 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocalized Contrastive View-invariant Learning for Self-supervised Skeleton-based Action Recognition
Apr 03, 2023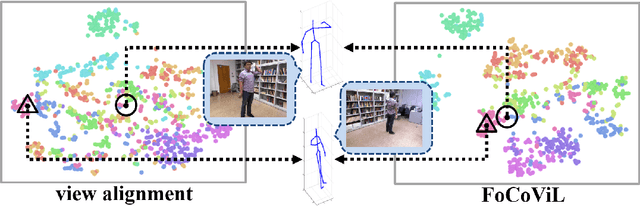



Learning view-invariant representation is a key to improving feature discrimination power for skeleton-based action recognition. Existing approaches cannot effectively remove the impact of viewpoint due to the implicit view-dependent representations. In this work, we propose a self-supervised framework called Focalized Contrastive View-invariant Learning (FoCoViL), which significantly suppresses the view-specific information on the representation space where the viewpoints are coarsely aligned. By maximizing mutual information with an effective contrastive loss between multi-view sample pairs, FoCoViL associates actions with common view-invariant properties and simultaneously separates the dissimilar ones. We further propose an adaptive focalization method based on pairwise similarity to enhance contrastive learning for a clearer cluster boundary in the learned space. Different from many existing self-supervised representation learning work that rely heavily on supervised classifiers, FoCoViL performs well on both unsupervised and supervised classifiers with superior recognition performance. Extensive experiments also show that the proposed contrastive-based focalization generates a more discriminative latent representation.
A Two-stream Convolutional Network for Musculoskeletal and Neurological Disorders Prediction
Aug 18, 2022
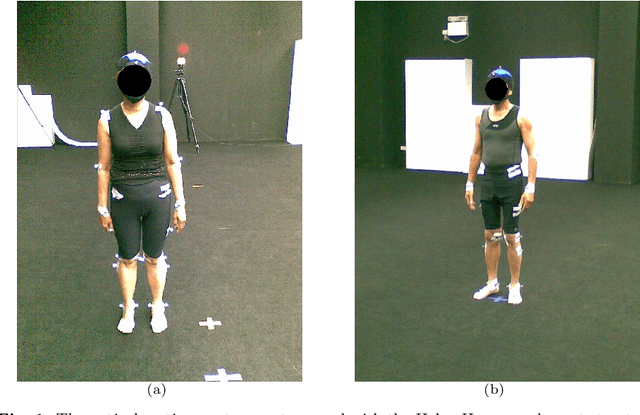

Musculoskeletal and neurological disorders are the most common causes of walking problems among older people, and they often lead to diminished quality of life. Analyzing walking motion data manually requires trained professionals and the evaluations may not always be objective. To facilitate early diagnosis, recent deep learning-based methods have shown promising results for automated analysis, which can discover patterns that have not been found in traditional machine learning methods. We observe that existing work mostly applies deep learning on individual joint features such as the time series of joint positions. Due to the challenge of discovering inter-joint features such as the distance between feet (i.e. the stride width) from generally smaller-scale medical datasets, these methods usually perform sub-optimally. As a result, we propose a solution that explicitly takes both individual joint features and inter-joint features as input, relieving the system from the need of discovering more complicated features from small data. Due to the distinctive nature of the two types of features, we introduce a two-stream framework, with one stream learning from the time series of joint position and the other from the time series of relative joint displacement. We further develop a mid-layer fusion module to combine the discovered patterns in these two streams for diagnosis, which results in a complementary representation of the data for better prediction performance. We validate our system with a benchmark dataset of 3D skeleton motion that involves 45 patients with musculoskeletal and neurological disorders, and achieve a prediction accuracy of 95.56%, outperforming state-of-the-art methods.
