 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRocNet: Recursive Octree Network for Efficient 3D Deep Representation
Aug 10, 2020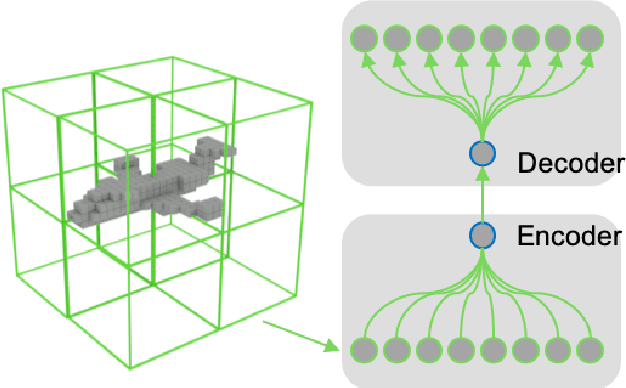
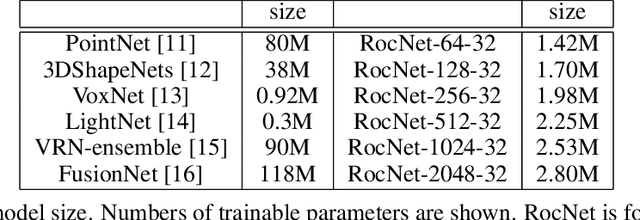
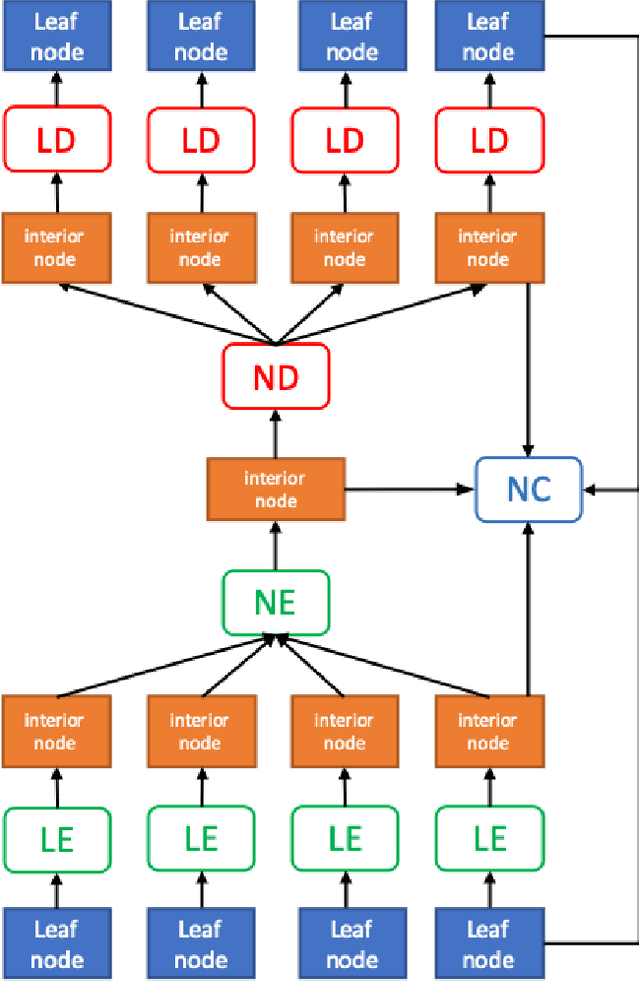
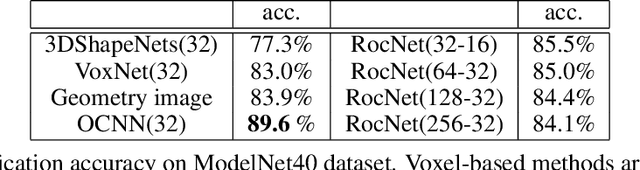
We introduce a deep recursive octree network for the compression of 3D voxel data. Our network compresses a voxel grid of any size down to a very small latent space in an autoencoder-like network. We show results for compressing 32, 64 and 128 grids down to just 80 floats in the latent space. We demonstrate the effectiveness and efficiency of our proposed method on several publicly available datasets with three experiments: 3D shape classification, 3D shape reconstruction, and shape generation. Experimental results show that our algorithm maintains accuracy while consuming less memory with shorter training times compared to existing methods, especially in 3D reconstruction tasks.
