 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEngineering a Simplified 0-Bit Consistent Weighted Sampling
Oct 23, 2018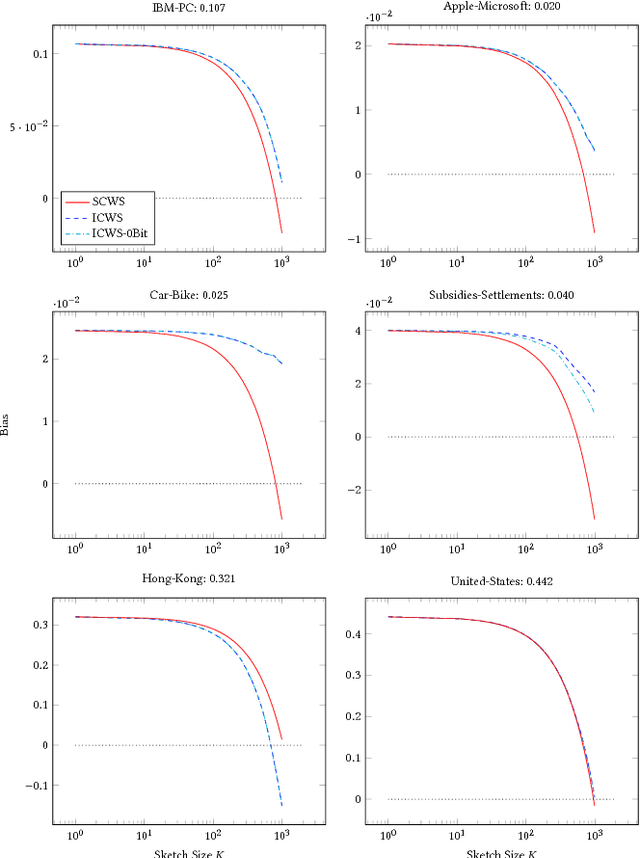
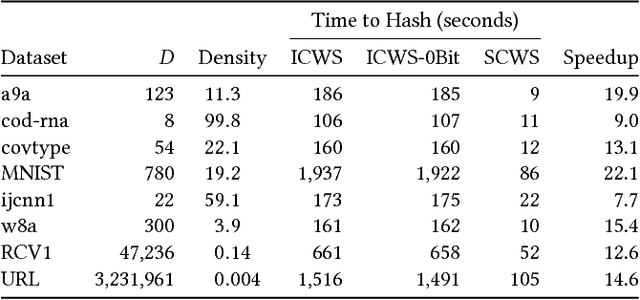


The Min-Hashing approach to sketching has become an important tool in data analysis, information retrial, and classification. To apply it to real-valued datasets, the ICWS algorithm has become a seminal approach that is widely used, and provides state-of-the-art performance for this problem space. However, ICWS suffers a computational burden as the sketch size K increases. We develop a new Simplified approach to the ICWS algorithm, that enables us to obtain over 20x speedups compared to the standard algorithm. The veracity of our approach is demonstrated empirically on multiple datasets and scenarios, showing that our new Simplified CWS obtains the same quality of results while being an order of magnitude faster.
Gradient Reversal Against Discrimination
Jul 01, 2018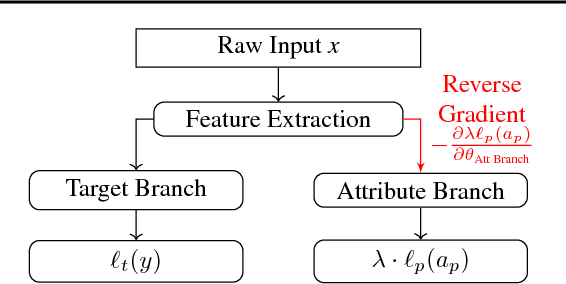
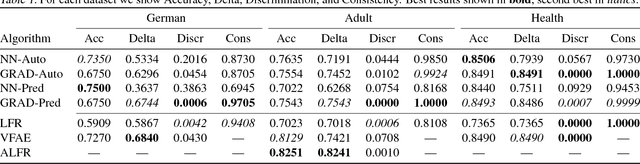
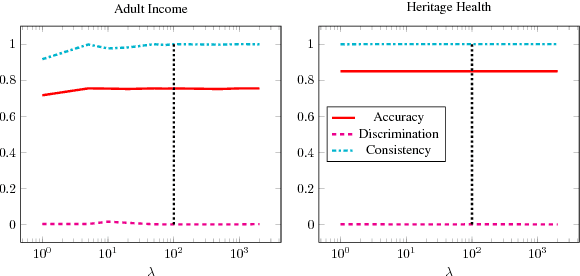
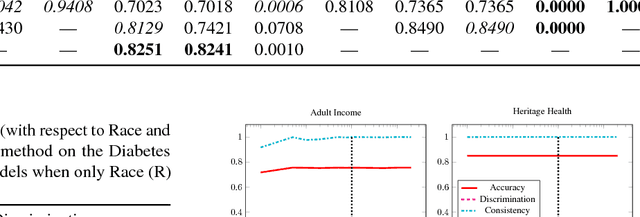
No methods currently exist for making arbitrary neural networks fair. In this work we introduce GRAD, a new and simplified method to producing fair neural networks that can be used for auto-encoding fair representations or directly with predictive networks. It is easy to implement and add to existing architectures, has only one (insensitive) hyper-parameter, and provides improved individual and group fairness. We use the flexibility of GRAD to demonstrate multi-attribute protection.