GAN-based Reactive Motion Synthesis with Class-aware Discriminators for Human-human Interaction
Oct 01, 2021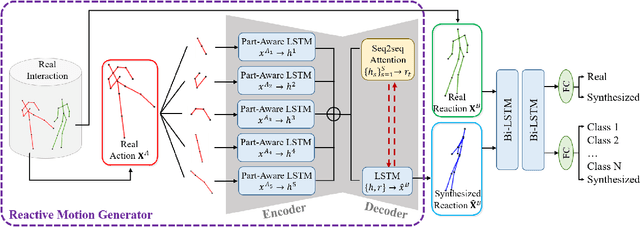
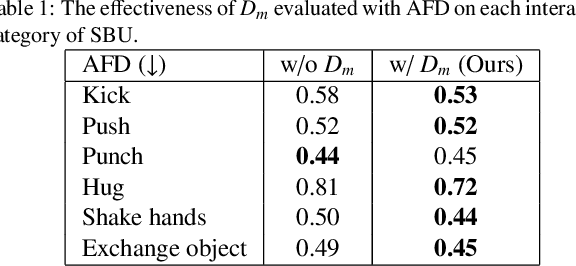

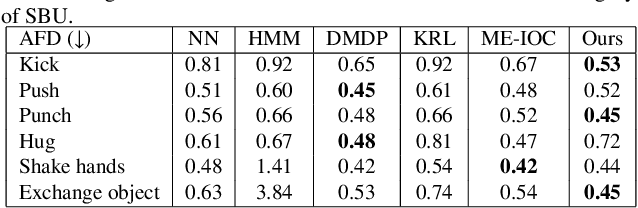
Creating realistic characters that can react to the users' or another character's movement can benefit computer graphics, games and virtual reality hugely. However, synthesizing such reactive motions in human-human interactions is a challenging task due to the many different ways two humans can interact. While there are a number of successful researches in adapting the generative adversarial network (GAN) in synthesizing single human actions, there are very few on modelling human-human interactions. In this paper, we propose a semi-supervised GAN system that synthesizes the reactive motion of a character given the active motion from another character. Our key insights are two-fold. First, to effectively encode the complicated spatial-temporal information of a human motion, we empower the generator with a part-based long short-term memory (LSTM) module, such that the temporal movement of different limbs can be effectively modelled. We further include an attention module such that the temporal significance of the interaction can be learned, which enhances the temporal alignment of the active-reactive motion pair. Second, as the reactive motion of different types of interactions can be significantly different, we introduce a discriminator that not only tells if the generated movement is realistic or not, but also tells the class label of the interaction. This allows the use of such labels in supervising the training of the generator. We experiment with the SBU and the HHOI datasets. The high quality of the synthetic motion demonstrates the effective design of our generator, and the discriminability of the synthesis also demonstrates the strength of our discriminator.
Interpreting Deep Learning based Cerebral Palsy Prediction with Channel Attention
Jun 08, 2021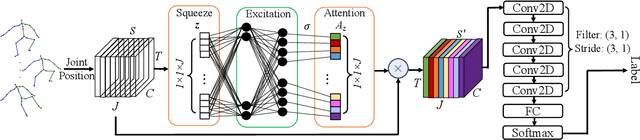
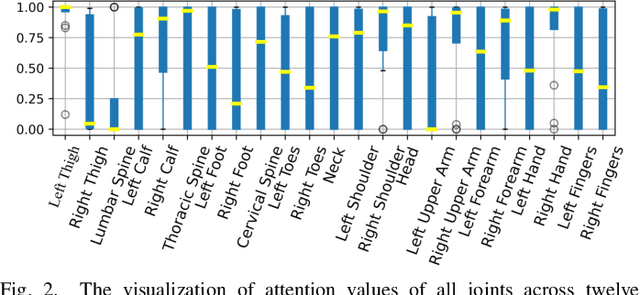
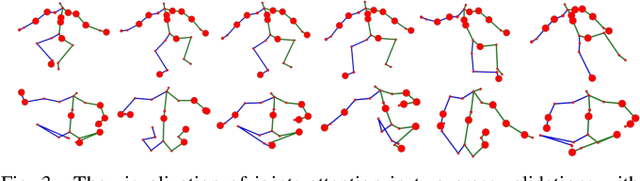
