 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU2-BENCH: Benchmarking Large Vision-Language Models on Ultrasound Understanding
May 23, 2025Ultrasound is a widely-used imaging modality critical to global healthcare, yet its interpretation remains challenging due to its varying image quality on operators, noises, and anatomical structures. Although large vision-language models (LVLMs) have demonstrated impressive multimodal capabilities across natural and medical domains, their performance on ultrasound remains largely unexplored. We introduce U2-BENCH, the first comprehensive benchmark to evaluate LVLMs on ultrasound understanding across classification, detection, regression, and text generation tasks. U2-BENCH aggregates 7,241 cases spanning 15 anatomical regions and defines 8 clinically inspired tasks, such as diagnosis, view recognition, lesion localization, clinical value estimation, and report generation, across 50 ultrasound application scenarios. We evaluate 20 state-of-the-art LVLMs, both open- and closed-source, general-purpose and medical-specific. Our results reveal strong performance on image-level classification, but persistent challenges in spatial reasoning and clinical language generation. U2-BENCH establishes a rigorous and unified testbed to assess and accelerate LVLM research in the uniquely multimodal domain of medical ultrasound imaging.
SPA: Efficient User-Preference Alignment against Uncertainty in Medical Image Segmentation
Nov 23, 2024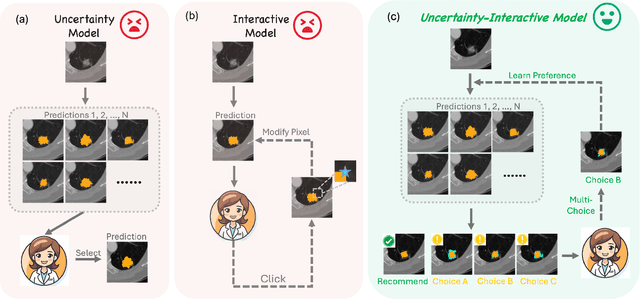
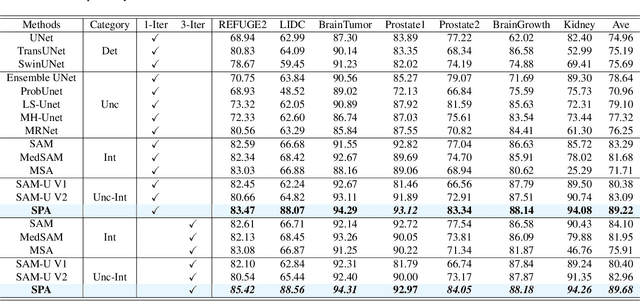
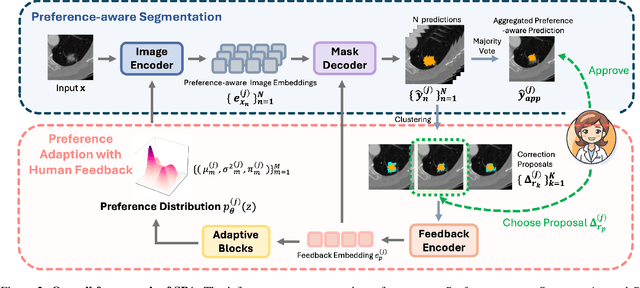

Medical image segmentation data inherently contain uncertainty, often stemming from both imperfect image quality and variability in labeling preferences on ambiguous pixels, which depend on annotators' expertise and the clinical context of the annotations. For instance, a boundary pixel might be labeled as tumor in diagnosis to avoid under-assessment of severity, but as normal tissue in radiotherapy to prevent damage to sensitive structures. As segmentation preferences vary across downstream applications, it is often desirable for an image segmentation model to offer user-adaptable predictions rather than a fixed output. While prior uncertainty-aware and interactive methods offer adaptability, they are inefficient at test time: uncertainty-aware models require users to choose from numerous similar outputs, while interactive models demand significant user input through click or box prompts to refine segmentation. To address these challenges, we propose \textbf{SPA}, a segmentation framework that efficiently adapts to diverse test-time preferences with minimal human interaction. By presenting users a select few, distinct segmentation candidates that best capture uncertainties, it reduces clinician workload in reaching the preferred segmentation. To accommodate user preference, we introduce a probabilistic mechanism that leverages user feedback to adapt model's segmentation preference. The proposed framework is evaluated on a diverse range of medical image segmentation tasks: color fundus images, CT, and MRI. It demonstrates 1) a significant reduction in clinician time and effort compared with existing interactive segmentation approaches, 2) strong adaptability based on human feedback, and 3) state-of-the-art image segmentation performance across diverse modalities and semantic labels.
Towards Human-AI Collaboration in Healthcare: Guided Deferral Systems with Large Language Models
Jun 11, 2024Large language models (LLMs) present a valuable technology for various applications in healthcare, but their tendency to hallucinate introduces unacceptable uncertainty in critical decision-making situations. Human-AI collaboration (HAIC) can mitigate this uncertainty by combining human and AI strengths for better outcomes. This paper presents a novel guided deferral system that provides intelligent guidance when AI defers cases to human decision-makers. We leverage LLMs' verbalisation capabilities and internal states to create this system, demonstrating that fine-tuning smaller LLMs with data from larger models enhances performance while maintaining computational efficiency. A pilot study showcases the effectiveness of our deferral system.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
A Dual Adversarial Calibration Framework for Automatic Fetal Brain Biometry
Aug 28, 2021


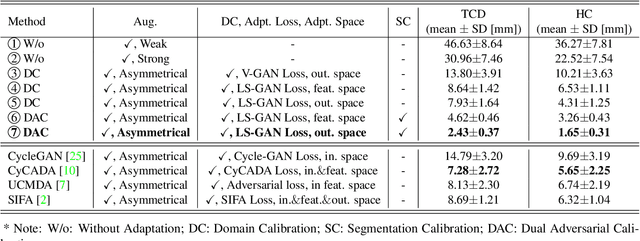
This paper presents a novel approach to automatic fetal brain biometry motivated by needs in low- and medium- income countries. Specifically, we leverage high-end (HE) ultrasound images to build a biometry solution for low-cost (LC) point-of-care ultrasound images. We propose a novel unsupervised domain adaptation approach to train deep models to be invariant to significant image distribution shift between the image types. Our proposed method, which employs a Dual Adversarial Calibration (DAC) framework, consists of adversarial pathways which enforce model invariance to; i) adversarial perturbations in the feature space derived from LC images, and ii) appearance domain discrepancy. Our Dual Adversarial Calibration method estimates transcerebellar diameter and head circumference on images from low-cost ultrasound devices with a mean absolute error (MAE) of 2.43mm and 1.65mm, compared with 7.28 mm and 5.65 mm respectively for SOTA.
Contrastive Algorithmic Fairness: Part 1 (Theory)
May 27, 2019Was it fair that Harry was hired but not Barry? Was it fair that Pam was fired instead of Sam? How to ensure fairness when an intelligent algorithm takes these decisions instead of a human? How to ensure that the decisions were taken based on merit and not on protected attributes like race or sex? These are the questions that must be answered now that many decisions in real life can be made through machine learning. However research in fairness of algorithms has focused on the counterfactual questions "what if?" or "why?", whereas in real life most subjective questions of consequence are contrastive: "why this but not that?". We introduce concepts and mathematical tools using causal inference to address contrastive fairness in algorithmic decision-making with illustrative thought examples.