 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntervention Complexity as a Canonical Reward and a Measure of Intelligence
May 04, 2026The Legg--Hutter universal intelligence measure provides a rigorous scalar assessment of general intelligence as expected reward across all computable environments, weighted by simplicity. However, the measure presupposes an externally specified reward function, raising the question of whether the reward primitive is inherently arbitrary or whether a canonical choice exists. We propose a new measure, called intervention complexity, that has five natural properties: environment-derivedness, universality, minimality, sensitivity, and achievement preference. Given a resource function rho encoding an inductive bias (such as program length, execution time, or energy), rho-intervention complexity is a universal reward. The result yields a family of canonical rewards indexed by resource bias, providing a principled completion of the Legg--Hutter framework that does not require external normative input. We further propose a two-dimensional characterisation of intelligence: agent competence (how well the agent performs relative to the oracle optimum) and learning efficiency (how quickly this competence improves with experience). A separation theorem establishes that the choice of resource bias determines the computability of the resulting measure: action-count IC is computable in polynomial time, while program-length IC without oracle access is uncomputable, with the gap between oracle and bare IC precisely quantifying the information-theoretic content of learning. We discuss implications for superintelligence and for pre-training universal agents.
Conceptual capacity and effective complexity of neural networks
Mar 13, 2021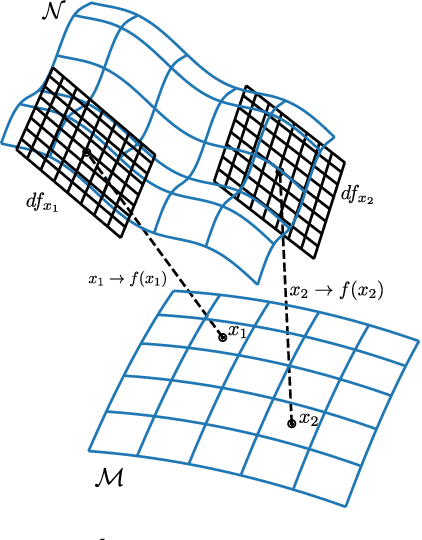
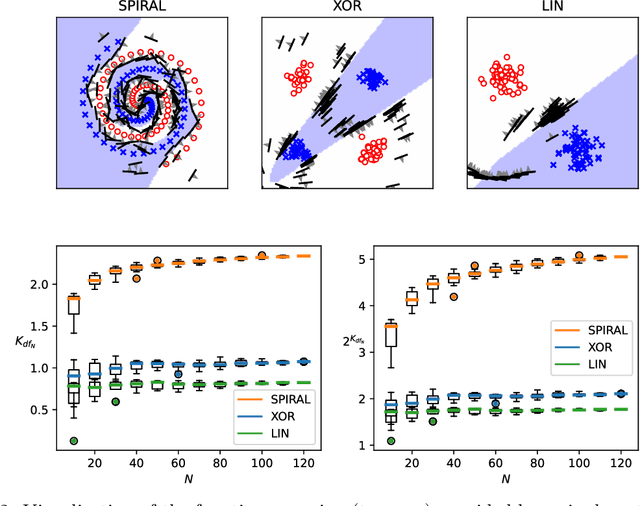
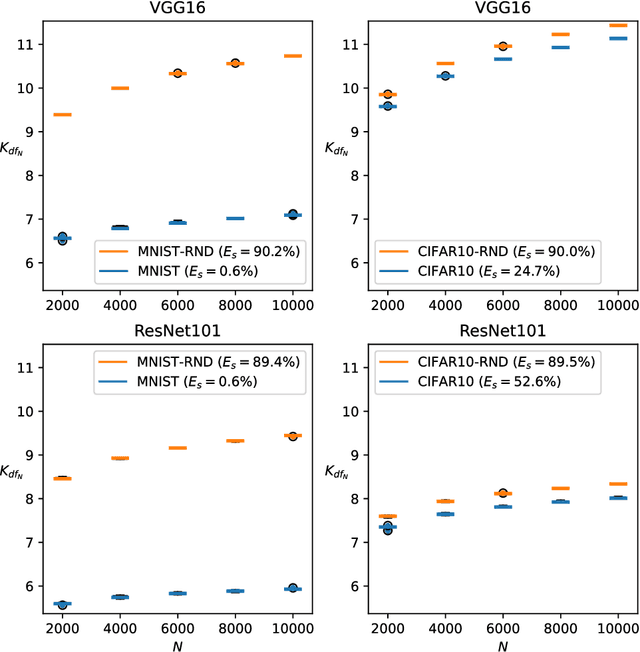
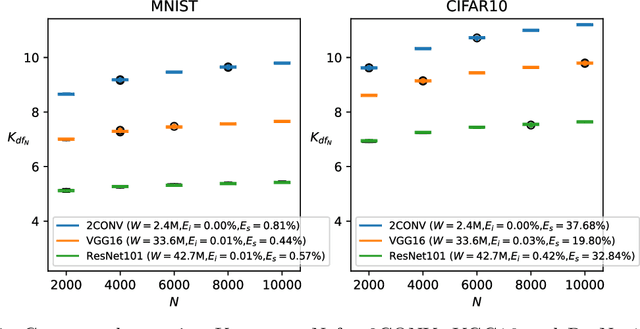
We propose a complexity measure of a neural network mapping function based on the diversity of the set of tangent spaces from different inputs. Treating each tangent space as a linear PAC concept we use an entropy-based measure of the bundle of concepts in order to estimate the conceptual capacity of the network. The theoretical maximal capacity of a ReLU network is equivalent to the number of its neurons. In practice however, due to correlations between neuron activities within the network, the actual capacity can be remarkably small, even for very big networks. Empirical evaluations show that this new measure is correlated with the complexity of the mapping function and thus the generalisation capabilities of the corresponding network. It captures the effective, as oppose to the theoretical, complexity of the network function. We also showcase some uses of the proposed measure for analysis and comparison of trained neural network models.
RocNet: Recursive Octree Network for Efficient 3D Deep Representation
Aug 10, 2020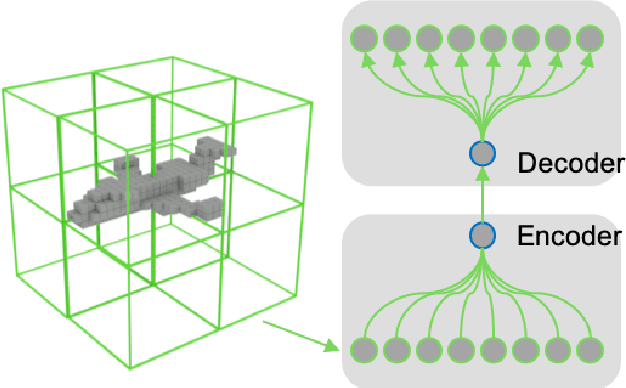
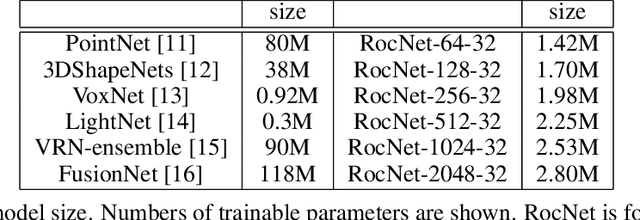
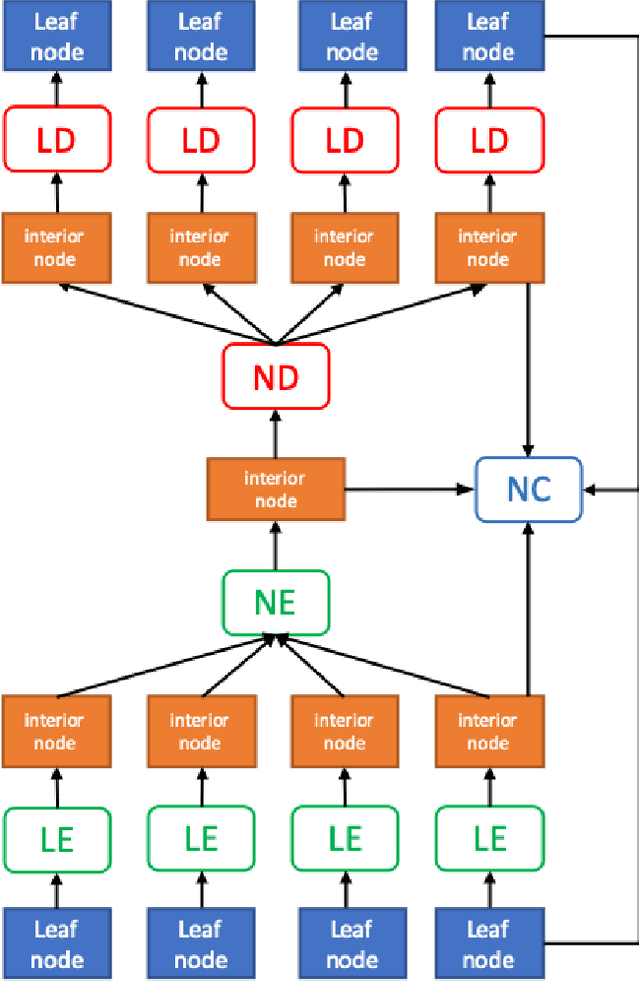
