 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Aligned CLIP for Few-shot Classification
Nov 15, 2023Large vision-language representation learning models like CLIP have demonstrated impressive performance for zero-shot transfer to downstream tasks while largely benefiting from inter-modal (image-text) alignment via contrastive objectives. This downstream performance can further be enhanced by full-scale fine-tuning which is often compute intensive, requires large labelled data, and can reduce out-of-distribution (OOD) robustness. Furthermore, sole reliance on inter-modal alignment might overlook the rich information embedded within each individual modality. In this work, we introduce a sample-efficient domain adaptation strategy for CLIP, termed Domain Aligned CLIP (DAC), which improves both intra-modal (image-image) and inter-modal alignment on target distributions without fine-tuning the main model. For intra-modal alignment, we introduce a lightweight adapter that is specifically trained with an intra-modal contrastive objective. To improve inter-modal alignment, we introduce a simple framework to modulate the precomputed class text embeddings. The proposed few-shot fine-tuning framework is computationally efficient, robust to distribution shifts, and does not alter CLIP's parameters. We study the effectiveness of DAC by benchmarking on 11 widely used image classification tasks with consistent improvements in 16-shot classification upon strong baselines by about 2.3% and demonstrate competitive performance on 4 OOD robustness benchmarks.
A Dual Adversarial Calibration Framework for Automatic Fetal Brain Biometry
Aug 28, 2021


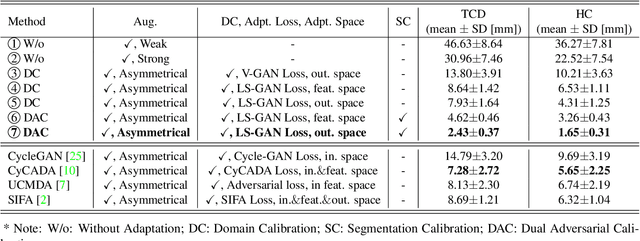
This paper presents a novel approach to automatic fetal brain biometry motivated by needs in low- and medium- income countries. Specifically, we leverage high-end (HE) ultrasound images to build a biometry solution for low-cost (LC) point-of-care ultrasound images. We propose a novel unsupervised domain adaptation approach to train deep models to be invariant to significant image distribution shift between the image types. Our proposed method, which employs a Dual Adversarial Calibration (DAC) framework, consists of adversarial pathways which enforce model invariance to; i) adversarial perturbations in the feature space derived from LC images, and ii) appearance domain discrepancy. Our Dual Adversarial Calibration method estimates transcerebellar diameter and head circumference on images from low-cost ultrasound devices with a mean absolute error (MAE) of 2.43mm and 1.65mm, compared with 7.28 mm and 5.65 mm respectively for SOTA.
Automatic Probe Movement Guidance for Freehand Obstetric Ultrasound
Jul 08, 2020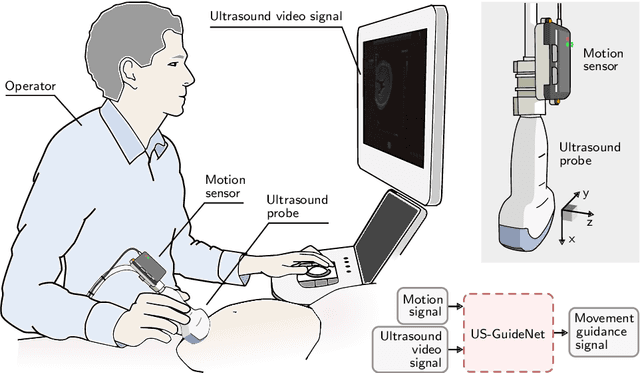

