 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoldiCLIP: The Goldilocks Approach for Balancing Explicit Supervision for Language-Image Pretraining
Mar 25, 2026Until recently, the success of large-scale vision-language models (VLMs) has primarily relied on billion-sample datasets, posing a significant barrier to progress. Latest works have begun to close this gap by improving supervision quality, but each addresses only a subset of the weaknesses in contrastive pretraining. We present GoldiCLIP, a framework built on a Goldilocks principle of finding the right balance of supervision signals. Our multifaceted training framework synergistically combines three key innovations: (1) a text-conditioned self-distillation method to align both text-agnostic and text-conditioned features; (2) an encoder integrated decoder with Visual Question Answering (VQA) objective that enables the encoder to generalize beyond the caption-like queries; and (3) an uncertainty-based weighting mechanism that automatically balances all heterogeneous losses. Trained on just 30 million images, 300x less data than leading methods, GoldiCLIP achieves state-of-the-art among data-efficient approaches, improving over the best comparable baseline by 2.2 points on MSCOCO retrieval, 2.0 on fine-grained retrieval, and 5.9 on question-based retrieval, while remaining competitive with billion-scale models. Project page: https://petsi.uk/goldiclip.
ARGENT: Adaptive Hierarchical Image-Text Representations
Mar 24, 2026Large-scale Vision-Language Models (VLMs) such as CLIP learn powerful semantic representations but operate in Euclidean space, which fails to capture the inherent hierarchical structure of visual and linguistic concepts. Hyperbolic geometry, with its exponential volume growth, offers a principled alternative for embedding such hierarchies with low distortion. However, existing hyperbolic VLMs use entailment losses that are unstable: as parent embeddings contract toward the origin, their entailment cones widen toward a half-space, causing catastrophic cone collapse that destroys the intended hierarchy. Additionally, hierarchical evaluation of these models remains unreliable, being largely retrieval-based and correlation-based metrics and prone to taxonomy dependence and ambiguous negatives. To address these limitations, we propose an adaptive entailment loss paired with a norm regularizer that prevents cone collapse without heuristic aperture clipping. We further introduce an angle-based probabilistic entailment protocol (PEP) for evaluating hierarchical understanding, scored with AUC-ROC and Average Precision. This paper introduces a stronger hyperbolic VLM baseline ARGENT, Adaptive hieRarchical imaGe-tExt represeNTation. ARGENT improves the SOTA hyperbolic VLM by 0.7, 1.1, and 0.8 absolute points on image classification, text-to-image retrieval, and proposed hierarchical metrics, respectively.
Qonvolution: Towards Learning High-Frequency Signals with Queried Convolution
Dec 15, 2025Accurately learning high-frequency signals is a challenge in computer vision and graphics, as neural networks often struggle with these signals due to spectral bias or optimization difficulties. While current techniques like Fourier encodings have made great strides in improving performance, there remains scope for improvement when presented with high-frequency information. This paper introduces Queried-Convolutions (Qonvolutions), a simple yet powerful modification using the neighborhood properties of convolution. Qonvolution convolves a low-frequency signal with queries (such as coordinates) to enhance the learning of intricate high-frequency signals. We empirically demonstrate that Qonvolutions enhance performance across a variety of high-frequency learning tasks crucial to both the computer vision and graphics communities, including 1D regression, 2D super-resolution, 2D image regression, and novel view synthesis (NVS). In particular, by combining Gaussian splatting with Qonvolutions for NVS, we showcase state-of-the-art performance on real-world complex scenes, even outperforming powerful radiance field models on image quality.
ADIEE: Automatic Dataset Creation and Scorer for Instruction-Guided Image Editing Evaluation
Jul 09, 2025



Recent advances in instruction-guided image editing underscore the need for effective automated evaluation. While Vision-Language Models (VLMs) have been explored as judges, open-source models struggle with alignment, and proprietary models lack transparency and cost efficiency. Additionally, no public training datasets exist to fine-tune open-source VLMs, only small benchmarks with diverse evaluation schemes. To address this, we introduce ADIEE, an automated dataset creation approach which is then used to train a scoring model for instruction-guided image editing evaluation. We generate a large-scale dataset with over 100K samples and use it to fine-tune a LLaVA-NeXT-8B model modified to decode a numeric score from a custom token. The resulting scorer outperforms all open-source VLMs and Gemini-Pro 1.5 across all benchmarks, achieving a 0.0696 (+17.24%) gain in score correlation with human ratings on AURORA-Bench, and improving pair-wise comparison accuracy by 4.03% (+7.21%) on GenAI-Bench and 4.75% (+9.35%) on AURORA-Bench, respectively, compared to the state-of-the-art. The scorer can act as a reward model, enabling automated best edit selection and model fine-tuning. Notably, the proposed scorer can boost MagicBrush model's average evaluation score on ImagenHub from 5.90 to 6.43 (+8.98%).