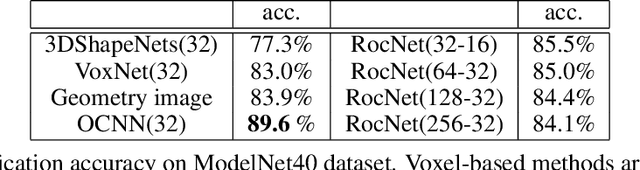
We introduce a deep recursive octree network for the compression of 3D voxel data. Our network compresses a voxel grid of any size down to a very small latent space in an autoencoder-like network. We show results for compressing 32, 64 and 128 grids down to just 80 floats in the latent space. We demonstrate the effectiveness and efficiency of our proposed method on several publicly available datasets with three experiments: 3D shape classification, 3D shape reconstruction, and shape generation. Experimental results show that our algorithm maintains accuracy while consuming less memory with shorter training times compared to existing methods, especially in 3D reconstruction tasks.
MIME: Mutual Information Minimisation Exploration
Jan 16, 2020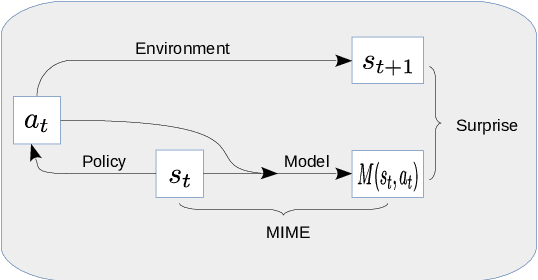

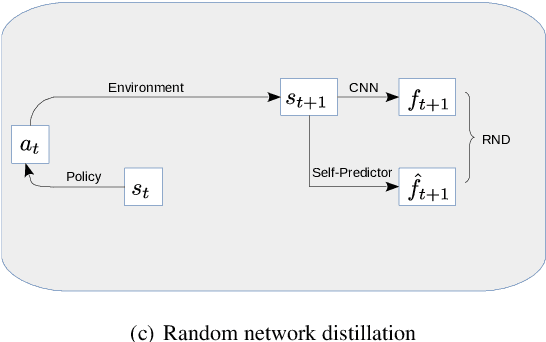
We show that reinforcement learning agents that learn by surprise (surprisal) get stuck at abrupt environmental transition boundaries because these transitions are difficult to learn. We propose a counter-intuitive solution that we call Mutual Information Minimising Exploration (MIME) where an agent learns a latent representation of the environment without trying to predict the future states. We show that our agent performs significantly better over sharp transition boundaries while matching the performance of surprisal driven agents elsewhere. In particular, we show state-of-the-art performance on difficult learning games such as Gravitar, Montezuma's Revenge and Doom.
