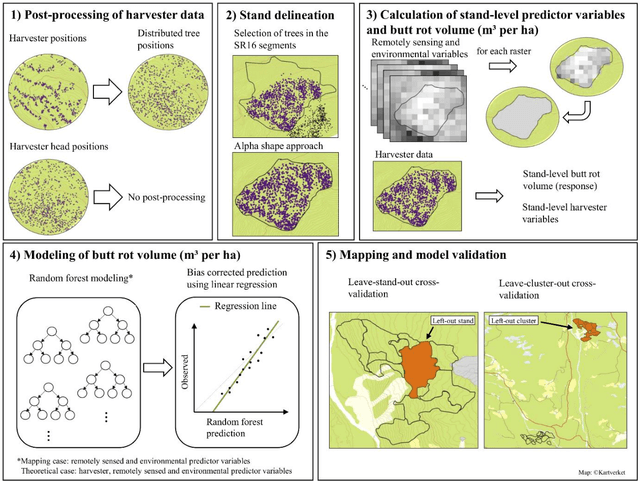
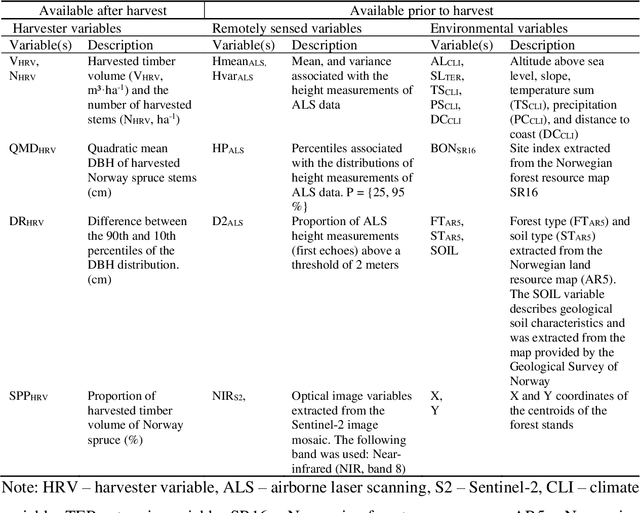
Butt rot (BR) damages associated with Norway spruce (Picea abies [L.] Karst.) account for considerable economic losses in timber production across the northern hemisphere. While information on BR damages is critical for optimal decision-making in forest management, the maps of BR damages are typically lacking in forest information systems. We predicted timber volume damaged by BR at the stand-level in Norway using harvester information of 186,026 stems (clear-cuts), remotely sensed, and environmental data (e.g. climate and terrain characteristics). We utilized random forest (RF) models with two sets of predictor variables: (1) predictor variables available after harvest (theoretical case) and (2) predictor variables available prior to harvest (mapping case). We found that forest attributes characterizing the maturity of forest, such as remote sensing-based height, harvested timber volume and quadratic mean diameter at breast height, were among the most important predictor variables. Remotely sensed predictor variables obtained from airborne laser scanning data and Sentinel-2 imagery were more important than the environmental variables. The theoretical case with a leave-stand-out cross-validation achieved an RMSE of 11.4 $m^3ha^{-1}$ (pseudo $R^2$: 0.66) whereas the mapping case resulted in a pseudo $R^2$ of 0.60. When the spatially distinct k-means clusters of harvested forest stands were used as units in the cross-validation, the RMSE value and pseudo $R^2$ associated with the mapping case were 15.6 $m^3ha^{-1}$ and 0.37, respectively. This indicates that the knowledge about the BR status of spatially close stands is of high importance for obtaining satisfactory error rates in the mapping of BR damages.