Distance Metric Learned Collaborative Representation Classifier
May 03, 2019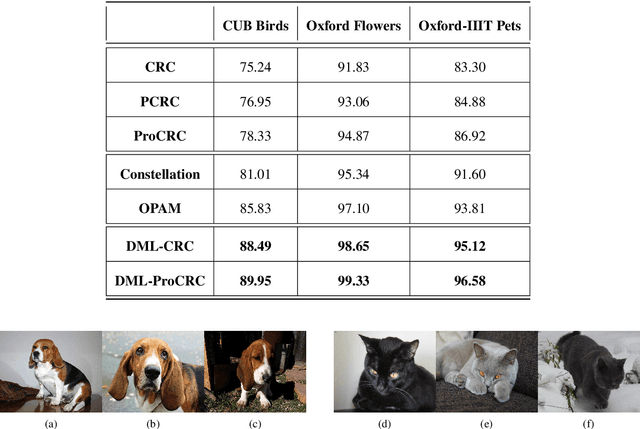
Any generic deep machine learning algorithm is essentially a function fitting exercise, where the network tunes its weights and parameters to learn discriminatory features by minimizing some cost function. Though the network tries to learn the optimal feature space, it seldom tries to learn an optimal distance metric in the cost function, and hence misses out on an additional layer of abstraction. We present a simple effective way of achieving this by learning a generic Mahalanabis distance in a collaborative loss function in an end-to-end fashion with any standard convolutional network as the feature learner. The proposed method DML-CRC gives state-of-the-art performance on benchmark fine-grained classification datasets CUB Birds, Oxford Flowers and Oxford-IIIT Pets using the VGG-19 deep network. The method is network agnostic and can be used for any similar classification tasks.
CoCoNet: A Collaborative Convolutional Network
Jan 28, 2019
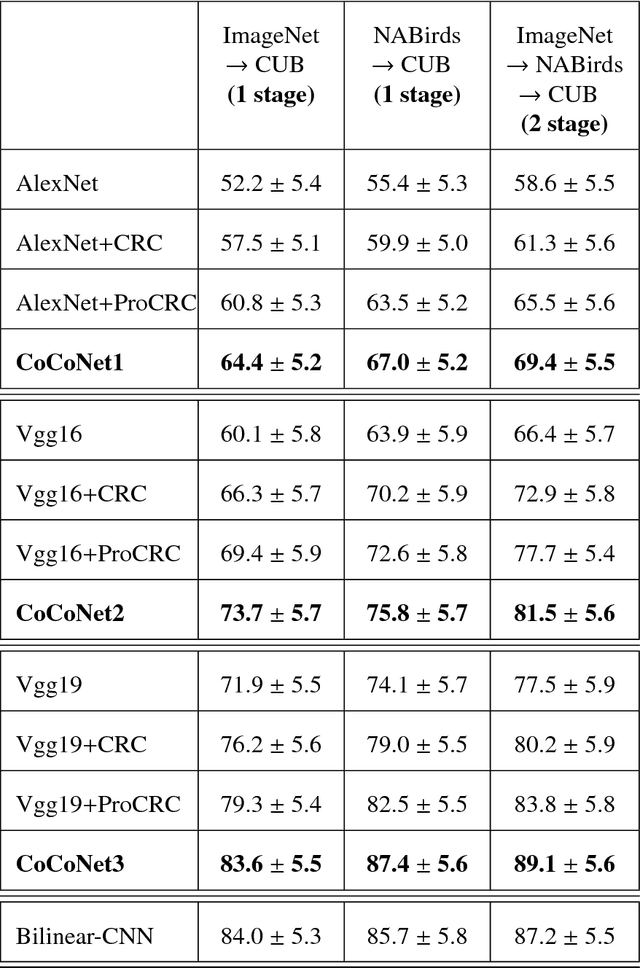
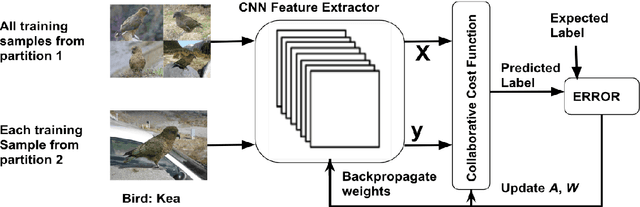
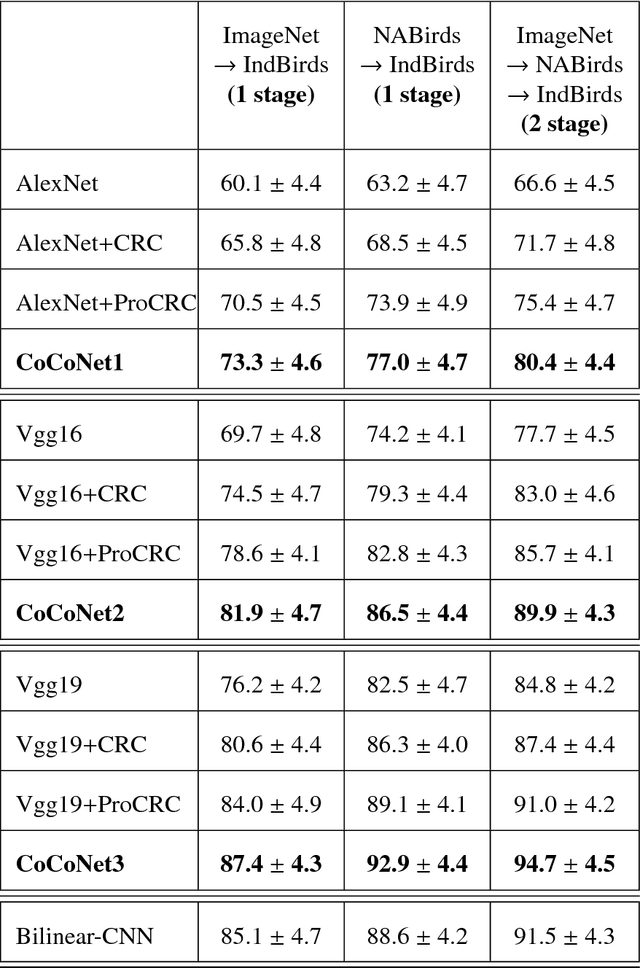
We present an end-to-end CNN architecture for fine-grained visual recognition called Collaborative Convolutional Network (CoCoNet). The network uses a collaborative filter after the convolutional layers to represent an image as an optimal weighted collaboration of features learned from training samples as a whole rather than one at a time. This gives CoCoNet more power to encode the fine-grained nature of the data with limited samples in an end-to-end fashion. We perform a detailed study of the performance with 1-stage and 2-stage transfer learning and different configurations with benchmark architectures like AlexNet and VggNet. The ablation study shows that the proposed method outperforms its constituent parts considerably and consistently. CoCoNet also outperforms the baseline popular deep learning based fine-grained recognition method, namely Bilinear-CNN (BCNN) with statistical significance. Experiments have been performed on the fine-grained species recognition problem, but the method is general enough to be applied to other similar tasks. Lastly, we also introduce a new public dataset for fine-grained species recognition, that of Indian endemic birds and have reported initial results on it. The training metadata and new dataset are available through the corresponding author.