GRIm-RePR: Prioritising Generating Important Features for Pseudo-Rehearsal
Nov 27, 2019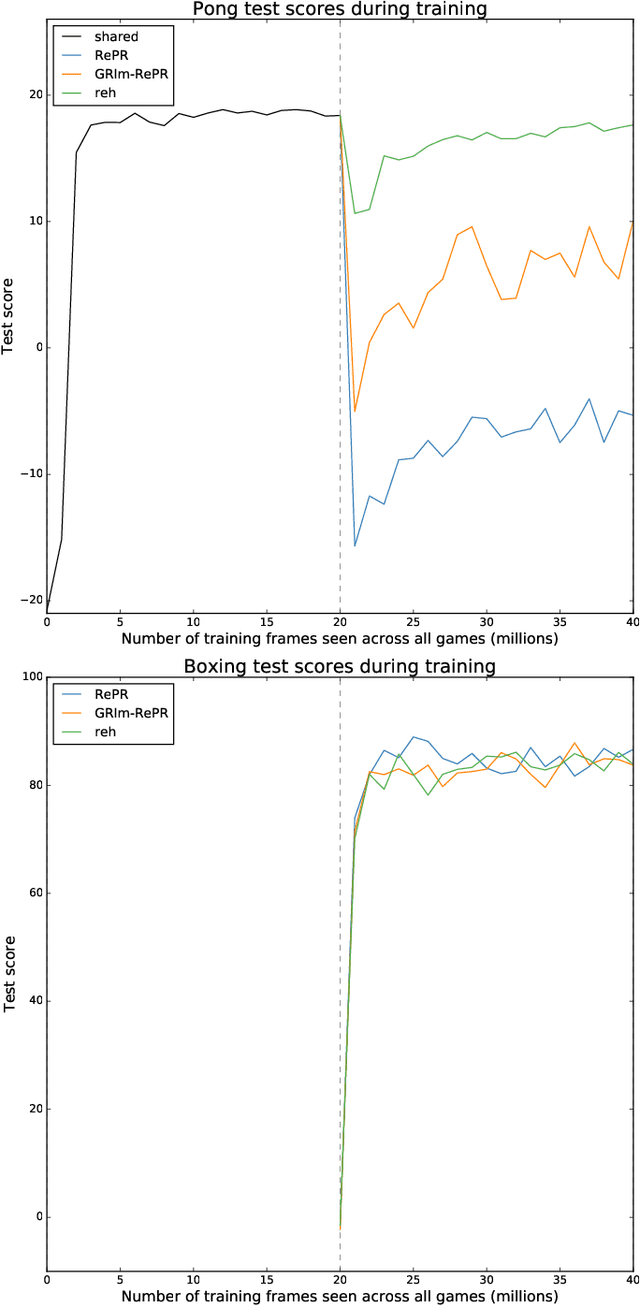
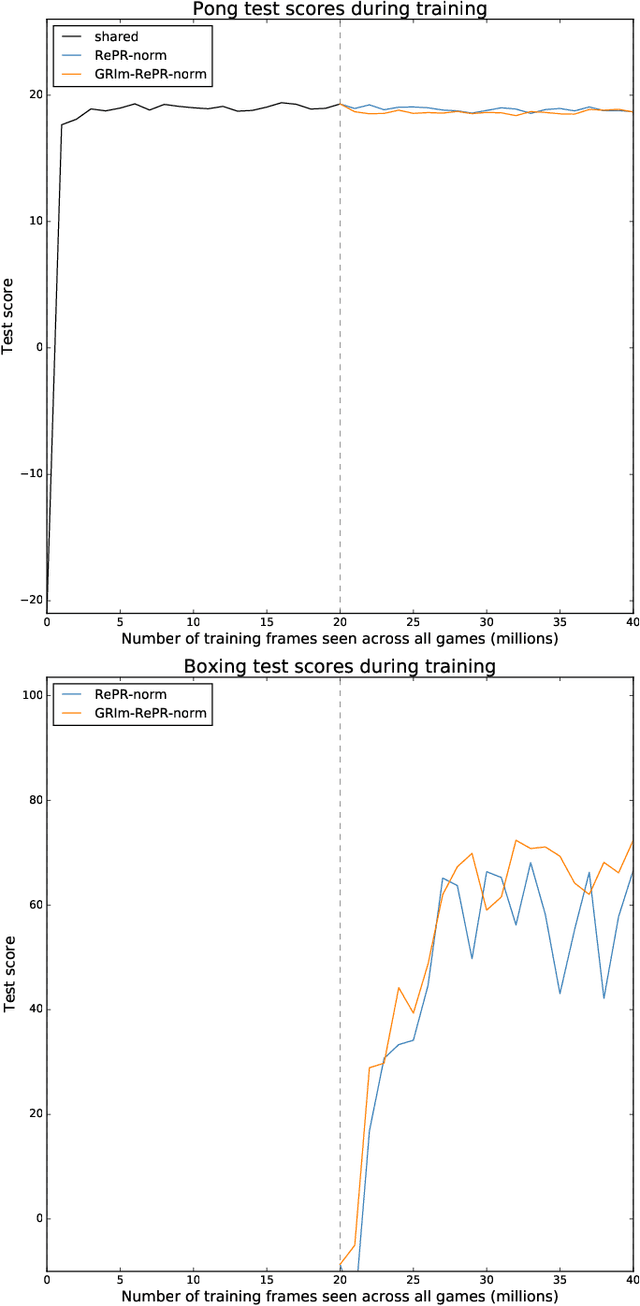
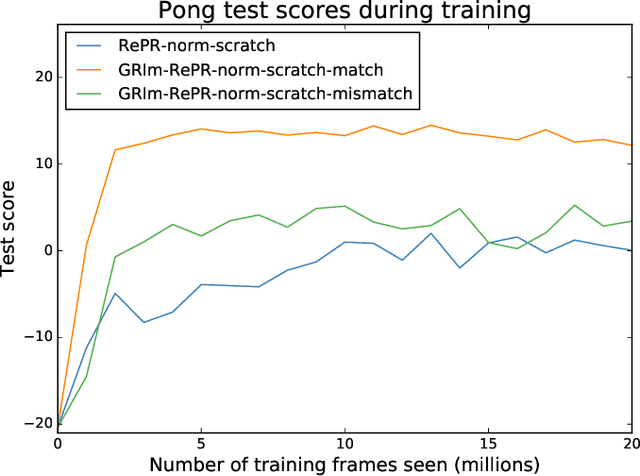
Pseudo-rehearsal allows neural networks to learn a sequence of tasks without forgetting how to perform in earlier tasks. Preventing forgetting is achieved by introducing a generative network which can produce data from previously seen tasks so that it can be rehearsed along side learning the new task. This has been found to be effective in both supervised and reinforcement learning. Our current work aims to further prevent forgetting by encouraging the generator to accurately generate features important for task retention. More specifically, the generator is improved by introducing a second discriminator into the Generative Adversarial Network which learns to classify between real and fake items from the intermediate activation patterns that they produce when fed through a continual learning agent. Using Atari 2600 games, we experimentally find that improving the generator can considerably reduce catastrophic forgetting compared to the standard pseudo-rehearsal