 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperience-Guided Self-Adaptive Cascaded Agents for Breast Cancer Screening and Diagnosis with Reduced Biopsy Referrals
Feb 27, 2026We propose an experience-guided cascaded multi-agent framework for Breast Ultrasound Screening and Diagnosis, called BUSD-Agent, that aims to reduce diagnostic escalation and unnecessary biopsy referrals. Our framework models screening and diagnosis as a two-stage, selective decision-making process. A lightweight `screening clinic' agent, restricted to classification models as tools, selectively filters out benign and normal cases from further diagnostic escalation when malignancy risk and uncertainty are estimated as low. Cases that have higher risks are escalated to the `diagnostic clinic' agent, which integrates richer perception and radiological description tools to make a secondary decision on biopsy referral. To improve agent performance, past records of pathology-confirmed outcomes along with image embeddings, model predictions, and historical agent actions are stored in a memory bank as structured decision trajectories. For each new case, BUSD-Agent retrieves similar past cases based on image, model response and confidence similarity to condition the agent's current decision policy. This enables retrieval-conditioned in-context adaptation that dynamically adjusts model trust and escalation thresholds from prior experiences without parameter updates. Evaluation across 10 breast ultrasound datasets shows that the proposed experience-guided workflow reduces diagnostic escalation in BUSD-Agent from 84.95% to 58.72% and overall biopsy referrals from 59.50% to 37.08%, compared to the same architecture without trajectory conditioning, while improving average screening specificity by 68.48% and diagnostic specificity by 6.33%.
Picking the Right Specialist: Attentive Neural Process-based Selection of Task-Specialized Models as Tools for Agentic Healthcare Systems
Feb 16, 2026Task-specialized models form the backbone of agentic healthcare systems, enabling the agents to answer clinical queries across tasks such as disease diagnosis, localization, and report generation. Yet, for a given task, a single "best" model rarely exists. In practice, each task is better served by multiple competing specialist models where different models excel on different data samples. As a result, for any given query, agents must reliably select the right specialist model from a heterogeneous pool of tool candidates. To this end, we introduce ToolSelect, which adaptively learns model selection for tools by minimizing a population risk over sampled specialist tool candidates using a consistent surrogate of the task-conditional selection loss. Concretely, we propose an Attentive Neural Process-based selector conditioned on the query and per-model behavioral summaries to choose among the specialist models. Motivated by the absence of any established testbed, we, for the first time, introduce an agentic Chest X-ray environment equipped with a diverse suite of task-specialized models (17 disease detection, 19 report generation, 6 visual grounding, and 13 VQA) and develop ToolSelectBench, a benchmark of 1448 queries. Our results demonstrate that ToolSelect consistently outperforms 10 SOTA methods across four different task families.
Show from Tell: Audio-Visual Modelling in Clinical Settings
Oct 25, 2023


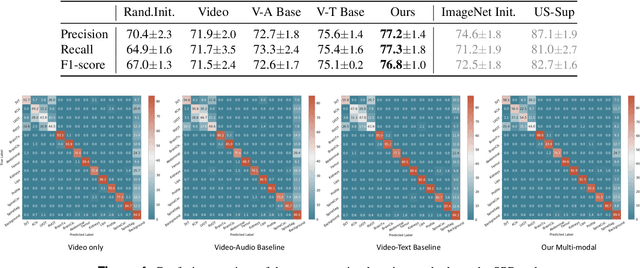
Auditory and visual signals usually present together and correlate with each other, not only in natural environments but also in clinical settings. However, the audio-visual modelling in the latter case can be more challenging, due to the different sources of audio/video signals and the noise (both signal-level and semantic-level) in auditory signals -- usually speech. In this paper, we consider audio-visual modelling in a clinical setting, providing a solution to learn medical representations that benefit various clinical tasks, without human expert annotation. A simple yet effective multi-modal self-supervised learning framework is proposed for this purpose. The proposed approach is able to localise anatomical regions of interest during ultrasound imaging, with only speech audio as a reference. Experimental evaluations on a large-scale clinical multi-modal ultrasound video dataset show that the proposed self-supervised method learns good transferable anatomical representations that boost the performance of automated downstream clinical tasks, even outperforming fully-supervised solutions.
An Experience Report of Executive-Level Artificial Intelligence Education in the United Arab Emirates
Feb 02, 2022

Teaching artificial intelligence (AI) is challenging. It is a fast moving field and therefore difficult to keep people updated with the state-of-the-art. Educational offerings for students are ever increasing, beyond university degree programs where AI education traditionally lay. In this paper, we present an experience report of teaching an AI course to business executives in the United Arab Emirates (UAE). Rather than focusing only on theoretical and technical aspects, we developed a course that teaches AI with a view to enabling students to understand how to incorporate it into existing business processes. We present an overview of our course, curriculum and teaching methods, and we discuss our reflections on teaching adult learners, and to students in the UAE.
Self-supervised Contrastive Video-Speech Representation Learning for Ultrasound
Aug 14, 2020


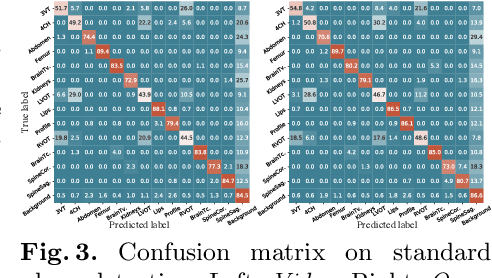
In medical imaging, manual annotations can be expensive to acquire and sometimes infeasible to access, making conventional deep learning-based models difficult to scale. As a result, it would be beneficial if useful representations could be derived from raw data without the need for manual annotations. In this paper, we propose to address the problem of self-supervised representation learning with multi-modal ultrasound video-speech raw data. For this case, we assume that there is a high correlation between the ultrasound video and the corresponding narrative speech audio of the sonographer. In order to learn meaningful representations, the model needs to identify such correlation and at the same time understand the underlying anatomical features. We designed a framework to model the correspondence between video and audio without any kind of human annotations. Within this framework, we introduce cross-modal contrastive learning and an affinity-aware self-paced learning scheme to enhance correlation modelling. Experimental evaluations on multi-modal fetal ultrasound video and audio show that the proposed approach is able to learn strong representations and transfers well to downstream tasks of standard plane detection and eye-gaze prediction.