Non-Negative Networks Against Adversarial Attacks
Jun 15, 2018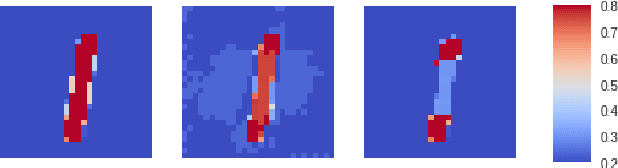
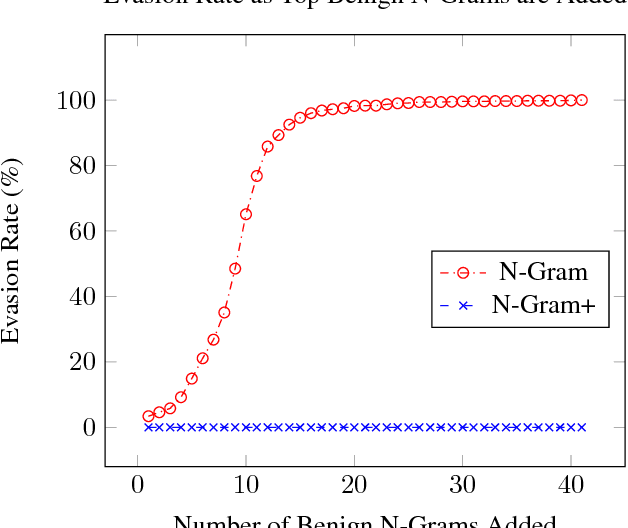
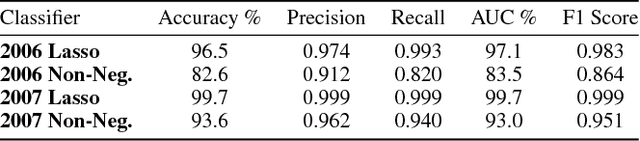
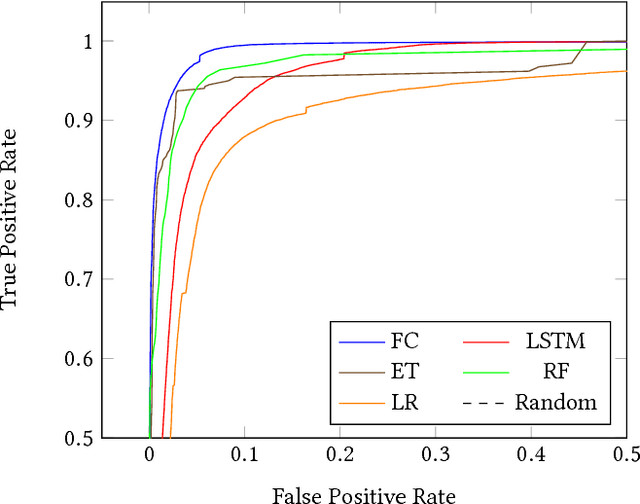
Adversarial attacks against Neural Networks are a problem of considerable importance, for which effective defenses are not yet readily available. We make progress toward this problem by showing that non-negative weight constraints can be used to improve resistance in specific scenarios. In particular, we show that they can provide an effective defense for binary classification problems with asymmetric cost, such as malware or spam detection. We also show how non-negativity can be leveraged to reduce an attacker's ability to perform targeted misclassification attacks in other domains such as image processing.