methods used in deep reinforcement learning. Furthermore, we propose normalising the Q-values taught to the long-term system as we observe this substantially reduces catastrophic forgetting by minimising the interference between tasks' reward functions.
VASE: Variational Assorted Surprise Exploration for Reinforcement Learning
Oct 31, 2019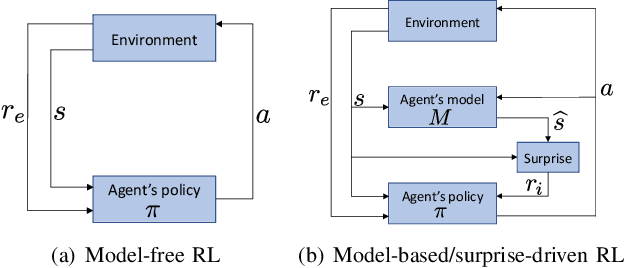
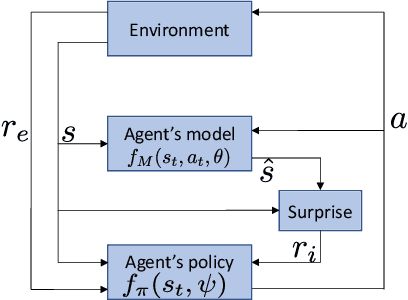
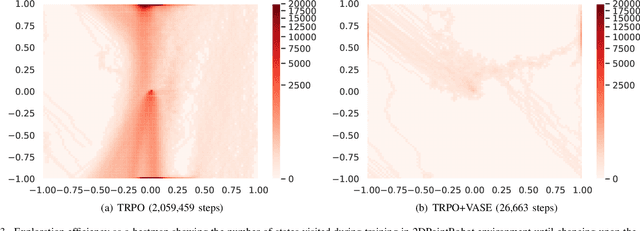
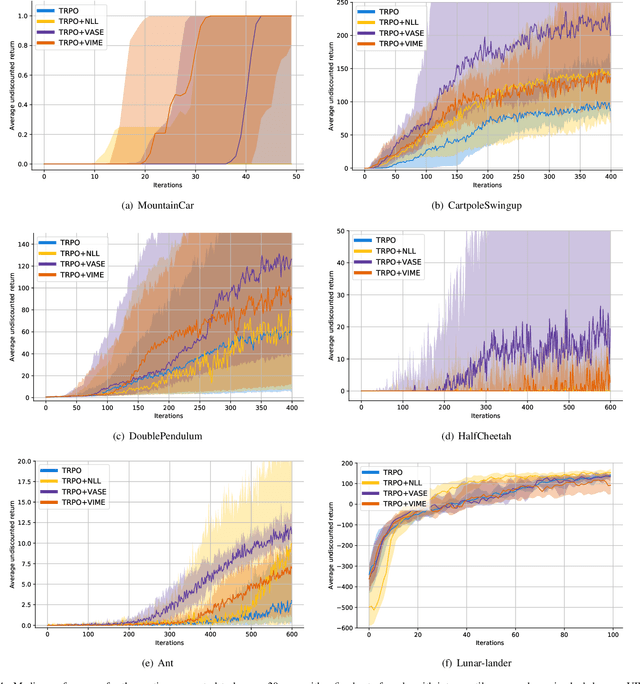
Exploration in environments with continuous control and sparse rewards remains a key challenge in reinforcement learning (RL). Recently, surprise has been used as an intrinsic reward that encourages systematic and efficient exploration. We introduce a new definition of surprise and its RL implementation named Variational Assorted Surprise Exploration (VASE). VASE uses a Bayesian neural network as a model of the environment dynamics and is trained using variational inference, alternately updating the accuracy of the agent's model and policy. Our experiments show that in continuous control sparse reward environments VASE outperforms other surprise-based exploration techniques.
