 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaLoRA-QAT: Adaptive Low-Rank and Quantization-Aware Segmentation
Apr 01, 2026Chest X-ray (CXR) segmentation is an important step in computer-aided diagnosis, yet deploying large foundation models in clinical settings remains challenging due to computational constraints. We propose AdaLoRA-QAT, a two-stage fine-tuning framework that combines adaptive low-rank encoder adaptation with full quantization-aware training. Adaptive rank allocation improves parameter efficiency, while selective mixed-precision INT8 quantization preserves structural fidelity crucial for clinical reliability. Evaluated across large-scale CXR datasets, AdaLoRA-QAT achieves 95.6% Dice, matching full-precision SAM decoder fine-tuning while reducing trainable parameters by 16.6\times and yielding 2.24\times model compression. A Wilcoxon signed-rank test confirms that quantization does not significantly degrade segmentation accuracy. These results demonstrate that AdaLoRA-QAT effectively balances accuracy, efficiency, and structural trust-worthiness, enabling compact and deployable foundation models for medical image segmentation. Code and pretrained models are available at: https://prantik-pdeb.github.io/adaloraqat.github.io/
AI Generalisation Gap In Comorbid Sleep Disorder Staging
Mar 24, 2026Accurate sleep staging is essential for diagnosing OSA and hypopnea in stroke patients. Although PSG is reliable, it is costly, labor-intensive, and manually scored. While deep learning enables automated EEG-based sleep staging in healthy subjects, our analysis shows poor generalization to clinical populations with disrupted sleep. Using Grad-CAM interpretations, we systematically demonstrate this limitation. We introduce iSLEEPS, a newly clinically annotated ischemic stroke dataset (to be publicly released), and evaluate a SE-ResNet plus bidirectional LSTM model for single-channel EEG sleep staging. As expected, cross-domain performance between healthy and diseased subjects is poor. Attention visualizations, supported by clinical expert feedback, show the model focuses on physiologically uninformative EEG regions in patient data. Statistical and computational analyses further confirm significant sleep architecture differences between healthy and ischemic stroke cohorts, highlighting the need for subject-aware or disease-specific models with clinical validation before deployment. A summary of the paper and the code is available at https://himalayansaswatabose.github.io/iSLEEPS_Explainability.github.io/
Leakage and Interpretability in Concept-Based Models
Apr 18, 2025



Concept Bottleneck Models aim to improve interpretability by predicting high-level intermediate concepts, representing a promising approach for deployment in high-risk scenarios. However, they are known to suffer from information leakage, whereby models exploit unintended information encoded within the learned concepts. We introduce an information-theoretic framework to rigorously characterise and quantify leakage, and define two complementary measures: the concepts-task leakage (CTL) and interconcept leakage (ICL) scores. We show that these measures are strongly predictive of model behaviour under interventions and outperform existing alternatives in robustness and reliability. Using this framework, we identify the primary causes of leakage and provide strong evidence that Concept Embedding Models exhibit substantial leakage regardless of the hyperparameters choice. Finally, we propose practical guidelines for designing concept-based models to reduce leakage and ensure interpretability.
Conformal uncertainty quantification to evaluate predictive fairness of foundation AI model for skin lesion classes across patient demographics
Mar 31, 2025


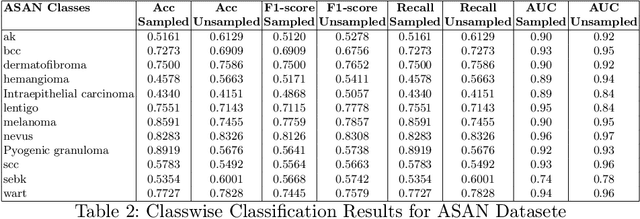
Deep learning based diagnostic AI systems based on medical images are starting to provide similar performance as human experts. However these data hungry complex systems are inherently black boxes and therefore slow to be adopted for high risk applications like healthcare. This problem of lack of transparency is exacerbated in the case of recent large foundation models, which are trained in a self supervised manner on millions of data points to provide robust generalisation across a range of downstream tasks, but the embeddings generated from them happen through a process that is not interpretable, and hence not easily trustable for clinical applications. To address this timely issue, we deploy conformal analysis to quantify the predictive uncertainty of a vision transformer (ViT) based foundation model across patient demographics with respect to sex, age and ethnicity for the tasks of skin lesion classification using several public benchmark datasets. The significant advantage of this method is that conformal analysis is method independent and it not only provides a coverage guarantee at population level but also provides an uncertainty score for each individual. We used a model-agnostic dynamic F1-score-based sampling during model training, which helped to stabilize the class imbalance and we investigate the effects on uncertainty quantification (UQ) with or without this bias mitigation step. Thus we show how this can be used as a fairness metric to evaluate the robustness of the feature embeddings of the foundation model (Google DermFoundation) and thus advance the trustworthiness and fairness of clinical AI.