What About Applied Fairness?
Jun 13, 2018Machine learning practitioners are often ambivalent about the ethical aspects of their products. We believe anything that gets us from that current state to one in which our systems are achieving some degree of fairness is an improvement that should be welcomed. This is true even when that progress does not get us 100% of the way to the goal of "complete" fairness or perfectly align with our personal belief on which measure of fairness is used. Some measure of fairness being built would still put us in a better position than the status quo. Impediments to getting fairness and ethical concerns applied in real applications, whether they are abstruse philosophical debates or technical overhead such as the introduction of ever more hyper-parameters, should be avoided. In this paper we further elaborate on our argument for this viewpoint and its importance.
* Accepted at Machine Learning: The Debates (ML-D), at ICML Stockholm, Sweden, 2018. 5 pages
Fair Forests: Regularized Tree Induction to Minimize Model Bias
Dec 21, 2017

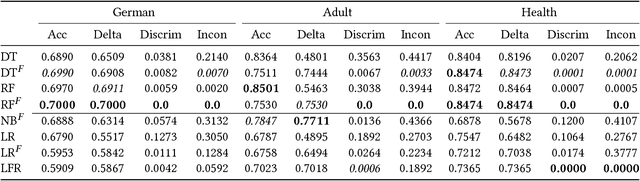
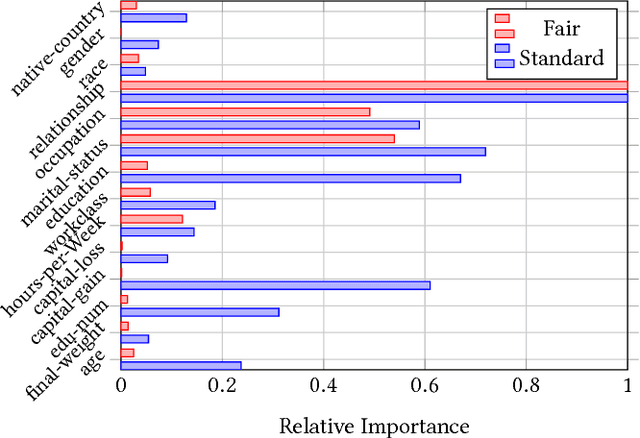
The potential lack of fairness in the outputs of machine learning algorithms has recently gained attention both within the research community as well as in society more broadly. Surprisingly, there is no prior work developing tree-induction algorithms for building fair decision trees or fair random forests. These methods have widespread popularity as they are one of the few to be simultaneously interpretable, non-linear, and easy-to-use. In this paper we develop, to our knowledge, the first technique for the induction of fair decision trees. We show that our "Fair Forest" retains the benefits of the tree-based approach, while providing both greater accuracy and fairness than other alternatives, for both "group fairness" and "individual fairness.'" We also introduce new measures for fairness which are able to handle multinomial and continues attributes as well as regression problems, as opposed to binary attributes and labels only. Finally, we demonstrate a new, more robust evaluation procedure for algorithms that considers the dataset in its entirety rather than only a specific protected attribute.
Learning the PE Header, Malware Detection with Minimal Domain Knowledge
Nov 11, 2017


Many efforts have been made to use various forms of domain knowledge in malware detection. Currently there exist two common approaches to malware detection without domain knowledge, namely byte n-grams and strings. In this work we explore the feasibility of applying neural networks to malware detection and feature learning. We do this by restricting ourselves to a minimal amount of domain knowledge in order to extract a portion of the Portable Executable (PE) header. By doing this we show that neural networks can learn from raw bytes without explicit feature construction, and perform even better than a domain knowledge approach that parses the PE header into explicit features.