LOOP Descriptor: Local Optimal Oriented Pattern
Feb 02, 2018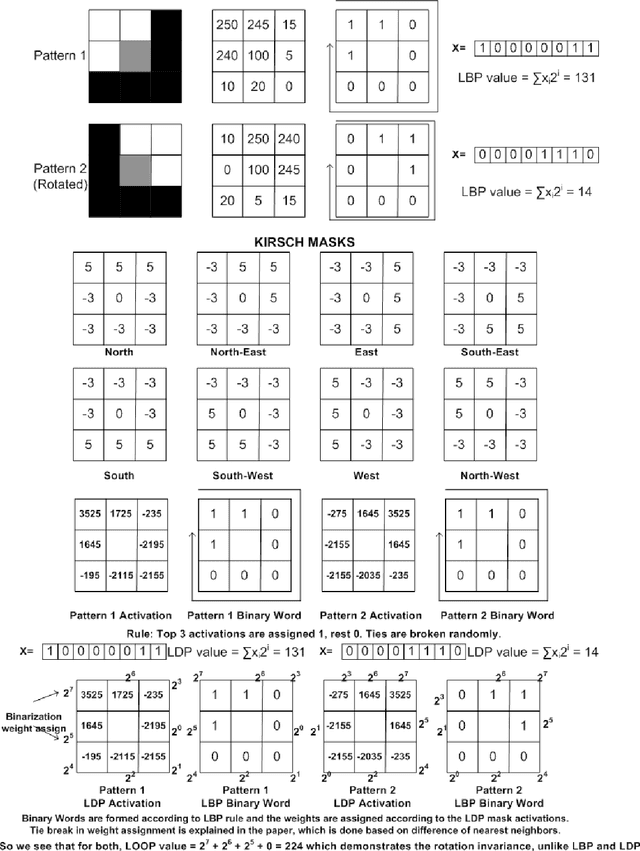



This letter introduces the LOOP binary descriptor (local optimal oriented pattern) that encodes rotation invariance into the main formulation itself. This makes any post processing stage for rotation invariance redundant and improves on both accuracy and time complexity. We consider fine-grained lepidoptera (moth/butterfly) species recognition as the representative problem since it involves repetition of localized patterns and textures that may be exploited for discrimination. We evaluate the performance of LOOP against its predecessors as well as few other popular descriptors. Besides experiments on standard benchmarks, we also introduce a new small image dataset on NZ Lepidoptera. Loop performs as well or better on all datasets evaluated compared to previous binary descriptors. The new dataset and demo code of the proposed method are to be made available through the lead author's academic webpage and GitHub.
Fair Forests: Regularized Tree Induction to Minimize Model Bias
Dec 21, 2017

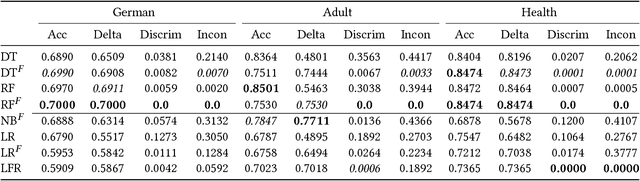
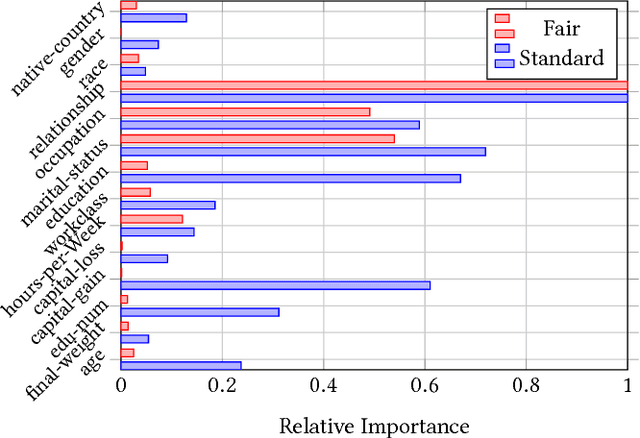
The potential lack of fairness in the outputs of machine learning algorithms has recently gained attention both within the research community as well as in society more broadly. Surprisingly, there is no prior work developing tree-induction algorithms for building fair decision trees or fair random forests. These methods have widespread popularity as they are one of the few to be simultaneously interpretable, non-linear, and easy-to-use. In this paper we develop, to our knowledge, the first technique for the induction of fair decision trees. We show that our "Fair Forest" retains the benefits of the tree-based approach, while providing both greater accuracy and fairness than other alternatives, for both "group fairness" and "individual fairness.'" We also introduce new measures for fairness which are able to handle multinomial and continues attributes as well as regression problems, as opposed to binary attributes and labels only. Finally, we demonstrate a new, more robust evaluation procedure for algorithms that considers the dataset in its entirety rather than only a specific protected attribute.