Switched linear projections and inactive state sensitivity for deep neural network interpretability
Sep 25, 2019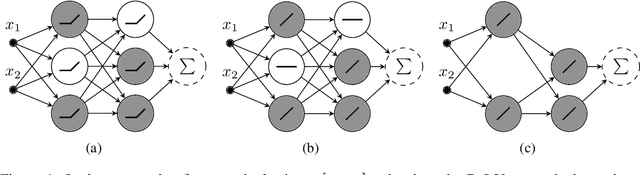
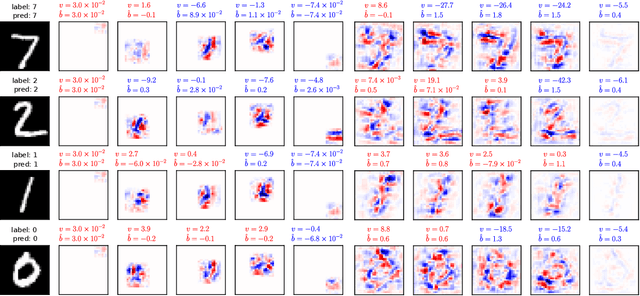
We introduce switched linear projections for expressing the activity of a neuron in a ReLU-based deep neural network in terms of a single linear projection in the input space. The method works by isolating the active subnetwork, a series of linear transformations, that completely determine the entire computation of the deep network for a given input instance. We also propose that for interpretability it is more instructive and meaningful to focus on the patterns that deactive the neurons in the network, which are ignored by the exisiting methods that implicitly track only the active aspect of the network's computation. We introduce a novel interpretability method for the inactive state sensitivity (Insens). Comparison against existing methods shows that Insens is more robust (in the presence of noise), more complete (in terms of patterns that affect the computation) and a very effective interpretability method for deep neural networks.
Distance Metric Learned Collaborative Representation Classifier
May 03, 2019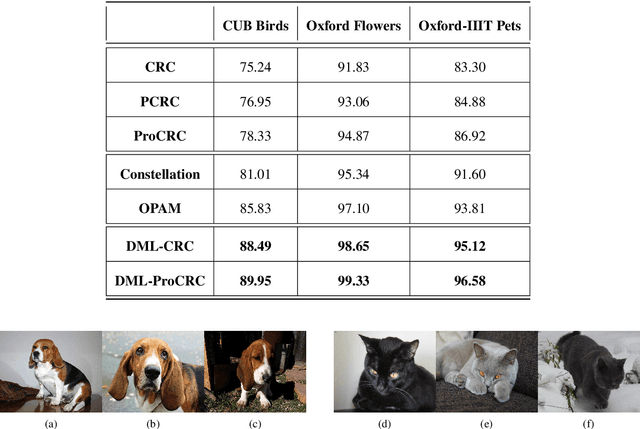
Any generic deep machine learning algorithm is essentially a function fitting exercise, where the network tunes its weights and parameters to learn discriminatory features by minimizing some cost function. Though the network tries to learn the optimal feature space, it seldom tries to learn an optimal distance metric in the cost function, and hence misses out on an additional layer of abstraction. We present a simple effective way of achieving this by learning a generic Mahalanabis distance in a collaborative loss function in an end-to-end fashion with any standard convolutional network as the feature learner. The proposed method DML-CRC gives state-of-the-art performance on benchmark fine-grained classification datasets CUB Birds, Oxford Flowers and Oxford-IIIT Pets using the VGG-19 deep network. The method is network agnostic and can be used for any similar classification tasks.