Malware Detection by Eating a Whole EXE
Oct 25, 2017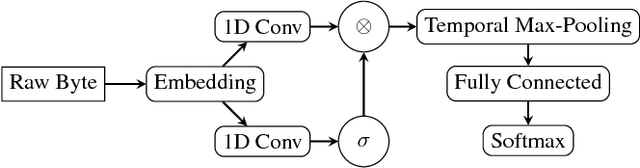


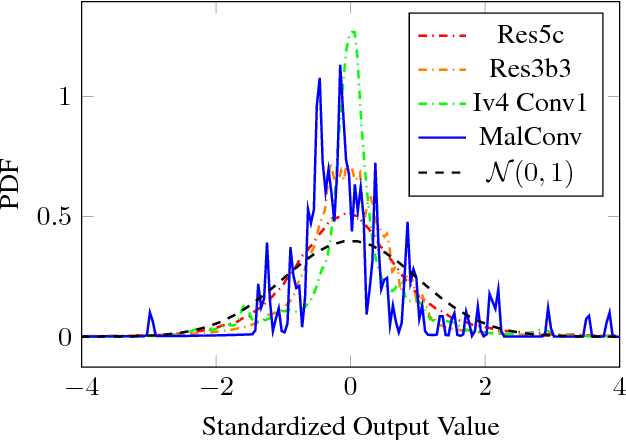
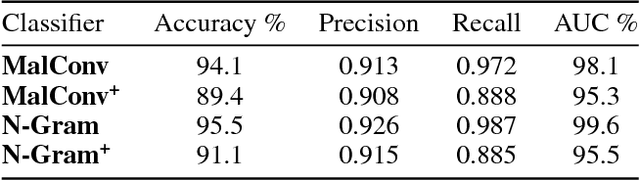
In this work we introduce malware detection from raw byte sequences as a fruitful research area to the larger machine learning community. Building a neural network for such a problem presents a number of interesting challenges that have not occurred in tasks such as image processing or NLP. In particular, we note that detection from raw bytes presents a sequence problem with over two million time steps and a problem where batch normalization appear to hinder the learning process. We present our initial work in building a solution to tackle this problem, which has linear complexity dependence on the sequence length, and allows for interpretable sub-regions of the binary to be identified. In doing so we will discuss the many challenges in building a neural network to process data at this scale, and the methods we used to work around them.
Understanding the Predictive Power of Computational Mechanics and Echo State Networks in Social Media
