 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Progress-Aware Leader-Follower Midair Docking System for Dual-Drone Aerial Manipulation
May 28, 2026Reliable midair docking between small unmanned aerial vehicles (UAVs) is essential for modular aerial cooperation and manipulation, but it requires precise relative-pose control and repeatable platform under tight thrust and payload constraints. We present a dual-drone docking platform where two quadrotors operate in a leader-follower formation and dock using a lightweight modular frame with passive magnetic latching. A progress-aware mission supervisor manages phase transitions: approach, alignment, capture, and settle. This platform integrates a complete hardware-software stack (ROS 2 with Crazyflie/PX4 interfaces) and synchronized logging for benchmark evaluation. We evaluate the platform in simulation and real-world experiments using quantitative metrics such as formation error, baseline and yaw consistency, docking success rate, time-to-dock, and failure-mode statistics. The platform enables statistically grounded comparison of docking supervision and synchronization strategies and provides a practical testbed for modular aerial cooperation and repeatable midair aerial manipulation.
Generative Profiling for Soft Real-Time Systems and its Applications to Resource Allocation
Apr 01, 2026Modern real-time systems require accurate characterization of task timing behavior to ensure predictable performance, particularly on complex hardware architectures. Existing methods, such as worst-case execution time analysis, often fail to capture the fine-grained timing behaviors of a task under varying resource contexts (e.g., an allocation of cache, memory bandwidth, and CPU frequency), which is necessary to achieve efficient resource utilization. In this paper, we introduce a novel generative profiling approach that synthesizes context-dependent, fine-grained timing profiles for real-time tasks, including those for unmeasured resource allocations. Our approach leverages a nonparametric, conditional multi-marginal Schrödinger Bridge (MSB) formulation to generate accurate execution profiles for unseen resource contexts, with maximum likelihood guarantees. We demonstrate the efficiency and effectiveness of our approach through real-world benchmarks, and showcase its practical utility in a representative case study of adaptive multicore resource allocation for real-time systems.
Guidance with Spherical Gaussian Constraint for Conditional Diffusion
Feb 05, 2024



Recent advances in diffusion models attempt to handle conditional generative tasks by utilizing a differentiable loss function for guidance without the need for additional training. While these methods achieved certain success, they often compromise on sample quality and require small guidance step sizes, leading to longer sampling processes. This paper reveals that the fundamental issue lies in the manifold deviation during the sampling process when loss guidance is employed. We theoretically show the existence of manifold deviation by establishing a certain lower bound for the estimation error of the loss guidance. To mitigate this problem, we propose Diffusion with Spherical Gaussian constraint (DSG), drawing inspiration from the concentration phenomenon in high-dimensional Gaussian distributions. DSG effectively constrains the guidance step within the intermediate data manifold through optimization and enables the use of larger guidance steps. Furthermore, we present a closed-form solution for DSG denoising with the Spherical Gaussian constraint. Notably, DSG can seamlessly integrate as a plugin module within existing training-free conditional diffusion methods. Implementing DSG merely involves a few lines of additional code with almost no extra computational overhead, yet it leads to significant performance improvements. Comprehensive experimental results in various conditional generation tasks validate the superiority and adaptability of DSG in terms of both sample quality and time efficiency.
On the Impact of Interruptions During Multi-Robot Supervision Tasks
Jun 28, 2023Human supervisors in multi-robot systems are primarily responsible for monitoring robots, but can also be assigned with secondary tasks. These tasks can act as interruptions and can be categorized as either intrinsic, i.e., being directly related to the monitoring task, or extrinsic, i.e., being unrelated. In this paper, we investigate the impact of these two types of interruptions through a user study ($N=39$), where participants monitor a number of remote mobile robots while intermittently being interrupted by either a robot fault correction task (intrinsic) or a messaging task (extrinsic). We find that task performance of participants does not change significantly with the interruptions but depends greatly on the number of robots. However, interruptions result in an increase in perceived workload, and extrinsic interruptions have a more negative effect on workload across all NASA-TLX scales. Participants also reported switching between extrinsic interruptions and the primary task to be more difficult compared to the intrinsic interruption case. Statistical significance of these results is confirmed using ANOVA and one-sample t-test. These findings suggest that when deciding task assignment in such supervision systems, one should limit interruptions from secondary tasks, especially extrinsic ones, in order to limit user workload.
