 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Augmented Standard Plane Detection with Temporal Aggregation in Blind-Sweep Fetal Ultrasound
Apr 22, 2026In low-resource settings, blind-sweep ultrasound provides a practical and accessible method for identifying fetal growth restriction. However, unlike freehand ultrasound which is subjectively controlled, detection of biometry plane in blind-sweep ultrasound is more challenging due to the uncontrolled fetal structure to be observed and the variaties of oblique planes in the scan. In this work, we propose a structure-augmented system to detect fetal abdomen plane, where the abdominal structure is highlighted using a segmentation prior. Since standard planes are emerging gradually, the decision boundary of the keyframes is unstable to predict. We thus aggregated the structure-augmented planes with a temporal sliding window to help stabilise keyframe localisation. Extensive results indicate that the structure-augmented temporal sliding strategy significantly improves and stabilises the detection of anatomically meaningful planes, which enables more reliable biometric measurements in blind-sweep ultrasound.
Federated Continual 3D Segmentation With Single-round Communication
Mar 19, 2025



Federated learning seeks to foster collaboration among distributed clients while preserving the privacy of their local data. Traditionally, federated learning methods assume a fixed setting in which client data and learning objectives remain constant. However, in real-world scenarios, new clients may join, and existing clients may expand the segmentation label set as task requirements evolve. In such a dynamic federated analysis setup, the conventional federated communication strategy of model aggregation per communication round is suboptimal. As new clients join, this strategy requires retraining, linearly increasing communication and computation overhead. It also imposes requirements for synchronized communication, which is difficult to achieve among distributed clients. In this paper, we propose a federated continual learning strategy that employs a one-time model aggregation at the server through multi-model distillation. This approach builds and updates the global model while eliminating the need for frequent server communication. When integrating new data streams or onboarding new clients, this approach efficiently reuses previous client models, avoiding the need to retrain the global model across the entire federation. By minimizing communication load and bypassing the need to put unchanged clients online, our approach relaxes synchronization requirements among clients, providing an efficient and scalable federated analysis framework suited for real-world applications. Using multi-class 3D abdominal CT segmentation as an application task, we demonstrate the effectiveness of the proposed approach.
Pose-GuideNet: Automatic Scanning Guidance for Fetal Head Ultrasound from Pose Estimation
