 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive4D: Interactive 4D LiDAR Segmentation
Oct 10, 2024



Interactive segmentation has an important role in facilitating the annotation process of future LiDAR datasets. Existing approaches sequentially segment individual objects at each LiDAR scan, repeating the process throughout the entire sequence, which is redundant and ineffective. In this work, we propose interactive 4D segmentation, a new paradigm that allows segmenting multiple objects on multiple LiDAR scans simultaneously, and Interactive4D, the first interactive 4D segmentation model that segments multiple objects on superimposed consecutive LiDAR scans in a single iteration by utilizing the sequential nature of LiDAR data. While performing interactive segmentation, our model leverages the entire space-time volume, leading to more efficient segmentation. Operating on the 4D volume, it directly provides consistent instance IDs over time and also simplifies tracking annotations. Moreover, we show that click simulations are crucial for successful model training on LiDAR point clouds. To this end, we design a click simulation strategy that is better suited for the characteristics of LiDAR data. To demonstrate its accuracy and effectiveness, we evaluate Interactive4D on multiple LiDAR datasets, where Interactive4D achieves a new state-of-the-art by a large margin. Upon acceptance, we will publicly release the code and models at https://vision.rwth-aachen.de/Interactive4D.
Point-VOS: Pointing Up Video Object Segmentation
Feb 08, 2024Current state-of-the-art Video Object Segmentation (VOS) methods rely on dense per-object mask annotations both during training and testing. This requires time-consuming and costly video annotation mechanisms. We propose a novel Point-VOS task with a spatio-temporally sparse point-wise annotation scheme that substantially reduces the annotation effort. We apply our annotation scheme to two large-scale video datasets with text descriptions and annotate over 19M points across 133K objects in 32K videos. Based on our annotations, we propose a new Point-VOS benchmark, and a corresponding point-based training mechanism, which we use to establish strong baseline results. We show that existing VOS methods can easily be adapted to leverage our point annotations during training, and can achieve results close to the fully-supervised performance when trained on pseudo-masks generated from these points. In addition, we show that our data can be used to improve models that connect vision and language, by evaluating it on the Video Narrative Grounding (VNG) task. We will make our code and annotations available at https://pointvos.github.io.
4D-StOP: Panoptic Segmentation of 4D LiDAR using Spatio-temporal Object Proposal Generation and Aggregation
