 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwitched linear projections and inactive state sensitivity for deep neural network interpretability
Paper and Code
Sep 25, 2019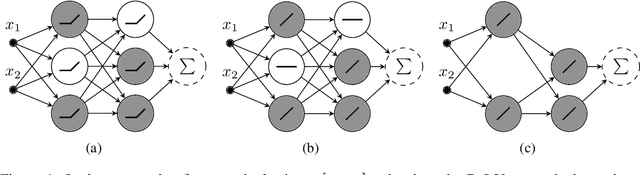
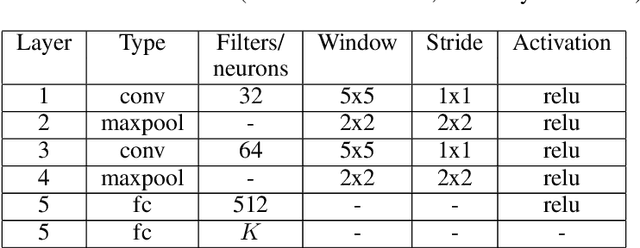
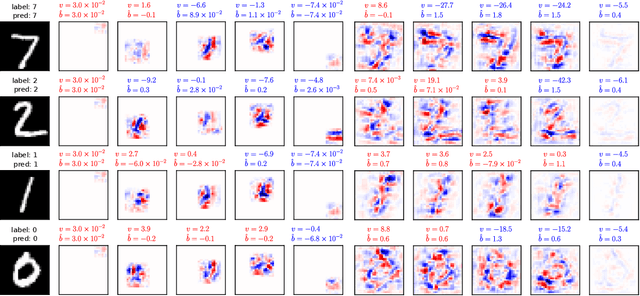
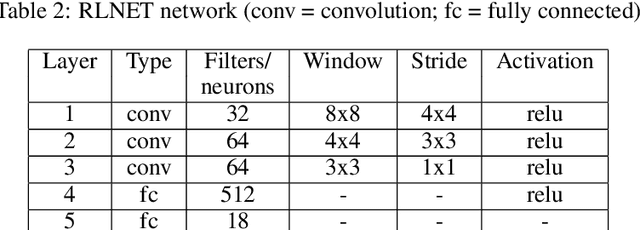
We introduce switched linear projections for expressing the activity of a neuron in a ReLU-based deep neural network in terms of a single linear projection in the input space. The method works by isolating the active subnetwork, a series of linear transformations, that completely determine the entire computation of the deep network for a given input instance. We also propose that for interpretability it is more instructive and meaningful to focus on the patterns that deactive the neurons in the network, which are ignored by the exisiting methods that implicitly track only the active aspect of the network's computation. We introduce a novel interpretability method for the inactive state sensitivity (Insens). Comparison against existing methods shows that Insens is more robust (in the presence of noise), more complete (in terms of patterns that affect the computation) and a very effective interpretability method for deep neural networks.