Deep Learning as Ricci Flow
Apr 22, 2024Deep neural networks (DNNs) are powerful tools for approximating the distribution of complex data. It is known that data passing through a trained DNN classifier undergoes a series of geometric and topological simplifications. While some progress has been made toward understanding these transformations in neural networks with smooth activation functions, an understanding in the more general setting of non-smooth activation functions, such as the rectified linear unit (ReLU), which tend to perform better, is required. Here we propose that the geometric transformations performed by DNNs during classification tasks have parallels to those expected under Hamilton's Ricci flow - a tool from differential geometry that evolves a manifold by smoothing its curvature, in order to identify its topology. To illustrate this idea, we present a computational framework to quantify the geometric changes that occur as data passes through successive layers of a DNN, and use this framework to motivate a notion of `global Ricci network flow' that can be used to assess a DNN's ability to disentangle complex data geometries to solve classification problems. By training more than $1,500$ DNN classifiers of different widths and depths on synthetic and real-world data, we show that the strength of global Ricci network flow-like behaviour correlates with accuracy for well-trained DNNs, independently of depth, width and data set. Our findings motivate the use of tools from differential and discrete geometry to the problem of explainability in deep learning.
Learning from data with structured missingness
Apr 04, 2023Missing data are an unavoidable complication in many machine learning tasks. When data are `missing at random' there exist a range of tools and techniques to deal with the issue. However, as machine learning studies become more ambitious, and seek to learn from ever-larger volumes of heterogeneous data, an increasingly encountered problem arises in which missing values exhibit an association or structure, either explicitly or implicitly. Such `structured missingness' raises a range of challenges that have not yet been systematically addressed, and presents a fundamental hindrance to machine learning at scale. Here, we outline the current literature and propose a set of grand challenges in learning from data with structured missingness.
Contrastive Algorithmic Fairness: Part 1 (Theory)
May 27, 2019Was it fair that Harry was hired but not Barry? Was it fair that Pam was fired instead of Sam? How to ensure fairness when an intelligent algorithm takes these decisions instead of a human? How to ensure that the decisions were taken based on merit and not on protected attributes like race or sex? These are the questions that must be answered now that many decisions in real life can be made through machine learning. However research in fairness of algorithms has focused on the counterfactual questions "what if?" or "why?", whereas in real life most subjective questions of consequence are contrastive: "why this but not that?". We introduce concepts and mathematical tools using causal inference to address contrastive fairness in algorithmic decision-making with illustrative thought examples.
Distance Metric Learned Collaborative Representation Classifier
May 03, 2019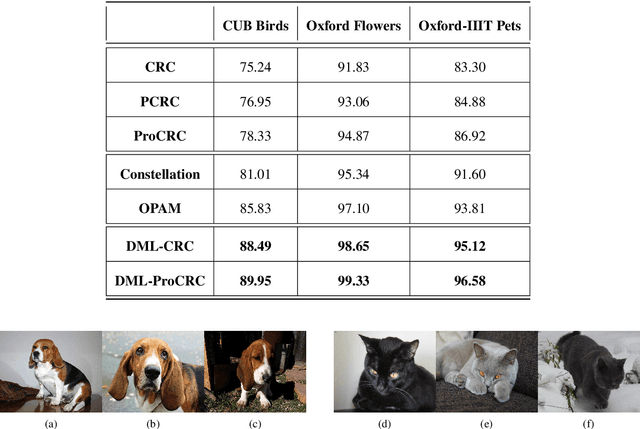
Any generic deep machine learning algorithm is essentially a function fitting exercise, where the network tunes its weights and parameters to learn discriminatory features by minimizing some cost function. Though the network tries to learn the optimal feature space, it seldom tries to learn an optimal distance metric in the cost function, and hence misses out on an additional layer of abstraction. We present a simple effective way of achieving this by learning a generic Mahalanabis distance in a collaborative loss function in an end-to-end fashion with any standard convolutional network as the feature learner. The proposed method DML-CRC gives state-of-the-art performance on benchmark fine-grained classification datasets CUB Birds, Oxford Flowers and Oxford-IIIT Pets using the VGG-19 deep network. The method is network agnostic and can be used for any similar classification tasks.