Sep 29, 2022
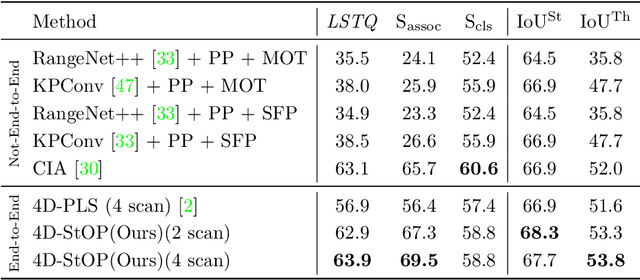
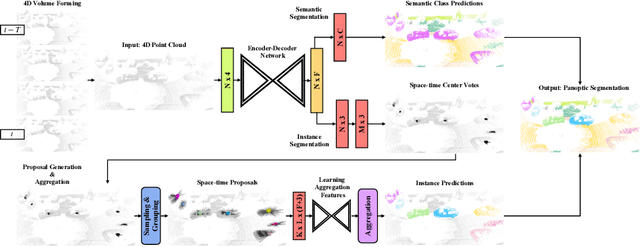
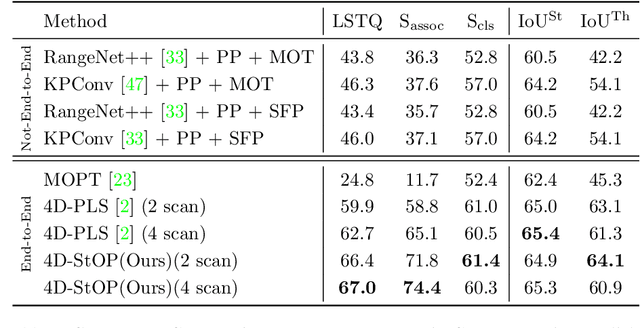
In this work, we present a new paradigm, called 4D-StOP, to tackle the task of 4D Panoptic LiDAR Segmentation. 4D-StOP first generates spatio-temporal proposals using voting-based center predictions, where each point in the 4D volume votes for a corresponding center. These tracklet proposals are further aggregated using learned geometric features. The tracklet aggregation method effectively generates a video-level 4D scene representation over the entire space-time volume. This is in contrast to existing end-to-end trainable state-of-the-art approaches which use spatio-temporal embeddings that are represented by Gaussian probability distributions. Our voting-based tracklet generation method followed by geometric feature-based aggregation generates significantly improved panoptic LiDAR segmentation quality when compared to modeling the entire 4D volume using Gaussian probability distributions. 4D-StOP achieves a new state-of-the-art when applied to the SemanticKITTI test dataset with a score of 63.9 LSTQ, which is a large (+7%) improvement compared to current best-performing end-to-end trainable methods. The code and pre-trained models are available at: https://github.com/LarsKreuzberg/4D-StOP.
Opening up Open-World Tracking
Apr 22, 2021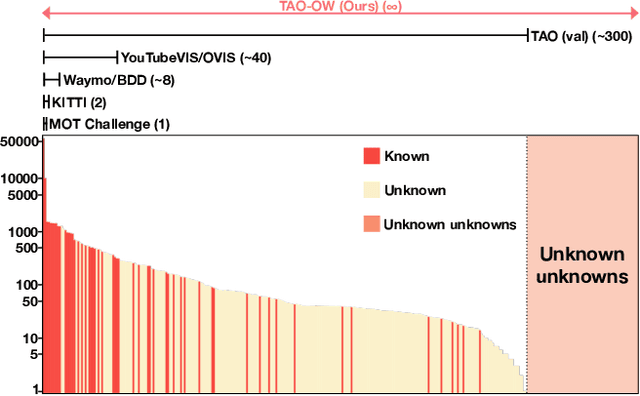


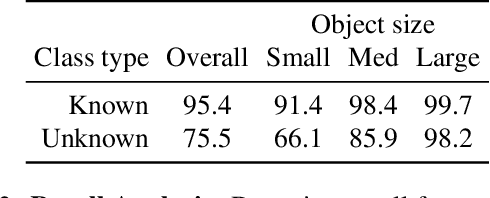
In this paper, we propose and study Open-World Tracking (OWT). Open-world tracking goes beyond current multi-object tracking benchmarks and methods which focus on tracking object classes that belong to a predefined closed-set of frequently observed object classes. In OWT, we relax this assumption: we may encounter objects at inference time that were not labeled for training. The main contribution of this paper is the formalization of the OWT task, along with an evaluation protocol and metric (Open-World Tracking Accuracy, OWTA), which decomposes into two intuitive terms, one for measuring recall, and another for measuring track association accuracy. This allows us to perform a rigorous evaluation of several different baselines that follow design patterns proposed in the multi-object tracking community. Further we show that our Open-World Tracking Baseline, while performing well in the OWT setting, also achieves near state-of-the-art results on traditional closed-world benchmarks, without any adjustments or tuning. We believe that this paper is an initial step towards studying multi-object tracking in the open world, a task of crucial importance for future intelligent agents that will need to understand, react to, and learn from, an infinite variety of objects that can appear in an open world.
UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking
Jan 15, 2020
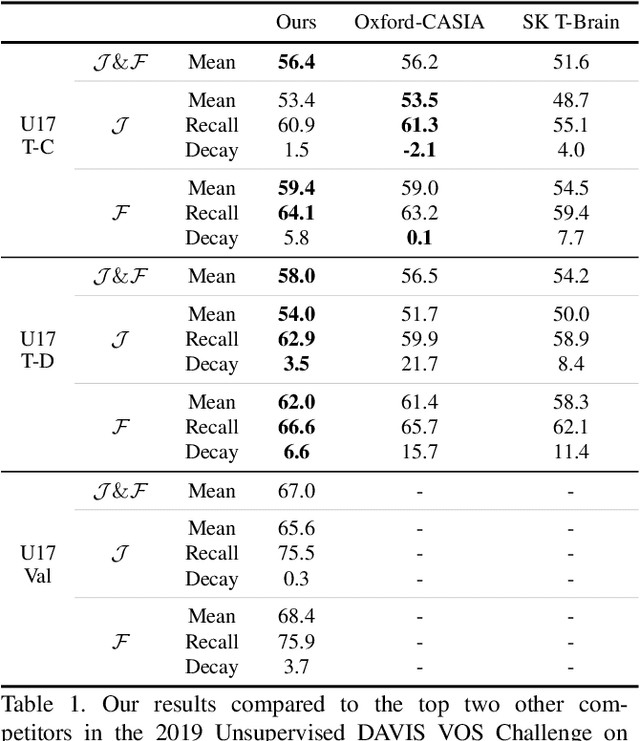
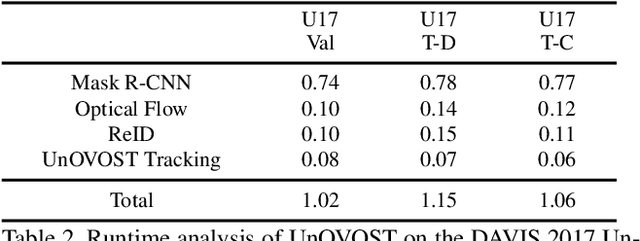
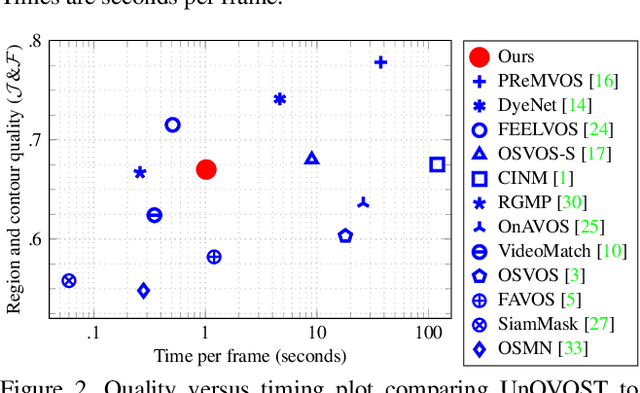
We address Unsupervised Video Object Segmentation (UVOS), the task of automatically generating accurate pixel masks for salient objects in a video sequence and of tracking these objects consistently through time, without any input about which objects should be tracked. Towards solving this task, we present UnOVOST (Unsupervised Offline Video Object Segmentation and Tracking) as a simple and generic algorithm which is able to track and segment a large variety of objects. This algorithm builds up tracks in a number stages, first grouping segments into short tracklets that are spatio-temporally consistent, before merging these tracklets into long-term consistent object tracks based on their visual similarity. In order to achieve this we introduce a novel tracklet-based Forest Path Cutting data association algorithm which builds up a decision forest of track hypotheses before cutting this forest into paths that form long-term consistent object tracks. When evaluating our approach on the DAVIS 2017 Unsupervised dataset we obtain state-of-the-art performance with a mean J &F score of 67.9% on the val, 58% on the test-dev and 56.4% on the test-challenge benchmarks, obtaining first place in the DAVIS 2019 Unsupervised Video Object Segmentation Challenge. UnOVOST even performs competitively with many semi-supervised video object segmentation algorithms even though it is not given any input as to which objects should be tracked and segmented.