 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Aligned CLIP for Few-shot Classification
Nov 15, 2023Large vision-language representation learning models like CLIP have demonstrated impressive performance for zero-shot transfer to downstream tasks while largely benefiting from inter-modal (image-text) alignment via contrastive objectives. This downstream performance can further be enhanced by full-scale fine-tuning which is often compute intensive, requires large labelled data, and can reduce out-of-distribution (OOD) robustness. Furthermore, sole reliance on inter-modal alignment might overlook the rich information embedded within each individual modality. In this work, we introduce a sample-efficient domain adaptation strategy for CLIP, termed Domain Aligned CLIP (DAC), which improves both intra-modal (image-image) and inter-modal alignment on target distributions without fine-tuning the main model. For intra-modal alignment, we introduce a lightweight adapter that is specifically trained with an intra-modal contrastive objective. To improve inter-modal alignment, we introduce a simple framework to modulate the precomputed class text embeddings. The proposed few-shot fine-tuning framework is computationally efficient, robust to distribution shifts, and does not alter CLIP's parameters. We study the effectiveness of DAC by benchmarking on 11 widely used image classification tasks with consistent improvements in 16-shot classification upon strong baselines by about 2.3% and demonstrate competitive performance on 4 OOD robustness benchmarks.
Deep Video Deblurring: The Devil is in the Details
Sep 26, 2019
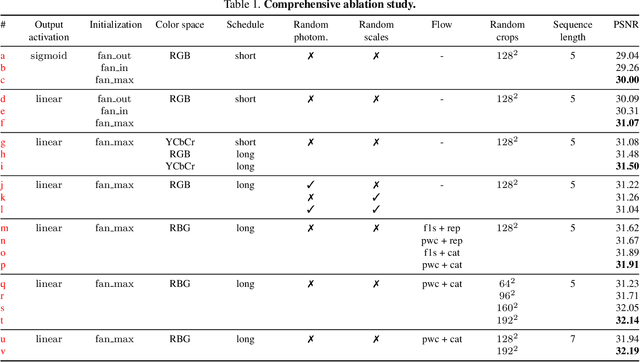
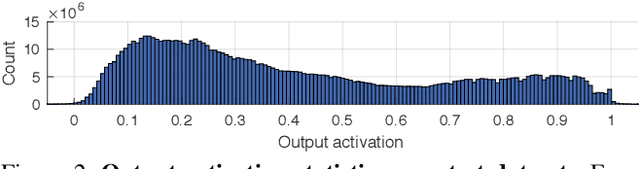
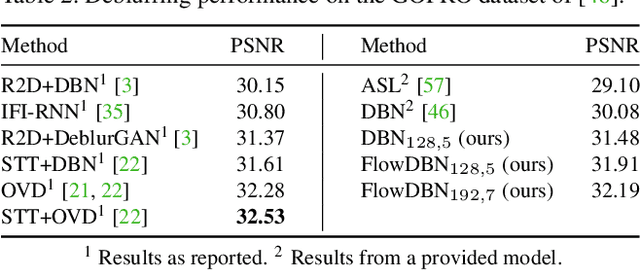
Video deblurring for hand-held cameras is a challenging task, since the underlying blur is caused by both camera shake and object motion. State-of-the-art deep networks exploit temporal information from neighboring frames, either by means of spatio-temporal transformers or by recurrent architectures. In contrast to these involved models, we found that a simple baseline CNN can perform astonishingly well when particular care is taken w.r.t. the details of model and training procedure. To that end, we conduct a comprehensive study regarding these crucial details, uncovering extreme differences in quantitative and qualitative performance. Exploiting these details allows us to boost the architecture and training procedure of a simple baseline CNN by a staggering 3.15dB, such that it becomes highly competitive w.r.t. cutting-edge networks. This raises the question whether the reported accuracy difference between models is always due to technical contributions or also subject to such orthogonal, but crucial details.
Lightweight Probabilistic Deep Networks
May 29, 2018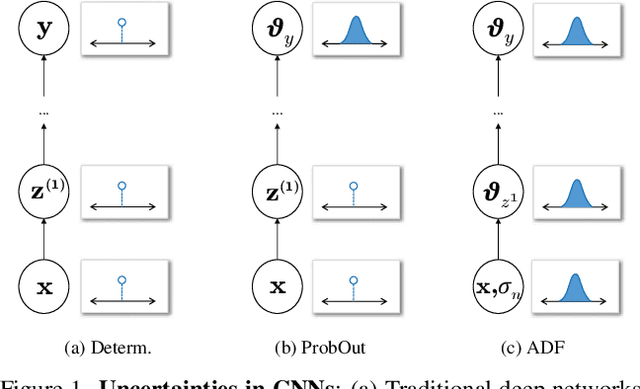
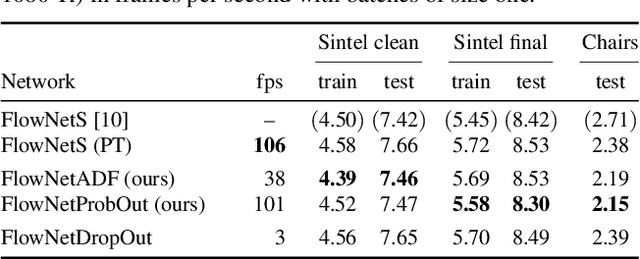


Even though probabilistic treatments of neural networks have a long history, they have not found widespread use in practice. Sampling approaches are often too slow already for simple networks. The size of the inputs and the depth of typical CNN architectures in computer vision only compound this problem. Uncertainty in neural networks has thus been largely ignored in practice, despite the fact that it may provide important information about the reliability of predictions and the inner workings of the network. In this paper, we introduce two lightweight approaches to making supervised learning with probabilistic deep networks practical: First, we suggest probabilistic output layers for classification and regression that require only minimal changes to existing networks. Second, we employ assumed density filtering and show that activation uncertainties can be propagated in a practical fashion through the entire network, again with minor changes. Both probabilistic networks retain the predictive power of the deterministic counterpart, but yield uncertainties that correlate well with the empirical error induced by their predictions. Moreover, the robustness to adversarial examples is significantly increased.
Parametric Object Motion from Blur
Apr 20, 2016


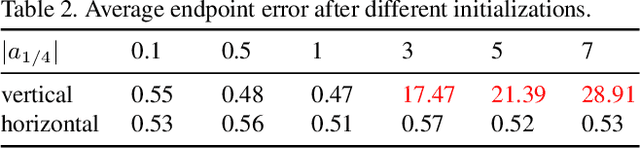
Motion blur can adversely affect a number of vision tasks, hence it is generally considered a nuisance. We instead treat motion blur as a useful signal that allows to compute the motion of objects from a single image. Drawing on the success of joint segmentation and parametric motion models in the context of optical flow estimation, we propose a parametric object motion model combined with a segmentation mask to exploit localized, non-uniform motion blur. Our parametric image formation model is differentiable w.r.t. the motion parameters, which enables us to generalize marginal-likelihood techniques from uniform blind deblurring to localized, non-uniform blur. A two-stage pipeline, first in derivative space and then in image space, allows to estimate both parametric object motion as well as a motion segmentation from a single image alone. Our experiments demonstrate its ability to cope with very challenging cases of object motion blur.