Diffuse to Choose: Enriching Image Conditioned Inpainting in Latent Diffusion Models for Virtual Try-All
Jan 24, 2024As online shopping is growing, the ability for buyers to virtually visualize products in their settings-a phenomenon we define as "Virtual Try-All"-has become crucial. Recent diffusion models inherently contain a world model, rendering them suitable for this task within an inpainting context. However, traditional image-conditioned diffusion models often fail to capture the fine-grained details of products. In contrast, personalization-driven models such as DreamPaint are good at preserving the item's details but they are not optimized for real-time applications. We present "Diffuse to Choose," a novel diffusion-based image-conditioned inpainting model that efficiently balances fast inference with the retention of high-fidelity details in a given reference item while ensuring accurate semantic manipulations in the given scene content. Our approach is based on incorporating fine-grained features from the reference image directly into the latent feature maps of the main diffusion model, alongside with a perceptual loss to further preserve the reference item's details. We conduct extensive testing on both in-house and publicly available datasets, and show that Diffuse to Choose is superior to existing zero-shot diffusion inpainting methods as well as few-shot diffusion personalization algorithms like DreamPaint.
Domain Aligned CLIP for Few-shot Classification
Nov 15, 2023Large vision-language representation learning models like CLIP have demonstrated impressive performance for zero-shot transfer to downstream tasks while largely benefiting from inter-modal (image-text) alignment via contrastive objectives. This downstream performance can further be enhanced by full-scale fine-tuning which is often compute intensive, requires large labelled data, and can reduce out-of-distribution (OOD) robustness. Furthermore, sole reliance on inter-modal alignment might overlook the rich information embedded within each individual modality. In this work, we introduce a sample-efficient domain adaptation strategy for CLIP, termed Domain Aligned CLIP (DAC), which improves both intra-modal (image-image) and inter-modal alignment on target distributions without fine-tuning the main model. For intra-modal alignment, we introduce a lightweight adapter that is specifically trained with an intra-modal contrastive objective. To improve inter-modal alignment, we introduce a simple framework to modulate the precomputed class text embeddings. The proposed few-shot fine-tuning framework is computationally efficient, robust to distribution shifts, and does not alter CLIP's parameters. We study the effectiveness of DAC by benchmarking on 11 widely used image classification tasks with consistent improvements in 16-shot classification upon strong baselines by about 2.3% and demonstrate competitive performance on 4 OOD robustness benchmarks.
Image-Text Pre-Training for Logo Recognition
Sep 18, 2023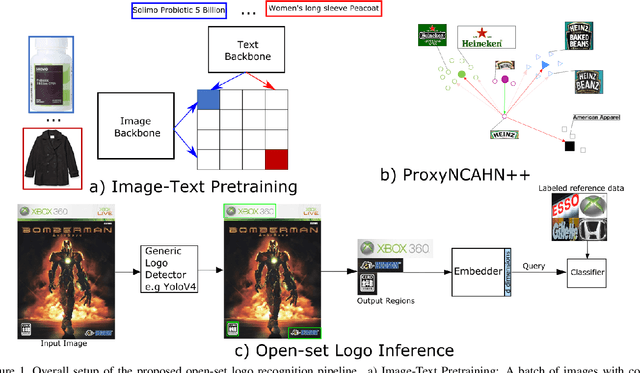
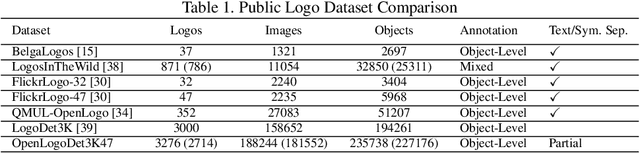


Open-set logo recognition is commonly solved by first detecting possible logo regions and then matching the detected parts against an ever-evolving dataset of cropped logo images. The matching model, a metric learning problem, is especially challenging for logo recognition due to the mixture of text and symbols in logos. We propose two novel contributions to improve the matching model's performance: (a) using image-text paired samples for pre-training, and (b) an improved metric learning loss function. A standard paradigm of fine-tuning ImageNet pre-trained models fails to discover the text sensitivity necessary to solve the matching problem effectively. This work demonstrates the importance of pre-training on image-text pairs, which significantly improves the performance of a visual embedder trained for the logo retrieval task, especially for more text-dominant classes. We construct a composite public logo dataset combining LogoDet3K, OpenLogo, and FlickrLogos-47 deemed OpenLogoDet3K47. We show that the same vision backbone pre-trained on image-text data, when fine-tuned on OpenLogoDet3K47, achieves $98.6\%$ recall@1, significantly improving performance over pre-training on Imagenet1K ($97.6\%$). We generalize the ProxyNCA++ loss function to propose ProxyNCAHN++ which incorporates class-specific hard negative images. The proposed method sets new state-of-the-art on five public logo datasets considered, with a $3.5\%$ zero-shot recall@1 improvement on LogoDet3K test, $4\%$ on OpenLogo, $6.5\%$ on FlickrLogos-47, $6.2\%$ on Logos In The Wild, and $0.6\%$ on BelgaLogo.
