 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistically adaptive learning for a general class of cost functions (SA L-BFGS)
Paper and Code
Sep 05, 2012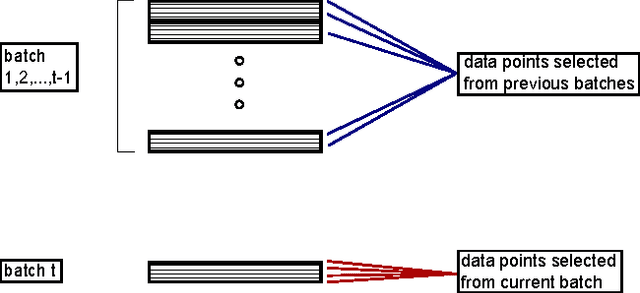
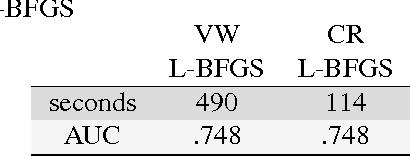
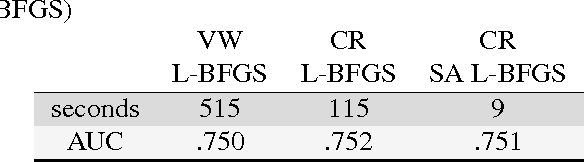
We present a system that enables rapid model experimentation for tera-scale machine learning with trillions of non-zero features, billions of training examples, and millions of parameters. Our contribution to the literature is a new method (SA L-BFGS) for changing batch L-BFGS to perform in near real-time by using statistical tools to balance the contributions of previous weights, old training examples, and new training examples to achieve fast convergence with few iterations. The result is, to our knowledge, the most scalable and flexible linear learning system reported in the literature, beating standard practice with the current best system (Vowpal Wabbit and AllReduce). Using the KDD Cup 2012 data set from Tencent, Inc. we provide experimental results to verify the performance of this method.