 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Image and Video Saliency Modeling
Paper and Code
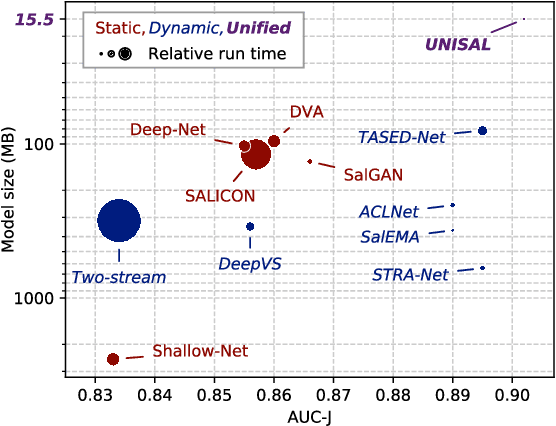

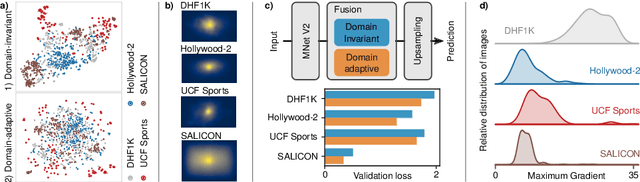
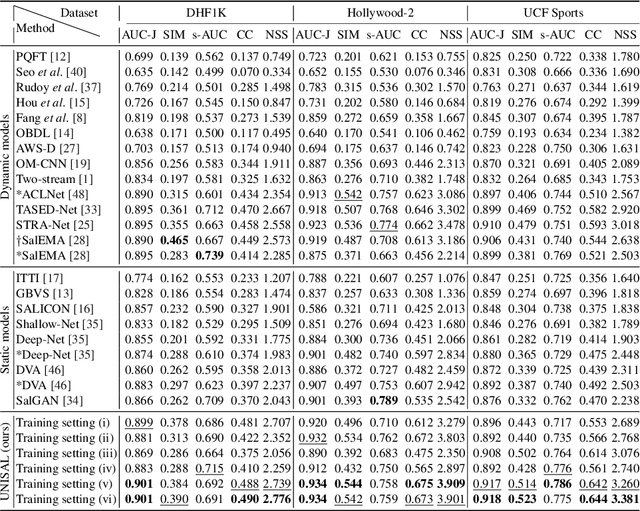
Visual saliency modeling for images and videos is treated as two independent tasks in recent computer vision literature. On the one hand, image saliency modeling is a well-studied problem and progress on benchmarks like \mbox{SALICON} and MIT300 is slowing. For video saliency prediction on the other hand, rapid gains have been achieved on the recent DHF1K benchmark through network architectures that are optimized for this task. Here, we take a step back and ask: Can image and video saliency modeling be approached via a unified model, with mutual benefit? We find that it is crucial to model the domain shift between image and video saliency data and between different video saliency datasets for effective joint modeling. We identify different sources of domain shift and address them through four novel domain adaptation techniques - Domain-Adaptive Priors, Domain-Adaptive Fusion, Domain-Adaptive Smoothing and Bypass-RNN - in addition to an improved formulation of learned Gaussian priors. We integrate these techniques into a simple and lightweight encoder-RNN-decoder-style network, UNISAL, and train the entire network simultaneously with image and video saliency data. We evaluate our method on the video saliency datasets DHF1K, Hollywood-2 and UCF-Sports, as well as the image saliency datasets SALICON and MIT300. With one set of parameters, our method achieves state-of-the-art performance on all video saliency datasets and is on par with the state-of-the-art for image saliency prediction, despite a 5 to 20-fold reduction in model size and the fastest runtime among all competing deep models. We provide retrospective analyses and ablation studies which demonstrate the importance of the domain shift modeling. The code is available at https://github.com/rdroste/unisal.