Aug 23, 2013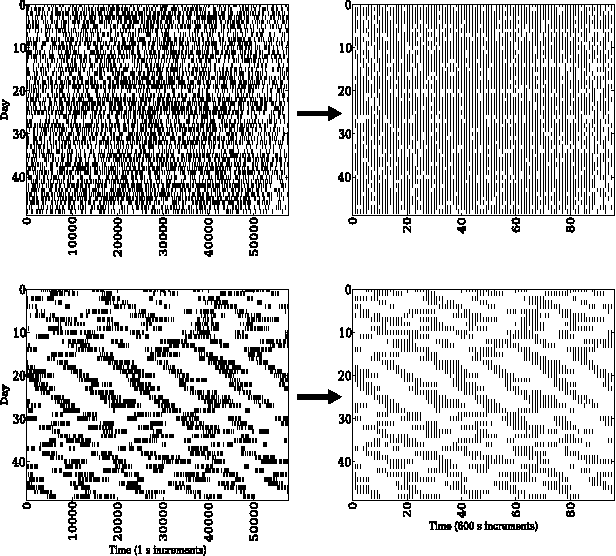
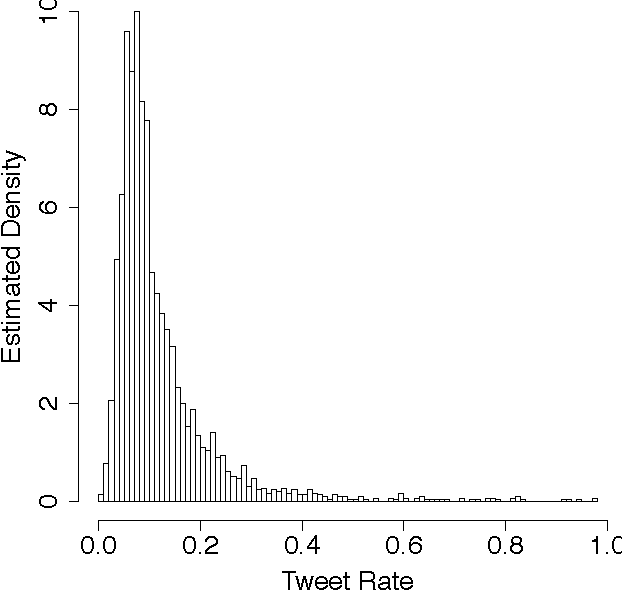
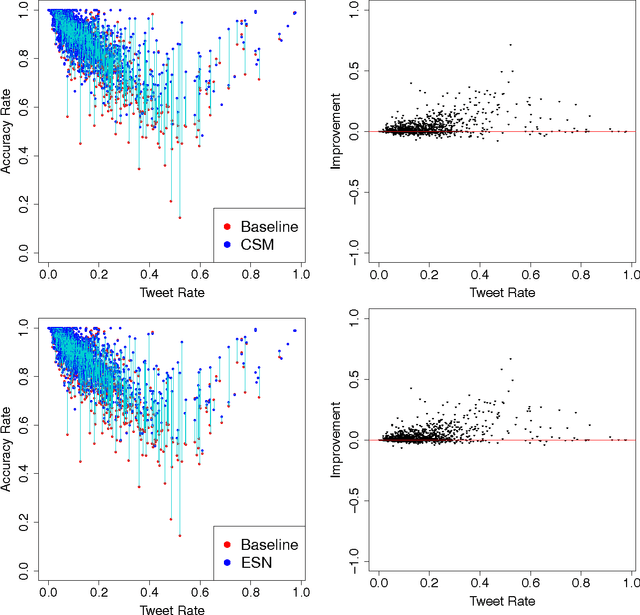
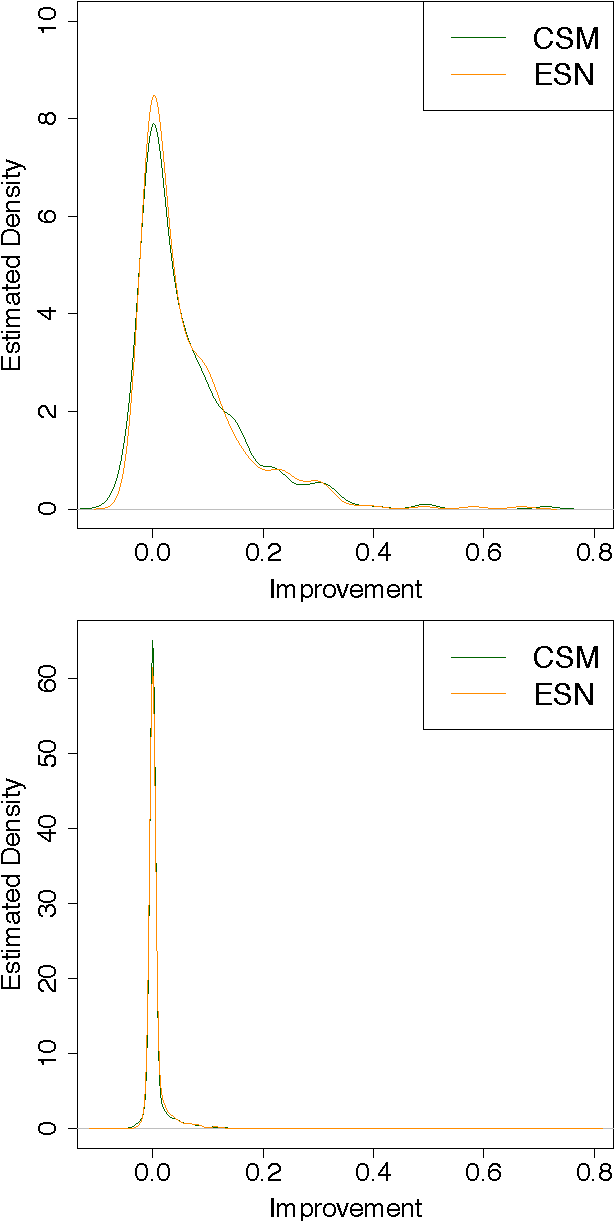
There is a large amount of interest in understanding users of social media in order to predict their behavior in this space. Despite this interest, user predictability in social media is not well-understood. To examine this question, we consider a network of fifteen thousand users on Twitter over a seven week period. We apply two contrasting modeling paradigms: computational mechanics and echo state networks. Both methods attempt to model the behavior of users on the basis of their past behavior. We demonstrate that the behavior of users on Twitter can be well-modeled as processes with self-feedback. We find that the two modeling approaches perform very similarly for most users, but that they differ in performance on a small subset of the users. By exploring the properties of these performance-differentiated users, we highlight the challenges faced in applying predictive models to dynamic social data.