PProCRC: Probabilistic Collaboration of Image Patches
Mar 21, 2019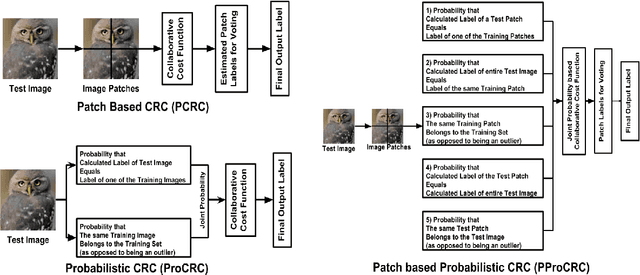
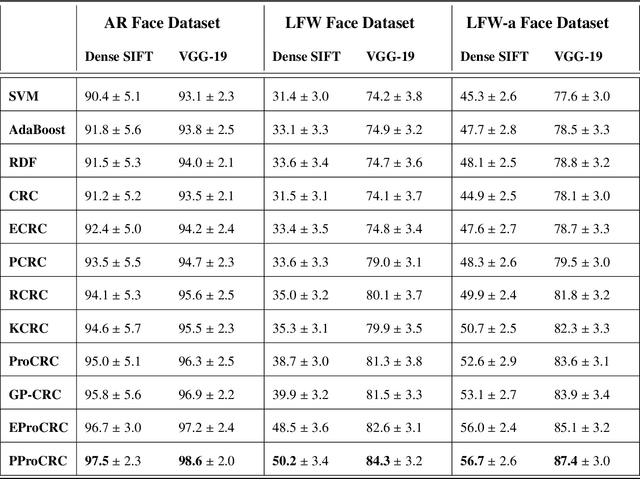

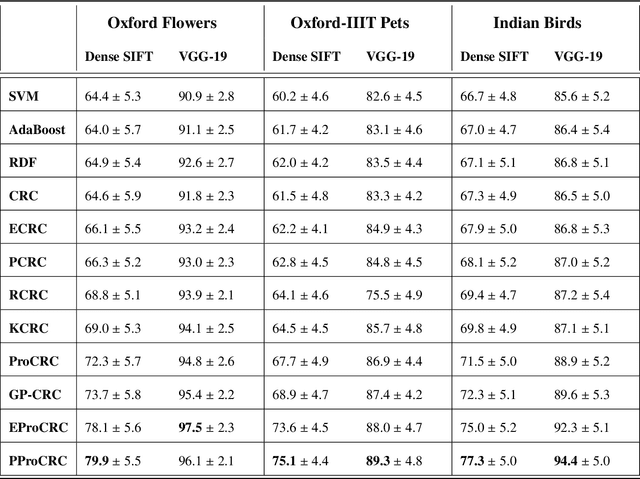
We present a conditional probabilistic framework for collaborative representation of image patches. It in-corporates background compensation and outlier patch suppression into the main formulation itself, thus doingaway with the need for pre-processing steps to handle the same. A closed form non-iterative solution of the costfunction is derived. The proposed method (PProCRC) outperforms earlier related patch based (PCRC, GP-CRC)as well as the state-of-the-art probabilistic (ProCRC and EProCRC) models on several fine-grained benchmarkimage datasets for face recognition (AR and LFW) and species recognition (Oxford Flowers and Pets) tasks.We also expand our recent endemic Indian birds (IndBirds) dataset and report results on it. The demo code andIndBirds dataset are available through lead author.