PProCRC: Probabilistic Collaboration of Image Patches
Mar 21, 2019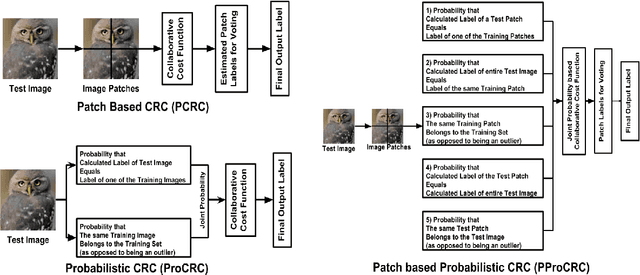
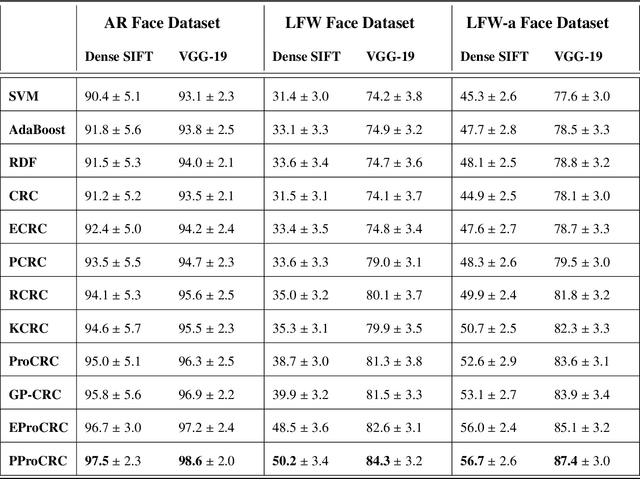

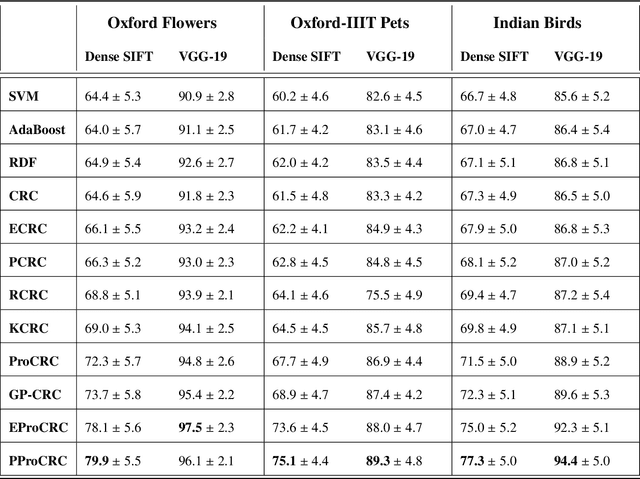
We present a conditional probabilistic framework for collaborative representation of image patches. It in-corporates background compensation and outlier patch suppression into the main formulation itself, thus doingaway with the need for pre-processing steps to handle the same. A closed form non-iterative solution of the costfunction is derived. The proposed method (PProCRC) outperforms earlier related patch based (PCRC, GP-CRC)as well as the state-of-the-art probabilistic (ProCRC and EProCRC) models on several fine-grained benchmarkimage datasets for face recognition (AR and LFW) and species recognition (Oxford Flowers and Pets) tasks.We also expand our recent endemic Indian birds (IndBirds) dataset and report results on it. The demo code andIndBirds dataset are available through lead author.