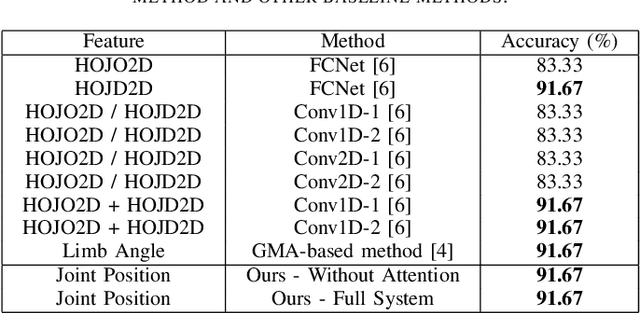
Early prediction of cerebral palsy is essential as it leads to early treatment and monitoring. Deep learning has shown promising results in biomedical engineering thanks to its capacity of modelling complicated data with its non-linear architecture. However, due to their complex structure, deep learning models are generally not interpretable by humans, making it difficult for clinicians to rely on the findings. In this paper, we propose a channel attention module for deep learning models to predict cerebral palsy from infants' body movements, which highlights the key features (i.e. body joints) the model identifies as important, thereby indicating why certain diagnostic results are found. To highlight the capacity of the deep network in modelling input features, we utilize raw joint positions instead of hand-crafted features. We validate our system with a real-world infant movement dataset. Our proposed channel attention module enables the visualization of the vital joints to this disease that the network considers. Our system achieves 91.67% accuracy, suppressing other state-of-the-art deep learning methods.
Adversarial Refinement Network for Human Motion Prediction
Nov 24, 2020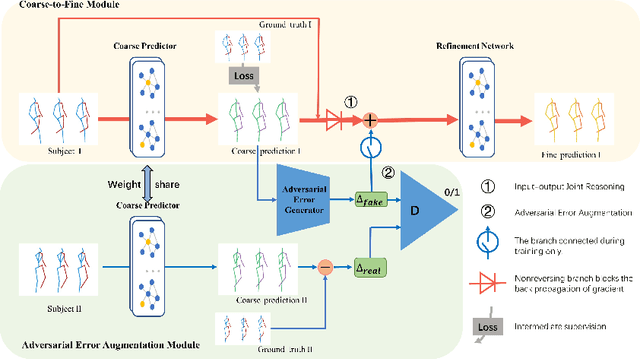
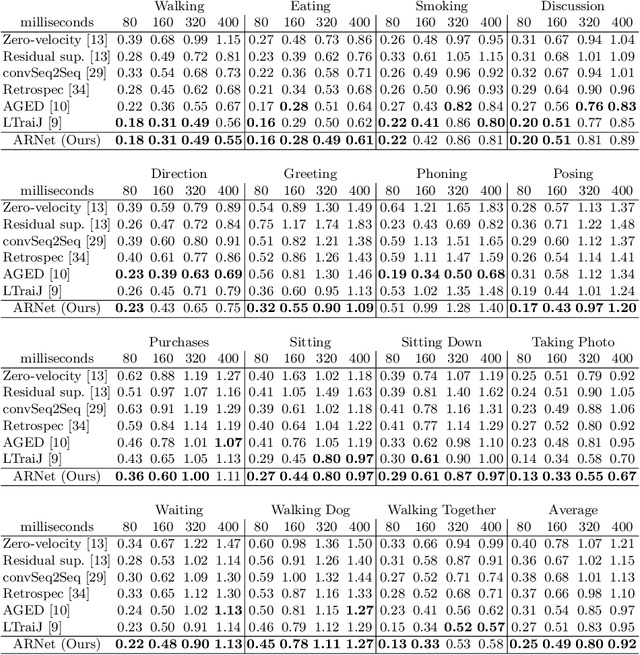
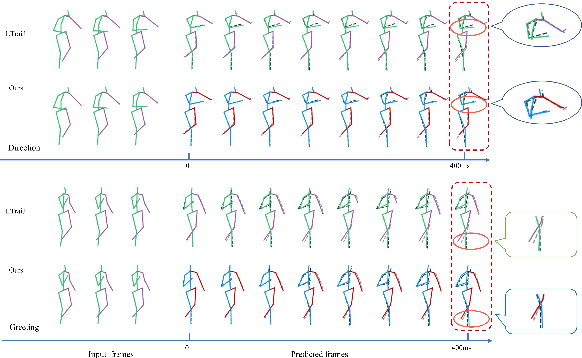
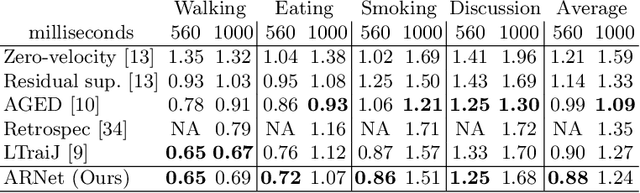
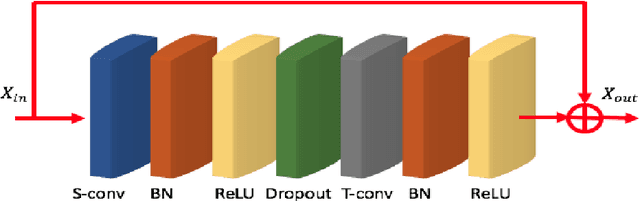
Human motion prediction aims to predict future 3D skeletal sequences by giving a limited human motion as inputs. Two popular methods, recurrent neural networks and feed-forward deep networks, are able to predict rough motion trend, but motion details such as limb movement may be lost. To predict more accurate future human motion, we propose an Adversarial Refinement Network (ARNet) following a simple yet effective coarse-to-fine mechanism with novel adversarial error augmentation. Specifically, we take both the historical motion sequences and coarse prediction as input of our cascaded refinement network to predict refined human motion and strengthen the