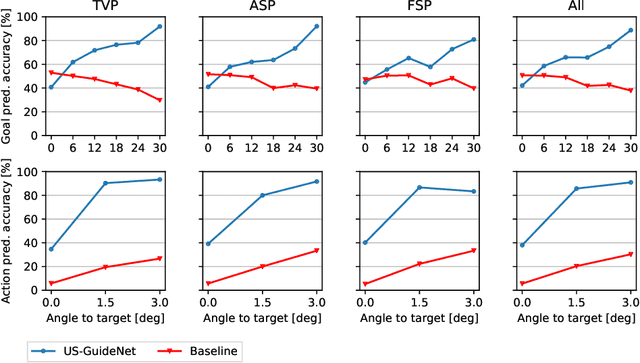
We present the first system that provides real-time probe movement guidance for acquiring standard planes in routine freehand obstetric ultrasound scanning. Such a system can contribute to the worldwide deployment of obstetric ultrasound scanning by lowering the required level of operator expertise. The system employs an artificial neural network that receives the ultrasound video signal and the motion signal of an inertial measurement unit (IMU) that is attached to the probe, and predicts a guidance signal. The network termed US-GuideNet predicts either the movement towards the standard plane position (goal prediction), or the next movement that an expert sonographer would perform (action prediction). While existing models for other ultrasound applications are trained with simulations or phantoms, we train our model with real-world ultrasound video and probe motion data from 464 routine clinical scans by 17 accredited sonographers. Evaluations for 3 standard plane types show that the model provides a useful guidance signal with an accuracy of 88.8% for goal prediction and 90.9% for action prediction.
Unified Image and Video Saliency Modeling
Mar 11, 2020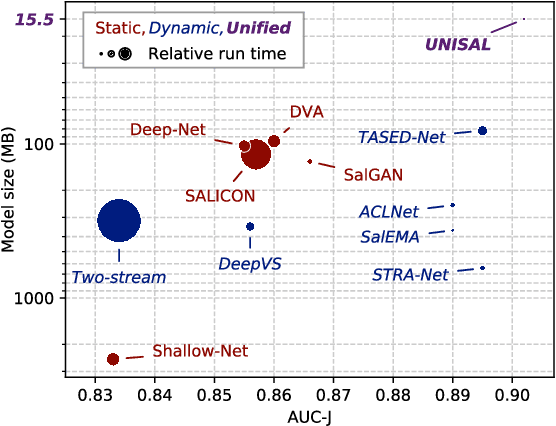

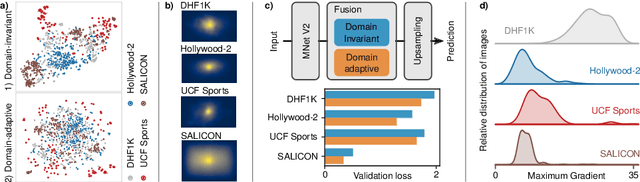
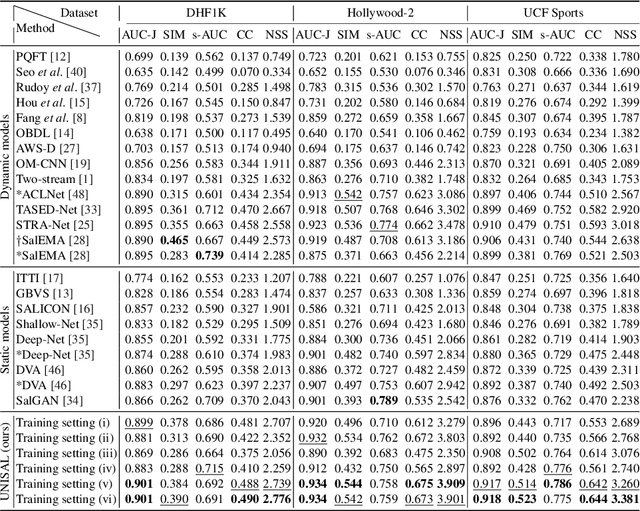
Visual saliency modeling for images and videos is treated as two independent tasks in recent computer vision literature. On the one hand, image saliency modeling is a well-studied problem and progress on benchmarks like \mbox{SALICON} and MIT300 is slowing. For video saliency prediction on the other hand, rapid gains have been achieved on the recent DHF1K benchmark through network architectures that are optimized for this task. Here, we take a step back and ask: Can image and video saliency modeling be approached via a unified model, with mutual benefit? We find that it is crucial to model the domain shift between image and video saliency data and between different video saliency datasets for effective joint modeling. We identify different sources of domain shift and address them through four novel domain adaptation techniques - Domain-Adaptive Priors, Domain-Adaptive Fusion, Domain-Adaptive Smoothing and Bypass-RNN - in addition to an improved formulation of learned Gaussian priors. We integrate these techniques into a simple and lightweight encoder-RNN-decoder-style network, UNISAL, and train the entire network simultaneously with image and video saliency data. We evaluate our method on the video saliency datasets DHF1K, Hollywood-2 and UCF-Sports, as well as the image saliency datasets SALICON and MIT300. With one set of parameters, our method achieves state-of-the-art performance on all video saliency datasets and is on par with the state-of-the-art for image saliency prediction, despite a 5 to 20-fold reduction in model size and the fastest runtime among all competing deep models. We provide retrospective analyses and ablation studies which demonstrate the importance of the domain shift modeling. The code is available at https://github.com/rdroste/unisal.
Self-supervised Representation Learning for Ultrasound Video
Feb 28, 2020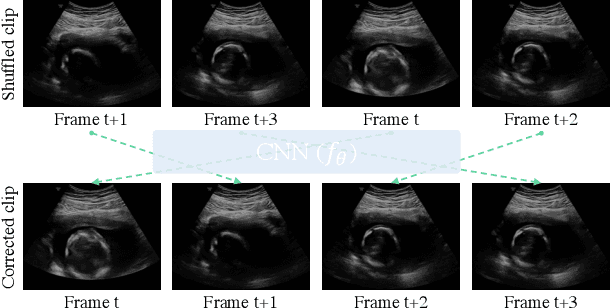

