 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Myopia of Crowds: A Study of Collective Evaluation on Stack Exchange
Feb 24, 2016
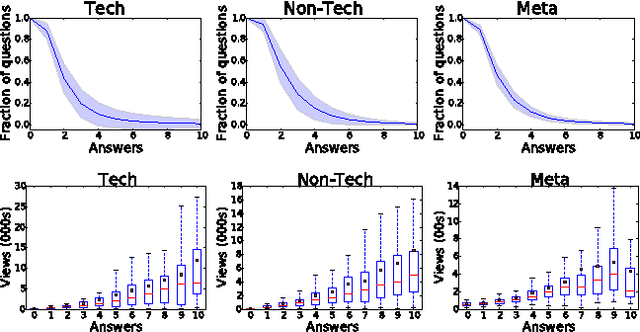
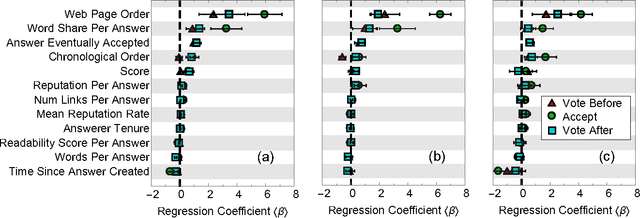
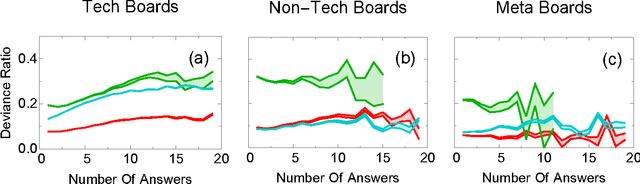
Crowds can often make better decisions than individuals or small groups of experts by leveraging their ability to aggregate diverse information. Question answering sites, such as Stack Exchange, rely on the "wisdom of crowds" effect to identify the best answers to questions asked by users. We analyze data from 250 communities on the Stack Exchange network to pinpoint factors affecting which answers are chosen as the best answers. Our results suggest that, rather than evaluate all available answers to a question, users rely on simple cognitive heuristics to choose an answer to vote for or accept. These cognitive heuristics are linked to an answer's salience, such as the order in which it is listed and how much screen space it occupies. While askers appear to depend more on heuristics, compared to voting users, when choosing an answer to accept as the most helpful one, voters use acceptance itself as a heuristic: they are more likely to choose the answer after it is accepted than before that very same answer was accepted. These heuristics become more important in explaining and predicting behavior as the number of available answers increases. Our findings suggest that crowd judgments may become less reliable as the number of answers grow.
* 10 pages, 9 figures
Understanding the Predictive Power of Computational Mechanics and Echo State Networks in Social Media
Aug 23, 2013
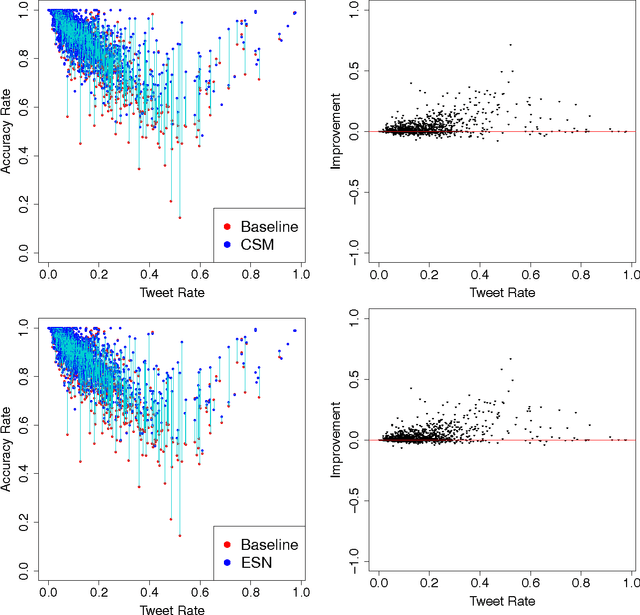
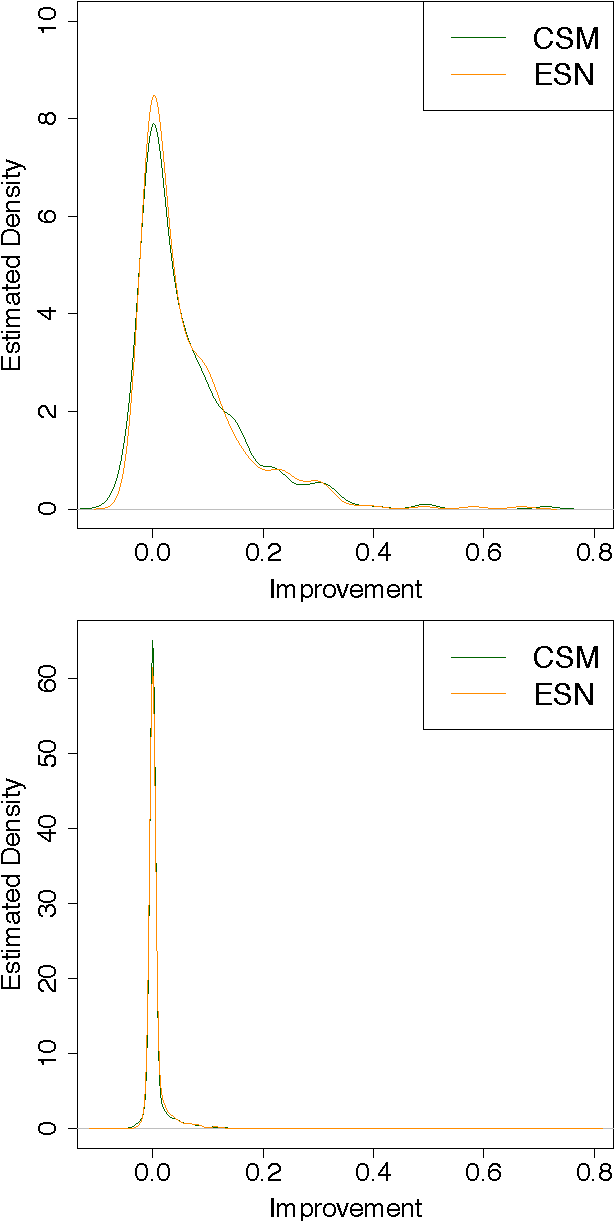
There is a large amount of interest in understanding users of social media in order to predict their behavior in this space. Despite this interest, user predictability in social media is not well-understood. To examine this question, we consider a network of fifteen thousand users on Twitter over a seven week period. We apply two contrasting modeling paradigms: computational mechanics and echo state networks. Both methods attempt to model the behavior of users on the basis of their past behavior. We demonstrate that the behavior of users on Twitter can be well-modeled as processes with self-feedback. We find that the two modeling approaches perform very similarly for most users, but that they differ in performance on a small subset of the users. By exploring the properties of these performance-differentiated users, we highlight the challenges faced in applying predictive models to dynamic social data.