Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIME: Mutual Information Minimisation Exploration
Paper and Code
Jan 16, 2020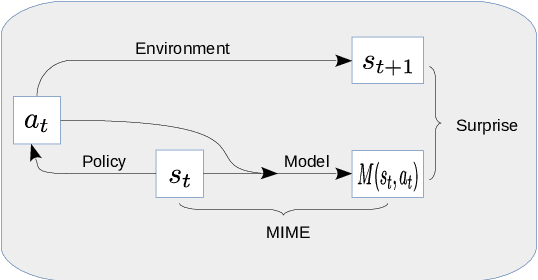

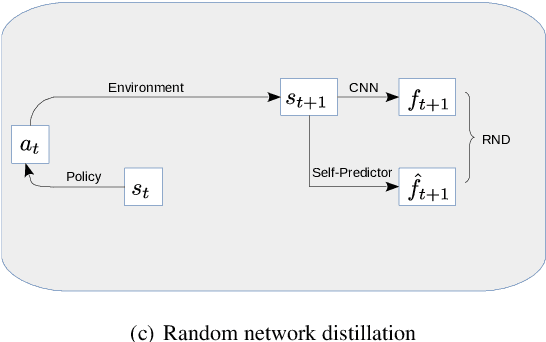
We show that reinforcement learning agents that learn by surprise (surprisal) get stuck at abrupt environmental transition boundaries because these transitions are difficult to learn. We propose a counter-intuitive solution that we call Mutual Information Minimising Exploration (MIME) where an agent learns a latent representation of the environment without trying to predict the future states. We show that our agent performs significantly better over sharp transition boundaries while matching the performance of surprisal driven agents elsewhere. In particular, we show state-of-the-art performance on difficult learning games such as Gravitar, Montezuma's Revenge and Doom.
View paper on