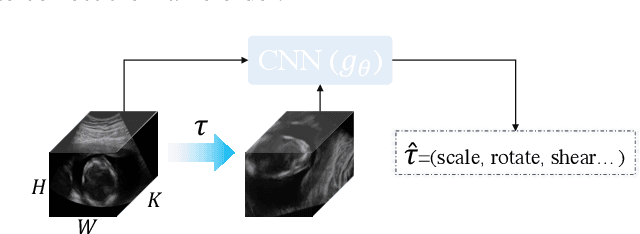
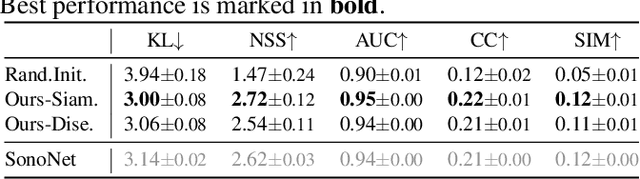
Recent advances in deep learning have achieved promising performance for medical image analysis, while in most cases ground-truth annotations from human experts are necessary to train the deep model. In practice, such annotations are expensive to collect and can be scarce for medical imaging applications. Therefore, there is significant interest in learning representations from unlabelled raw data. In this paper, we propose a self-supervised learning approach to learn meaningful and transferable representations from medical imaging video without any type of human annotation. We assume that in order to learn such a representation, the model should identify anatomical structures from the unlabelled data. Therefore we force the model to address anatomy-aware tasks with free supervision from the data itself. Specifically, the model is designed to correct the order of a reshuffled video clip and at the same time predict the geometric transformation applied to the video clip. Experiments on fetal ultrasound video show that the proposed approach can effectively learn meaningful and strong representations, which transfer well to downstream tasks like standard plane detection and saliency prediction.
Discovering Salient Anatomical Landmarks by Predicting Human Gaze
Jan 22, 2020
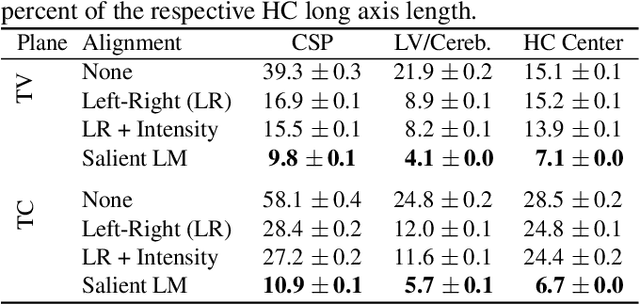


Anatomical landmarks are a crucial prerequisite for many medical imaging tasks. Usually, the set of landmarks for a given task is predefined by experts. The landmark locations for a given image are then annotated manually or via machine learning methods trained on manual annotations. In this paper, in contrast, we present a method to automatically discover and localize anatomical landmarks in medical images. Specifically, we consider landmarks that attract the visual attention of humans, which we term visually salient landmarks. We illustrate the method for fetal neurosonographic images. First, full-length clinical fetal ultrasound scans are recorded with live sonographer gaze-tracking. Next, a convolutional neural network (CNN) is trained to predict the gaze point distribution (saliency map) of the sonographers on scan video frames. The CNN is then used to predict saliency maps of unseen fetal neurosonographic images, and the landmarks are extracted as the local maxima of these saliency maps. Finally, the landmarks are matched across images by clustering the landmark CNN features. We show that the discovered landmarks can be used within affine image registration, with average landmark alignment errors between 4.1% and 10.9% of the fetal head long axis length.
Ultrasound Image Representation Learning by Modeling Sonographer Visual Attention
Mar 07, 2019Image representations are commonly learned from class labels, which are a simplistic approximation of human image understanding. In this paper we demonstrate that transferable representations of images can be learned without manual annotations by modeling human visual attention. The basis of our analyses is a unique gaze tracking dataset of sonographers performing routine clinical fetal anomaly screenings. Models of sonographer visual attention are learned by training a convolutional neural network (CNN) to predict gaze on ultrasound video frames through visual saliency prediction or gaze-point regression. We evaluate the transferability of the learned representations to the task of ultrasound standard plane detection in two contexts. Firstly, we perform transfer learning by fine-tuning the CNN with a limited number of labeled standard plane images. We find that fine-tuning the saliency predictor is superior to training from random initialization, with an average F1-score improvement of 9.6% overall and 15.3% for the cardiac planes. Secondly, we train a simple softmax regression on the feature activations of each CNN layer in order to evaluate the representations independently of transfer learning hyper-parameters. We find that the attention models derive strong representations, approaching the precision of a fully-supervised baseline model for all but the last layer.