refinement network with adversarial error augmentation. During training, we deliberately introduce the error distribution by learning through the adversarial mechanism among different subjects. In testing, our cascaded refinement network alleviates the prediction error from the coarse predictor resulting in a finer prediction robustly. This adversarial error augmentation provides rich error cases as input to our refinement network, leading to better generalization performance on the testing dataset. We conduct extensive experiments on three standard benchmark datasets and show that our proposed ARNet outperforms other state-of-the-art methods, especially on challenging aperiodic actions in both short-term and long-term predictions.
Centrality Graph Convolutional Networks for Skeleton-based Action Recognition
Mar 06, 2020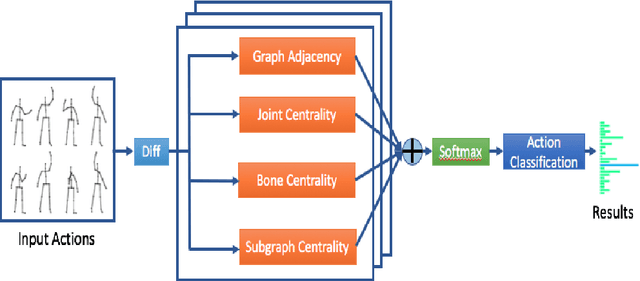


The topological structure of skeleton data plays a significant role in human action recognition. Combining the topological structure with graph convolutional networks has achieved remarkable performance. In existing methods, modeling the topological structure of skeleton data only considered the connections between the joints and bones, and directly use physical information. However, there exists an unknown problem to investigate the key joints, bones and body parts in every human action. In this paper, we propose the centrality graph convolutional networks to uncover the overlooked topological information, and best take advantage of the information to distinguish key joints, bones, and body parts. A novel centrality graph convolutional network firstly highlights the effects of the key joints and bones to bring a definite improvement. Besides, the topological information of the skeleton sequence is explored and combined to further enhance the performance in a four-channel framework. Moreover, the reconstructed graph is implemented by the adaptive methods on the training process, which further yields improvements. Our model is validated by two large-scale datasets, NTU-RGB+D and Kinetics, and outperforms the state-of-the-art methods.