Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Reversal Against Discrimination
Paper and Code
Jul 01, 2018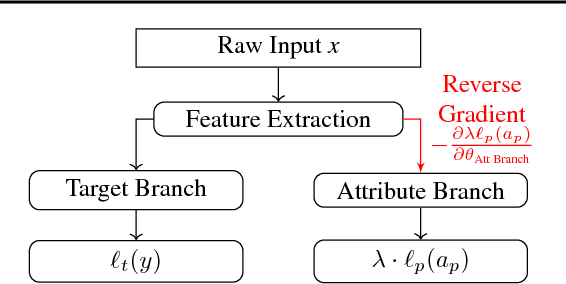
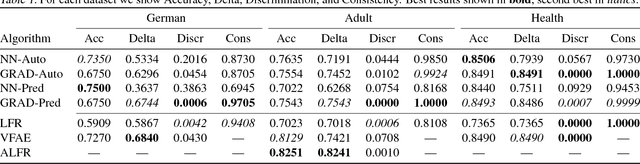
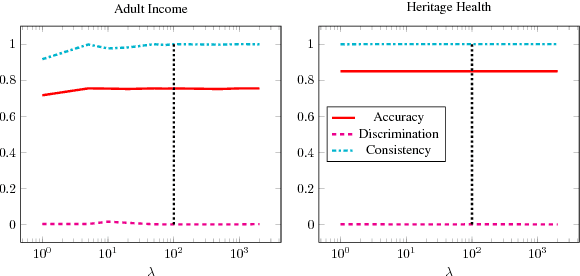
No methods currently exist for making arbitrary neural networks fair. In this work we introduce GRAD, a new and simplified method to producing fair neural networks that can be used for auto-encoding fair representations or directly with predictive networks. It is easy to implement and add to existing architectures, has only one (insensitive) hyper-parameter, and provides improved individual and group fairness. We use the flexibility of GRAD to demonstrate multi-attribute protection.
* Proceedings of the 5'th Workshop on Fairness, Accountability and
Transparency in Machine Learning, 2018
View paper on