CoCoNet: A Collaborative Convolutional Network
Jan 28, 2019
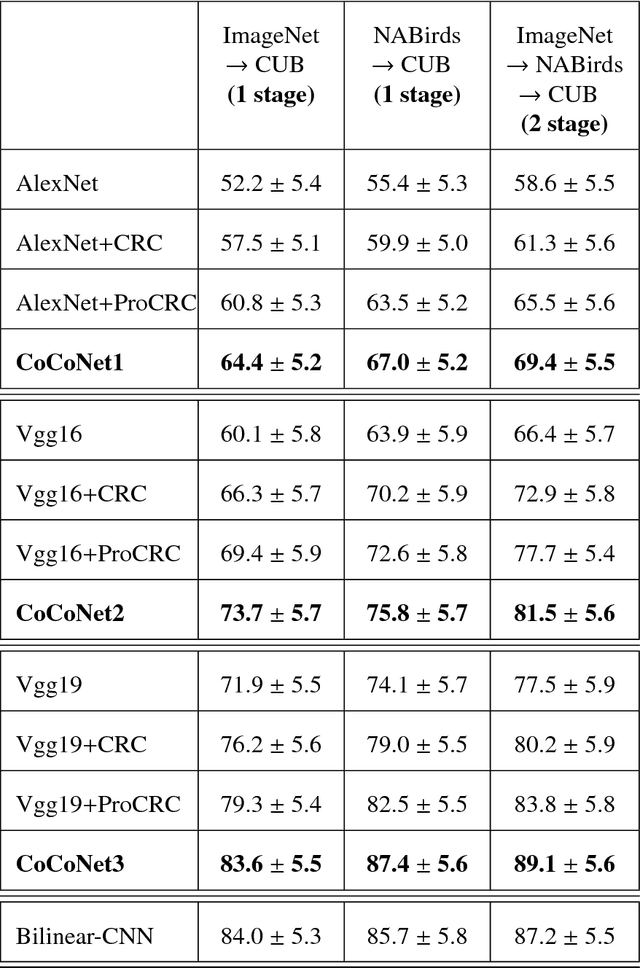
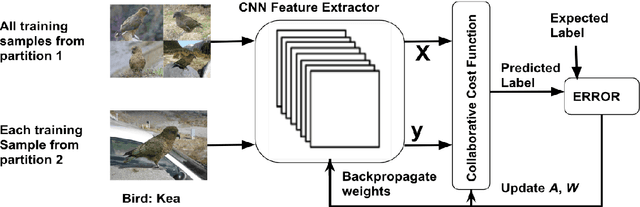
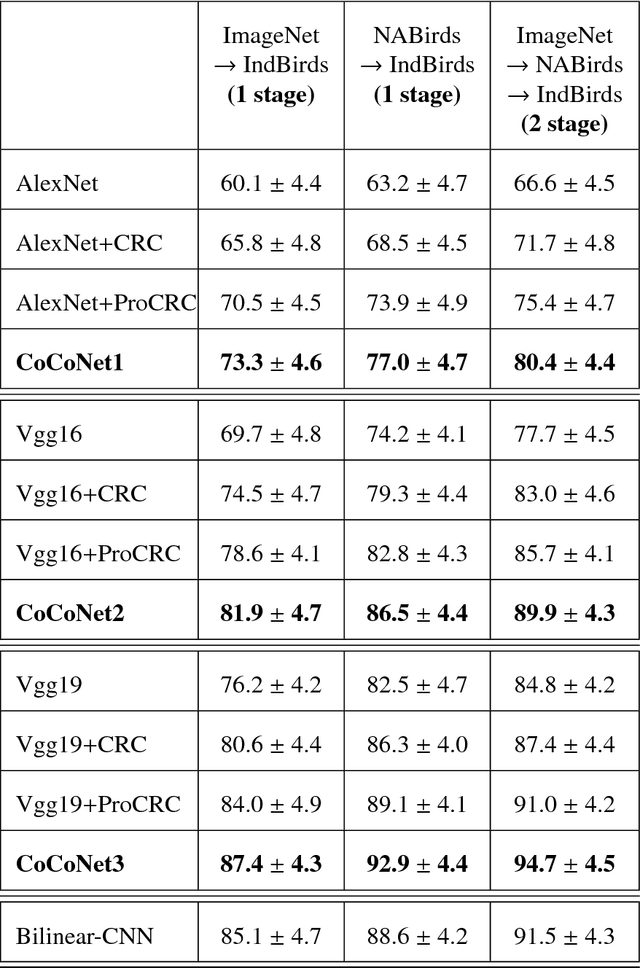
We present an end-to-end CNN architecture for fine-grained visual recognition called Collaborative Convolutional Network (CoCoNet). The network uses a collaborative filter after the convolutional layers to represent an image as an optimal weighted collaboration of features learned from training samples as a whole rather than one at a time. This gives CoCoNet more power to encode the fine-grained nature of the data with limited samples in an end-to-end fashion. We perform a detailed study of the performance with 1-stage and 2-stage transfer learning and different configurations with benchmark architectures like AlexNet and VggNet. The ablation study shows that the proposed method outperforms its constituent parts considerably and consistently. CoCoNet also outperforms the baseline popular deep learning based fine-grained recognition method, namely Bilinear-CNN (BCNN) with statistical significance. Experiments have been performed on the fine-grained species recognition problem, but the method is general enough to be applied to other similar tasks. Lastly, we also introduce a new public dataset for fine-grained species recognition, that of Indian endemic birds and have reported initial results on it. The training metadata and new dataset are available through the corresponding author.