Aug 19, 2024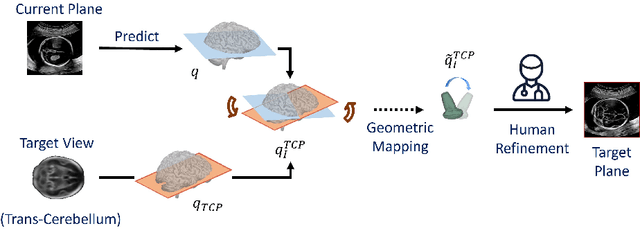
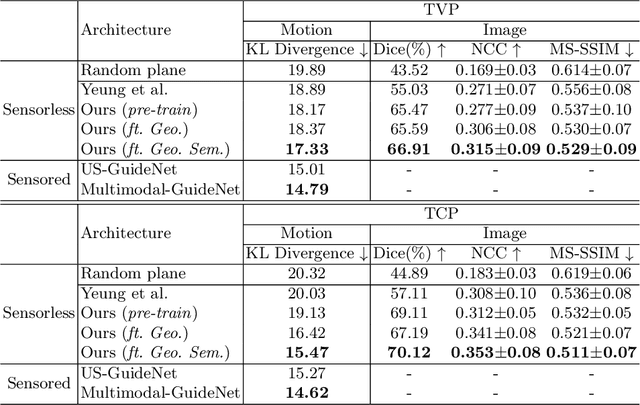
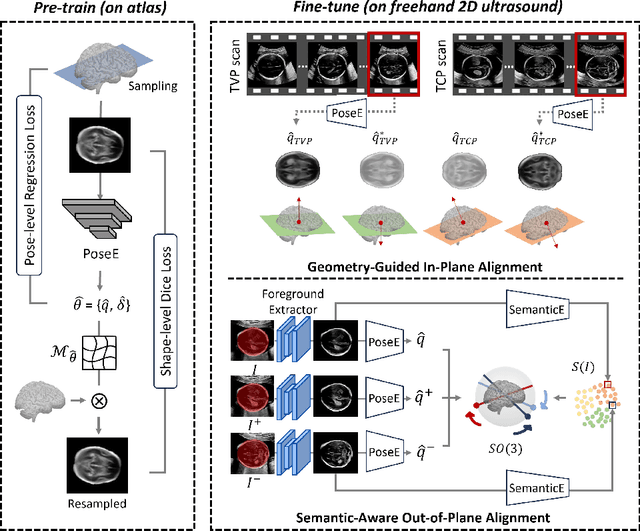
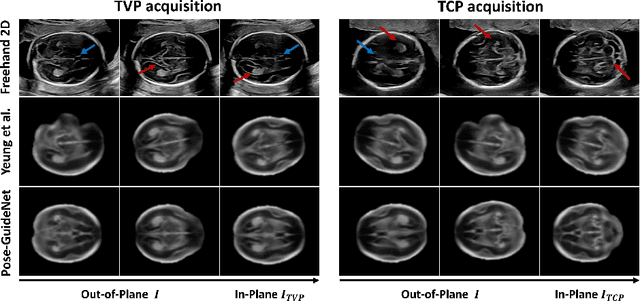
3D pose estimation from a 2D cross-sectional view enables healthcare professionals to navigate through the 3D space, and such techniques initiate automatic guidance in many image-guided radiology applications. In this work, we investigate how estimating 3D fetal pose from freehand 2D ultrasound scanning can guide a sonographer to locate a head standard plane. Fetal head pose is estimated by the proposed Pose-GuideNet, a novel 2D/3D registration approach to align freehand 2D ultrasound to a 3D anatomical atlas without the acquisition of 3D ultrasound. To facilitate the 2D to 3D cross-dimensional projection, we exploit the prior knowledge in the atlas to align the standard plane frame in a freehand scan. A semantic-aware contrastive-based approach is further proposed to align the frames that are off standard planes based on their anatomical similarity. In the experiment, we enhance the existing assessment of freehand image localization by comparing the transformation of its estimated pose towards standard plane with the corresponding probe motion, which reflects the actual view change in 3D anatomy. Extensive results on two clinical head biometry tasks show that Pose-GuideNet not only accurately predicts pose but also successfully predicts the direction of the fetal head. Evaluations with probe motions further demonstrate the feasibility of adopting Pose-GuideNet for freehand ultrasound-assisted navigation in a sensor-free environment.
MMSummary: Multimodal Summary Generation for Fetal Ultrasound Video
Aug 07, 2024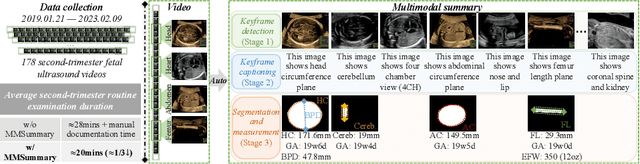

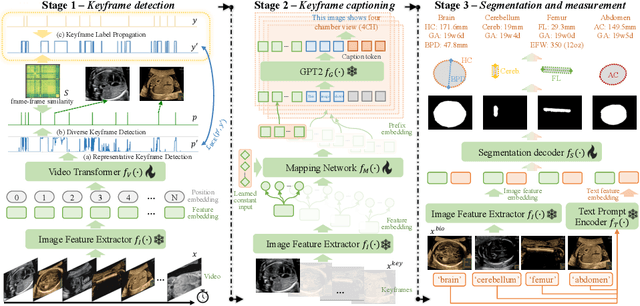
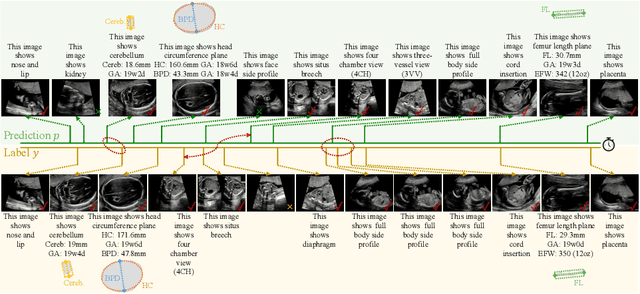
We present the first automated multimodal summary generation system, MMSummary, for medical imaging video, particularly with a focus on fetal ultrasound analysis. Imitating the examination process performed by a human sonographer, MMSummary is designed as a three-stage pipeline, progressing from keyframe detection to keyframe captioning and finally anatomy segmentation and measurement. In the keyframe detection stage, an innovative automated workflow is proposed to progressively select a concise set of keyframes, preserving sufficient video information without redundancy. Subsequently, we adapt a large language model to generate meaningful captions for fetal ultrasound keyframes in the keyframe captioning stage. If a keyframe is captioned as fetal biometry, the segmentation and measurement stage estimates biometric parameters by segmenting the region of interest according to the textual prior. The MMSummary system provides comprehensive summaries for fetal ultrasound examinations and based on reported experiments is estimated to reduce scanning time by approximately 31.5%, thereby suggesting the potential to enhance clinical workflow efficiency.