CoCoNet: A Collaborative Convolutional Network
Jan 28, 2019
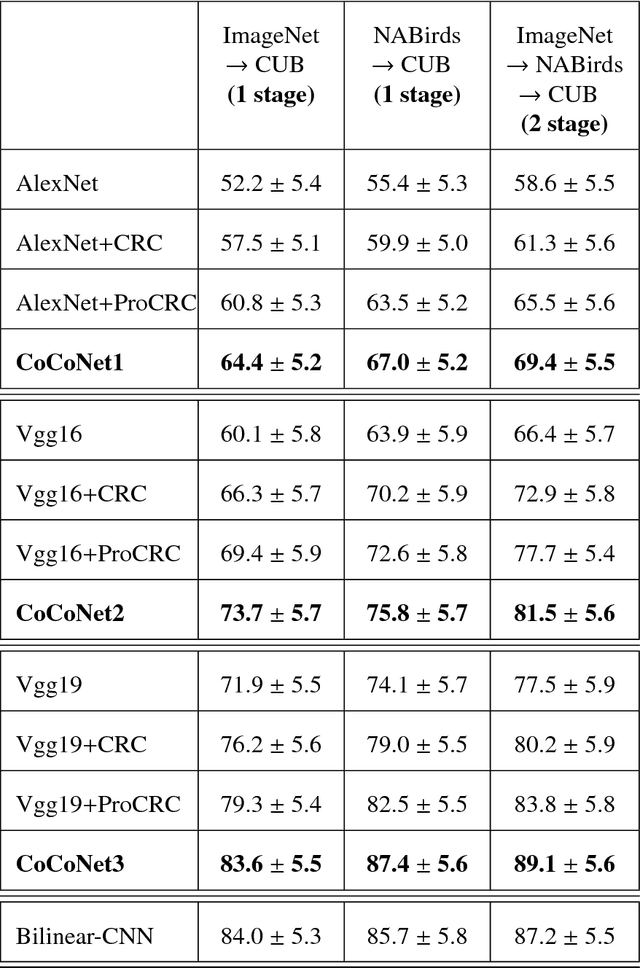
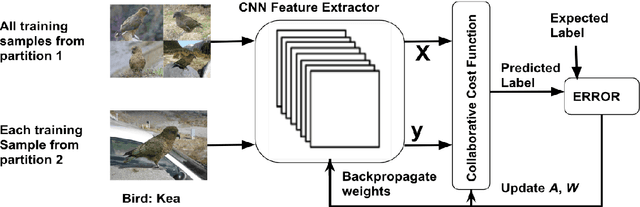
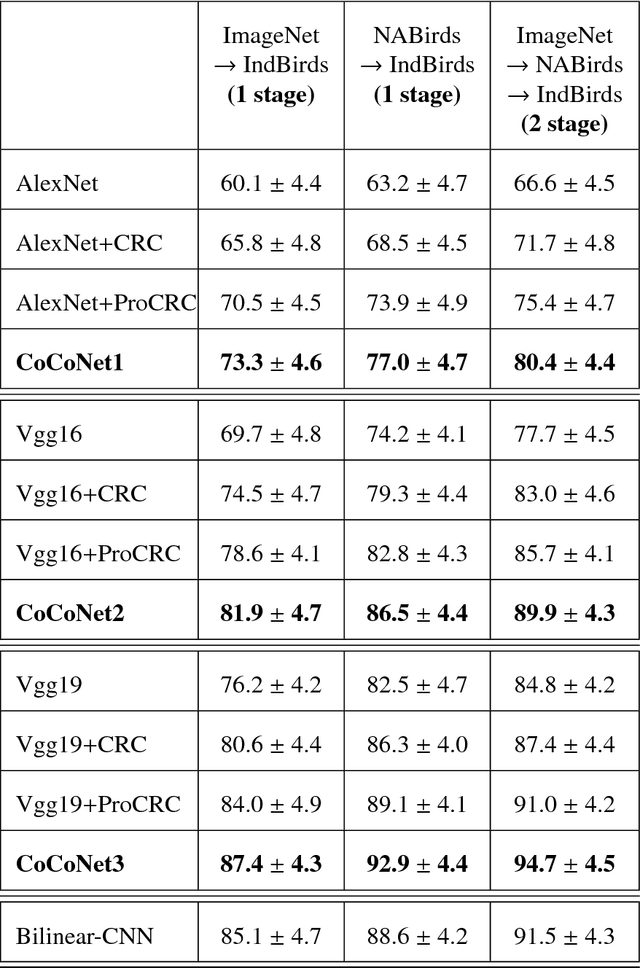
We present an end-to-end CNN architecture for fine-grained visual recognition called Collaborative Convolutional Network (CoCoNet). The network uses a collaborative filter after the convolutional layers to represent an image as an optimal weighted collaboration of features learned from training samples as a whole rather than one at a time. This gives CoCoNet more power to encode the fine-grained nature of the data with limited samples in an end-to-end fashion. We perform a detailed study of the performance with 1-stage and 2-stage transfer learning and different configurations with benchmark architectures like AlexNet and VggNet. The ablation study shows that the proposed method outperforms its constituent parts considerably and consistently. CoCoNet also outperforms the baseline popular deep learning based fine-grained recognition method, namely Bilinear-CNN (BCNN) with statistical significance. Experiments have been performed on the fine-grained species recognition problem, but the method is general enough to be applied to other similar tasks. Lastly, we also introduce a new public dataset for fine-grained species recognition, that of Indian endemic birds and have reported initial results on it. The training metadata and new dataset are available through the corresponding author.