Auto-JacoBin: Auto-encoder Jacobian Binary Hashing
Mar 01, 2016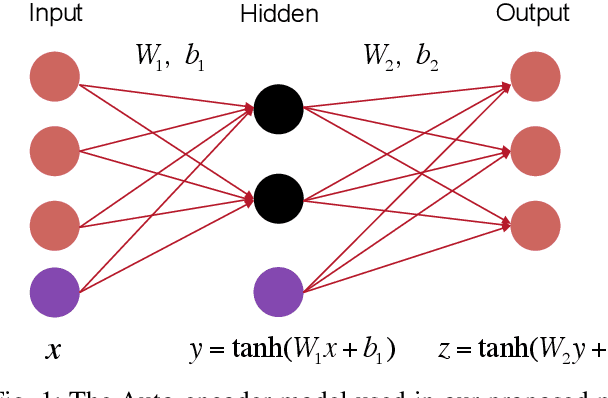
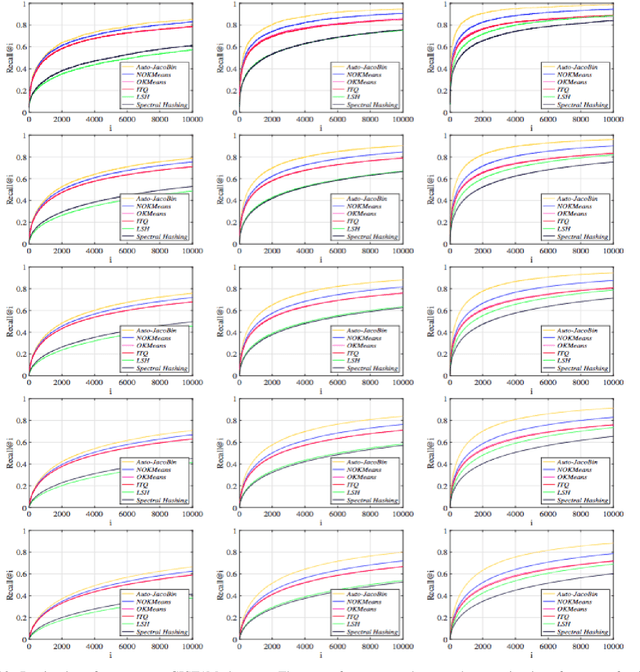
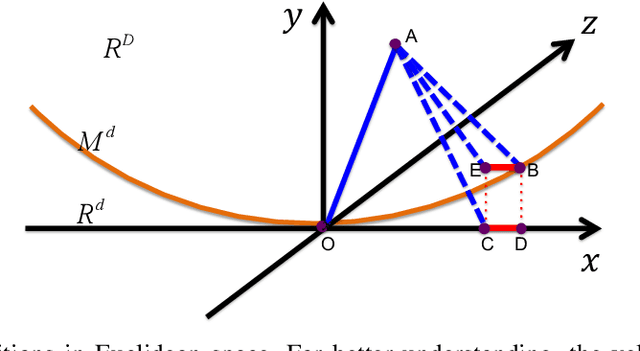

Binary codes can be used to speed up nearest neighbor search tasks in large scale data sets as they are efficient for both storage and retrieval. In this paper, we propose a robust auto-encoder model that preserves the geometric relationships of high-dimensional data sets in Hamming space. This is done by considering a noise-removing function in a region surrounding the manifold where the training data points lie. This function is defined with the property that it projects the data points near the manifold into the manifold wisely, and we approximate this function by its first order approximation. Experimental results show that the proposed method achieves better than state-of-the-art results on three large scale high dimensional data sets.