Towards Human-AI Collaboration in Healthcare: Guided Deferral Systems with Large Language Models
Jun 11, 2024Large language models (LLMs) present a valuable technology for various applications in healthcare, but their tendency to hallucinate introduces unacceptable uncertainty in critical decision-making situations. Human-AI collaboration (HAIC) can mitigate this uncertainty by combining human and AI strengths for better outcomes. This paper presents a novel guided deferral system that provides intelligent guidance when AI defers cases to human decision-makers. We leverage LLMs' verbalisation capabilities and internal states to create this system, demonstrating that fine-tuning smaller LLMs with data from larger models enhances performance while maintaining computational efficiency. A pilot study showcases the effectiveness of our deferral system.
Focalized Contrastive View-invariant Learning for Self-supervised Skeleton-based Action Recognition
Apr 03, 2023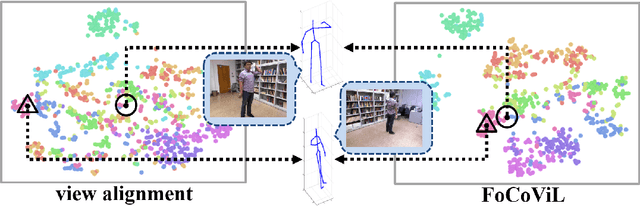



Learning view-invariant representation is a key to improving feature discrimination power for skeleton-based action recognition. Existing approaches cannot effectively remove the impact of viewpoint due to the implicit view-dependent representations. In this work, we propose a self-supervised framework called Focalized Contrastive View-invariant Learning (FoCoViL), which significantly suppresses the view-specific information on the representation space where the viewpoints are coarsely aligned. By maximizing mutual information with an effective contrastive loss between multi-view sample pairs, FoCoViL associates actions with common view-invariant properties and simultaneously separates the dissimilar ones. We further propose an adaptive focalization method based on pairwise similarity to enhance contrastive learning for a clearer cluster boundary in the learned space. Different from many existing self-supervised representation learning work that rely heavily on supervised classifiers, FoCoViL performs well on both unsupervised and supervised classifiers with superior recognition performance. Extensive experiments also show that the proposed contrastive-based focalization generates a more discriminative latent representation.