Scheduling Operator Assistance for Shared Autonomy in Multi-Robot Teams
Sep 07, 2022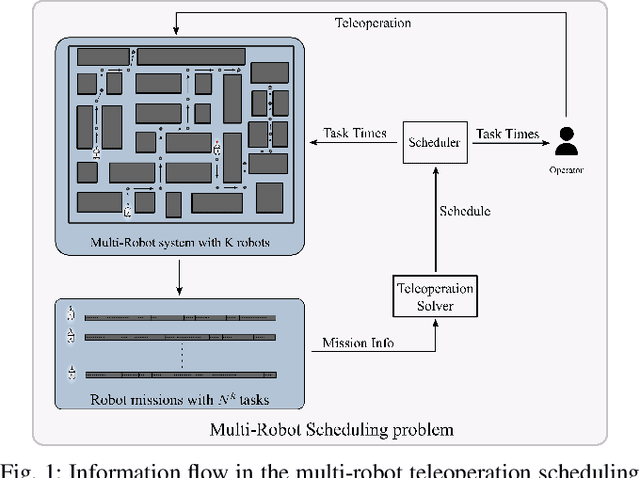
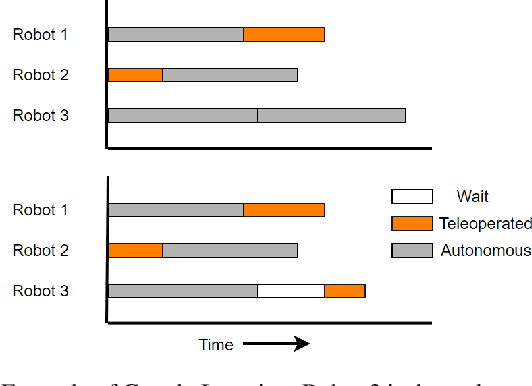
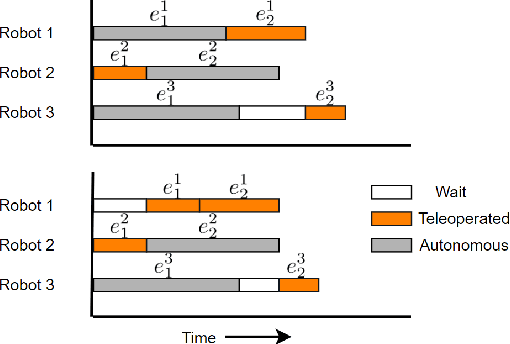
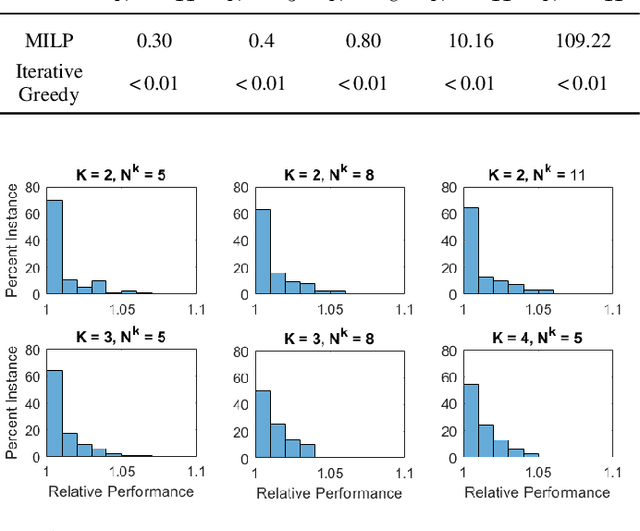
In this paper, we consider the problem of allocating human operator assistance in a system with multiple autonomous robots. Each robot is required to complete independent missions, each defined as a sequence of tasks. While executing a task, a robot can either operate autonomously or be teleoperated by the human operator to complete the task at a faster rate. We show that the problem of creating a teleoperation schedule that minimizes makespan of the system is NP-Hard. We formulate our problem as a Mixed Integer Linear Program, which can be used to optimally solve small to moderate sized problem instances. We also develop an anytime algorithm that makes use of the problem structure to provide a fast and high-quality solution of the operator scheduling problem, even for larger problem instances. Our key insight is to identify blocking tasks in greedily-created schedules and iteratively remove those blocks to improve the quality of the solution. Through numerical simulations, we demonstrate the benefits of the proposed algorithm as an efficient and scalable approach that outperforms other greedy methods.
Self-supervised Contrastive Video-Speech Representation Learning for Ultrasound
Aug 14, 2020


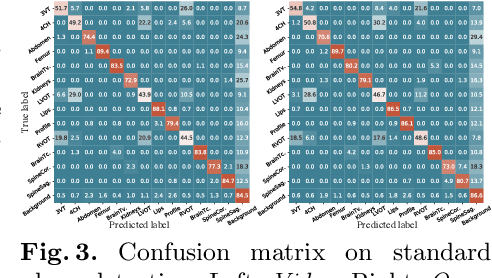
In medical imaging, manual annotations can be expensive to acquire and sometimes infeasible to access, making conventional deep learning-based models difficult to scale. As a result, it would be beneficial if useful representations could be derived from raw data without the need for manual annotations. In this paper, we propose to address the problem of self-supervised representation learning with multi-modal ultrasound video-speech raw data. For this case, we assume that there is a high correlation between the ultrasound video and the corresponding narrative speech audio of the sonographer. In order to learn meaningful representations, the model needs to identify such correlation and at the same time understand the underlying anatomical features. We designed a framework to model the correspondence between video and audio without any kind of human annotations. Within this framework, we introduce cross-modal contrastive learning and an affinity-aware self-paced learning scheme to enhance correlation modelling. Experimental evaluations on multi-modal fetal ultrasound video and audio show that the proposed approach is able to learn strong representations and transfers well to downstream tasks of standard plane detection and eye-gaze prediction.
Ultrasound Image Representation Learning by Modeling Sonographer Visual Attention
Mar 07, 2019Image representations are commonly learned from class labels, which are a simplistic approximation of human image understanding. In this paper we demonstrate that transferable representations of images can be learned without manual annotations by modeling human visual attention. The basis of our analyses is a unique gaze tracking dataset of sonographers performing routine clinical fetal anomaly screenings. Models of sonographer visual attention are learned by training a convolutional neural network (CNN) to predict gaze on ultrasound video frames through visual saliency prediction or gaze-point regression. We evaluate the transferability of the learned representations to the task of ultrasound standard plane detection in two contexts. Firstly, we perform transfer learning by fine-tuning the CNN with a limited number of labeled standard plane images. We find that fine-tuning the saliency predictor is superior to training from random initialization, with an average F1-score improvement of 9.6% overall and 15.3% for the cardiac planes. Secondly, we train a simple softmax regression on the feature activations of each CNN layer in order to evaluate the representations independently of transfer learning hyper-parameters. We find that the attention models derive strong representations, approaching the precision of a fully-supervised baseline model for all but the last layer.