* 8 pages, 5 figures, 4 tables
DreamPaint: Few-Shot Inpainting of E-Commerce Items for Virtual Try-On without 3D Modeling
May 02, 2023We introduce DreamPaint, a framework to intelligently inpaint any e-commerce product on any user-provided context image. The context image can be, for example, the user's own image for virtual try-on of clothes from the e-commerce catalog on themselves, the user's room image for virtual try-on of a piece of furniture from the e-commerce catalog in their room, etc. As opposed to previous augmented-reality (AR)-based virtual try-on methods, DreamPaint does not use, nor does it require, 3D modeling of neither the e-commerce product nor the user context. Instead, it directly uses 2D images of the product as available in product catalog database, and a 2D picture of the context, for example taken from the user's phone camera. The method relies on few-shot fine tuning a pre-trained diffusion model with the masked latents (e.g., Masked DreamBooth) of the catalog images per item, whose weights are then loaded on a pre-trained inpainting module that is capable of preserving the characteristics of the context image. DreamPaint allows to preserve both the product image and the context (environment/user) image without requiring text guidance to describe the missing part (product/context). DreamPaint also allows to intelligently infer the best 3D angle of the product to place at the desired location on the user context, even if that angle was previously unseen in the product's reference 2D images. We compare our results against both text-guided and image-guided inpainting modules and show that DreamPaint yields superior performance in both subjective human study and quantitative metrics.
Spatiotemporal Articulated Models for Dynamic SLAM
Apr 12, 2016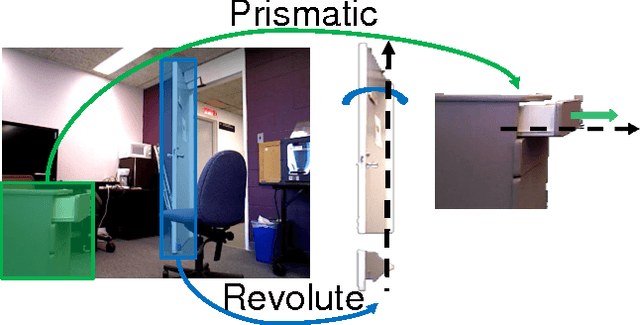
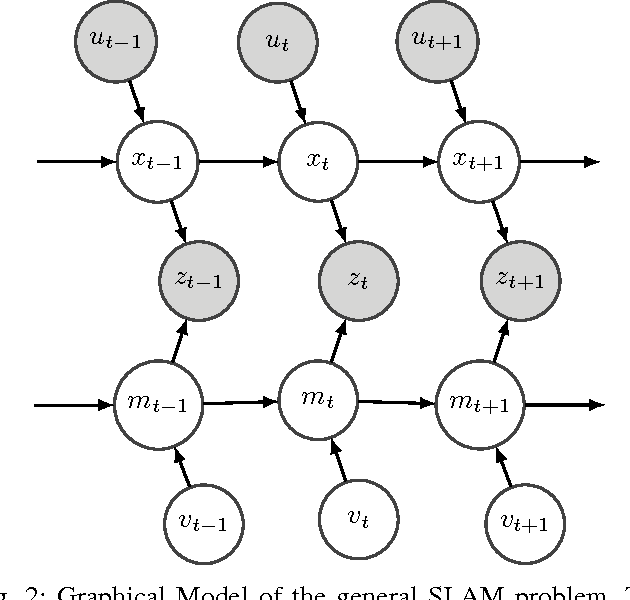
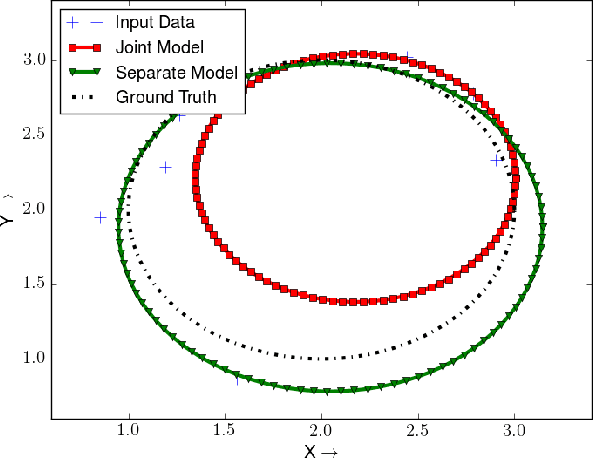

We propose an online spatiotemporal articulation model estimation framework that estimates both articulated structure as well as a temporal prediction model solely using passive observations. The resulting model can predict future mo- tions of an articulated object with high confidence because of the spatial and temporal structure. We demonstrate the effectiveness of the predictive model by incorporating it within a standard simultaneous localization and mapping (SLAM) pipeline for mapping and robot localization in previously unexplored dynamic environments. Our method is able to localize the robot and map a dynamic scene by explaining the observed motion in the world. We demonstrate the effectiveness of the proposed framework for both simulated and real-world dynamic environments.