A Two-stream Convolutional Network for Musculoskeletal and Neurological Disorders Prediction
Aug 18, 2022
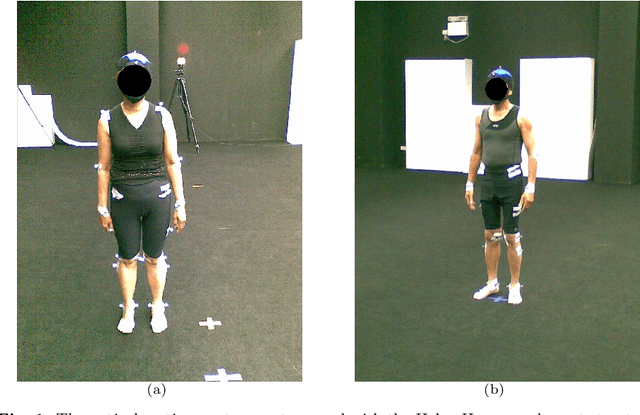

Musculoskeletal and neurological disorders are the most common causes of walking problems among older people, and they often lead to diminished quality of life. Analyzing walking motion data manually requires trained professionals and the evaluations may not always be objective. To facilitate early diagnosis, recent deep learning-based methods have shown promising results for automated analysis, which can discover patterns that have not been found in traditional machine learning methods. We observe that existing work mostly applies deep learning on individual joint features such as the time series of joint positions. Due to the challenge of discovering inter-joint features such as the distance between feet (i.e. the stride width) from generally smaller-scale medical datasets, these methods usually perform sub-optimally. As a result, we propose a solution that explicitly takes both individual joint features and inter-joint features as input, relieving the system from the need of discovering more complicated features from small data. Due to the distinctive nature of the two types of features, we introduce a two-stream framework, with one stream learning from the time series of joint position and the other from the time series of relative joint displacement. We further develop a mid-layer fusion module to combine the discovered patterns in these two streams for diagnosis, which results in a complementary representation of the data for better prediction performance. We validate our system with a benchmark dataset of 3D skeleton motion that involves 45 patients with musculoskeletal and neurological disorders, and achieve a prediction accuracy of 95.56%, outperforming state-of-the-art methods.
Interaction Mix and Match: Synthesizing Close Interaction using Conditional Hierarchical GAN with Multi-Hot Class Embedding
Aug 04, 2022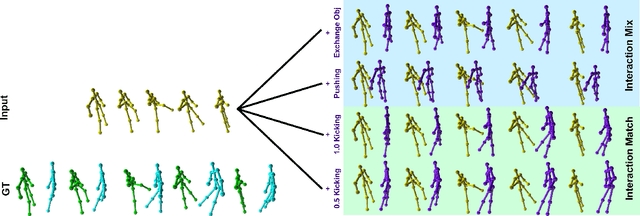
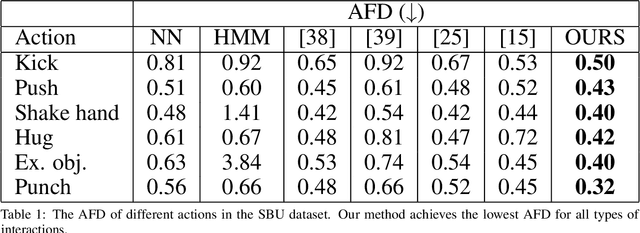
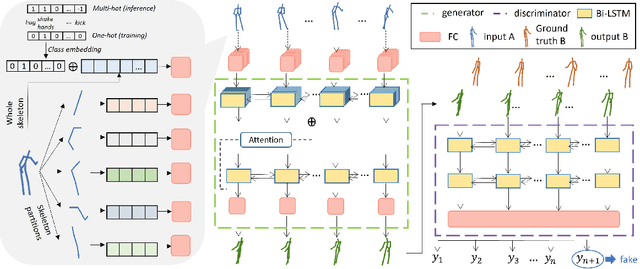

Synthesizing multi-character interactions is a challenging task due to the complex and varied interactions between the characters. In particular, precise spatiotemporal alignment between characters is required in generating close interactions such as dancing and fighting. Existing work in generating multi-character interactions focuses on generating a single type of reactive motion for a given sequence which results in a lack of variety of the resultant motions. In this paper, we propose a novel way to create realistic human reactive motions which are not presented in the given dataset by mixing and matching different types of close interactions. We propose a Conditional Hierarchical Generative Adversarial Network with Multi-Hot Class Embedding to generate the Mix and Match reactive motions of the follower from a given motion sequence of the leader. Experiments are conducted on both noisy (depth-based) and high-quality (MoCap-based) interaction datasets. The quantitative and qualitative results show that our approach outperforms the state-of-the-art methods on the given datasets. We also provide an augmented dataset with realistic reactive motions to stimulate future research in this area. The code is available at https://github.com/Aman-Goel1/IMM
