 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-Text Pre-Training for Logo Recognition
Sep 18, 2023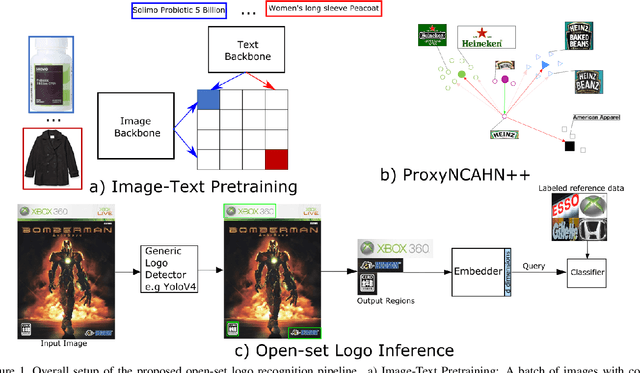


Open-set logo recognition is commonly solved by first detecting possible logo regions and then matching the detected parts against an ever-evolving dataset of cropped logo images. The matching model, a metric learning problem, is especially challenging for logo recognition due to the mixture of text and symbols in logos. We propose two novel contributions to improve the matching model's performance: (a) using image-text paired samples for pre-training, and (b) an improved metric learning loss function. A standard paradigm of fine-tuning ImageNet pre-trained models fails to discover the text sensitivity necessary to solve the matching problem effectively. This work demonstrates the importance of pre-training on image-text pairs, which significantly improves the performance of a visual embedder trained for the logo retrieval task, especially for more text-dominant classes. We construct a composite public logo dataset combining LogoDet3K, OpenLogo, and FlickrLogos-47 deemed OpenLogoDet3K47. We show that the same vision backbone pre-trained on image-text data, when fine-tuned on OpenLogoDet3K47, achieves $98.6\%$ recall@1, significantly improving performance over pre-training on Imagenet1K ($97.6\%$). We generalize the ProxyNCA++ loss function to propose ProxyNCAHN++ which incorporates class-specific hard negative images. The proposed method sets new state-of-the-art on five public logo datasets considered, with a $3.5\%$ zero-shot recall@1 improvement on LogoDet3K test, $4\%$ on OpenLogo, $6.5\%$ on FlickrLogos-47, $6.2\%$ on Logos In The Wild, and $0.6\%$ on BelgaLogo.
* 8 pages, 5 figures, 4 tables
Statistically adaptive learning for a general class of cost functions (SA L-BFGS)
Sep 05, 2012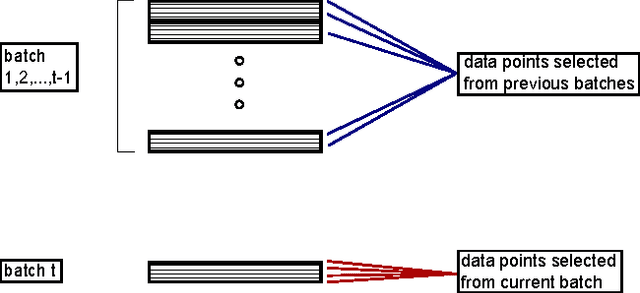
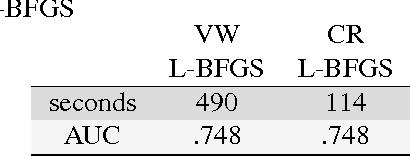
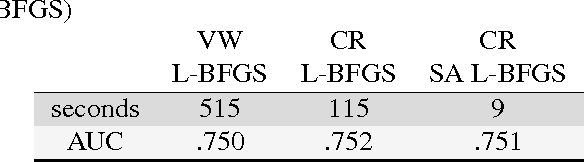
We present a system that enables rapid model experimentation for tera-scale machine learning with trillions of non-zero features, billions of training examples, and millions of parameters. Our contribution to the literature is a new method (SA L-BFGS) for changing batch L-BFGS to perform in near real-time by using statistical tools to balance the contributions of previous weights, old training examples, and new training examples to achieve fast convergence with few iterations. The result is, to our knowledge, the most scalable and flexible linear learning system reported in the literature, beating standard practice with the current best system (Vowpal Wabbit and AllReduce). Using the KDD Cup 2012 data set from Tencent, Inc. we provide experimental results to verify the performance of this method.