Multimodal-GuideNet: Gaze-Probe Bidirectional Guidance in Obstetric Ultrasound Scanning
Jul 26, 2022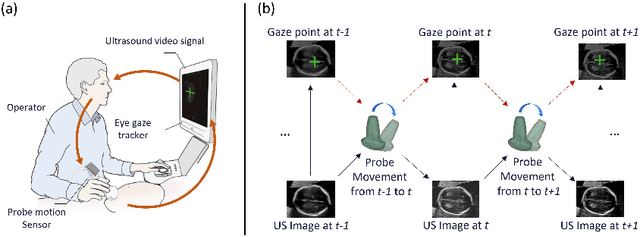
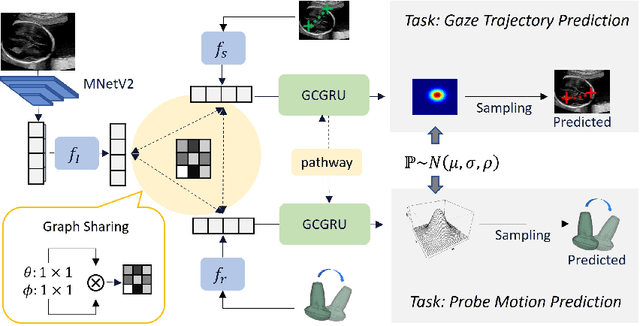
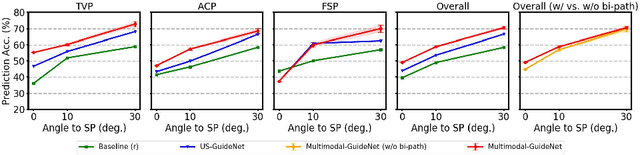
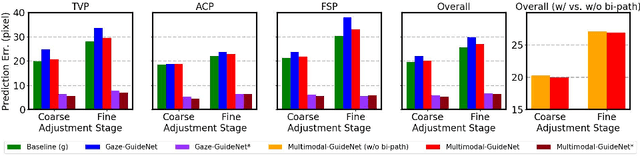
Eye trackers can provide visual guidance to sonographers during ultrasound (US) scanning. Such guidance is potentially valuable for less experienced operators to improve their scanning skills on how to manipulate the probe to achieve the desired plane. In this paper, a multimodal guidance approach (Multimodal-GuideNet) is proposed to capture the stepwise dependency between a real-world US video signal, synchronized gaze, and probe motion within a unified framework. To understand the causal relationship between gaze movement and probe motion, our model exploits multitask learning to jointly learn two related tasks: predicting gaze movements and probe signals that an experienced sonographer would perform in routine obstetric scanning. The two tasks are associated by a modality-aware spatial graph to detect the co-occurrence among the multi-modality inputs and share useful cross-modal information. Instead of a deterministic scanning path, Multimodal-GuideNet allows for scanning diversity by estimating the probability distribution of real scans. Experiments performed with three typical obstetric scanning examinations show that the new approach outperforms single-task learning for both probe motion guidance and gaze movement prediction. Multimodal-GuideNet also provides a visual guidance signal with an error rate of less than 10 pixels for a 224x288 US image.
Geometric Features Informed Multi-person Human-object Interaction Recognition in Videos
Jul 19, 2022



Human-Object Interaction (HOI) recognition in videos is important for analyzing human activity. Most existing work focusing on visual features usually suffer from occlusion in the real-world scenarios. Such a problem will be further complicated when multiple people and objects are involved in HOIs. Consider that geometric features such as human pose and object position provide meaningful information to understand HOIs, we argue to combine the benefits of both visual and geometric features in HOI recognition, and propose a novel Two-level Geometric feature-informed Graph Convolutional Network (2G-GCN). The geometric-level graph models the interdependency between geometric features of humans and objects, while the fusion-level graph further fuses them with visual features of humans and objects. To demonstrate the novelty and effectiveness of our method in challenging scenarios, we propose a new multi-person HOI dataset (MPHOI-72). Extensive experiments on MPHOI-72 (multi-person HOI), CAD-120 (single-human HOI) and Bimanual Actions (two-hand HOI) datasets demonstrate our superior performance compared to state-of-the-arts.