 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Features Enhanced Human-Object Interaction Detection
Jun 26, 2024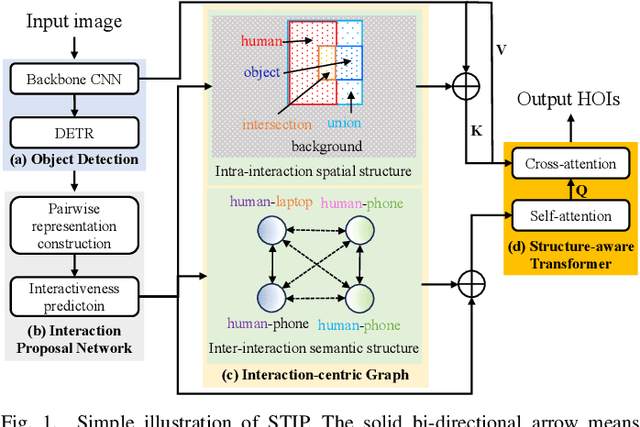


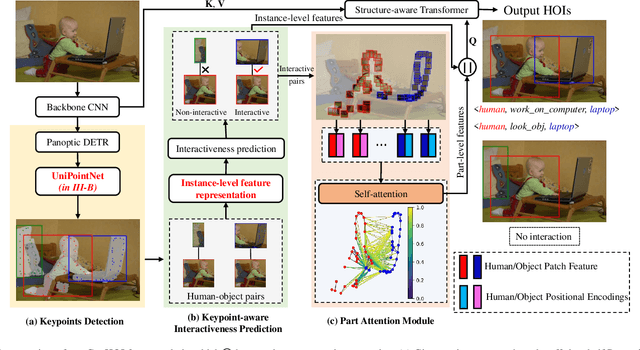
Cameras are essential vision instruments to capture images for pattern detection and measurement. Human-object interaction (HOI) detection is one of the most popular pattern detection approaches for captured human-centric visual scenes. Recently, Transformer-based models have become the dominant approach for HOI detection due to their advanced network architectures and thus promising results. However, most of them follow the one-stage design of vanilla Transformer, leaving rich geometric priors under-exploited and leading to compromised performance especially when occlusion occurs. Given that geometric features tend to outperform visual ones in occluded scenarios and offer information that complements visual cues, we propose a novel end-to-end Transformer-style HOI detection model, i.e., geometric features enhanced HOI detector (GeoHOI). One key part of the model is a new unified self-supervised keypoint learning method named UniPointNet that bridges the gap of consistent keypoint representation across diverse object categories, including humans. GeoHOI effectively upgrades a Transformer-based HOI detector benefiting from the keypoints similarities measuring the likelihood of human-object interactions as well as local keypoint patches to enhance interaction query representation, so as to boost HOI predictions. Extensive experiments show that the proposed method outperforms the state-of-the-art models on V-COCO and achieves competitive performance on HICO-DET. Case study results on the post-disaster rescue with vision-based instruments showcase the applicability of the proposed GeoHOI in real-world applications.
Detect2Interact: Localizing Object Key Field in Visual Question Answering (VQA) with LLMs
Apr 01, 2024Localization plays a crucial role in enhancing the practicality and precision of VQA systems. By enabling fine-grained identification and interaction with specific parts of an object, it significantly improves the system's ability to provide contextually relevant and spatially accurate responses, crucial for applications in dynamic environments like robotics and augmented reality. However, traditional systems face challenges in accurately mapping objects within images to generate nuanced and spatially aware responses. In this work, we introduce "Detect2Interact", which addresses these challenges by introducing an advanced approach for fine-grained object visual key field detection. First, we use the segment anything model (SAM) to generate detailed spatial maps of objects in images. Next, we use Vision Studio to extract semantic object descriptions. Third, we employ GPT-4's common sense knowledge, bridging the gap between an object's semantics and its spatial map. As a result, Detect2Interact achieves consistent qualitative results on object key field detection across extensive test cases and outperforms the existing VQA system with object detection by providing a more reasonable and finer visual representation.
A Two-stream Convolutional Network for Musculoskeletal and Neurological Disorders Prediction
Aug 18, 2022

Musculoskeletal and neurological disorders are the most common causes of walking problems among older people, and they often lead to diminished quality of life. Analyzing walking motion data manually requires trained professionals and the evaluations may not always be objective. To facilitate early diagnosis, recent deep learning-based methods have shown promising results for automated analysis, which can discover patterns that have not been found in traditional machine learning methods. We observe that existing work mostly applies deep learning on individual joint features such as the time series of joint positions. Due to the challenge of discovering inter-joint features such as the distance between feet (i.e. the stride width) from generally smaller-scale medical datasets, these methods usually perform sub-optimally. As a result, we propose a solution that explicitly takes both individual joint features and inter-joint features as input, relieving the system from the need of discovering more complicated features from small data. Due to the distinctive nature of the two types of features, we introduce a two-stream framework, with one stream learning from the time series of joint position and the other from the time series of relative joint displacement. We further develop a mid-layer fusion module to combine the discovered patterns in these two streams for diagnosis, which results in a complementary representation of the data for better prediction performance. We validate our system with a benchmark dataset of 3D skeleton motion that involves 45 patients with musculoskeletal and neurological disorders, and achieve a prediction accuracy of 95.56%, outperforming state-of-the-art methods.
A Skeleton-aware Graph Convolutional Network for Human-Object Interaction Detection
Jul 11, 2022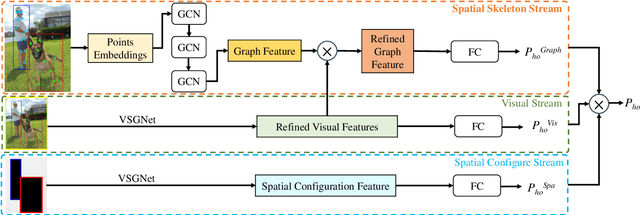


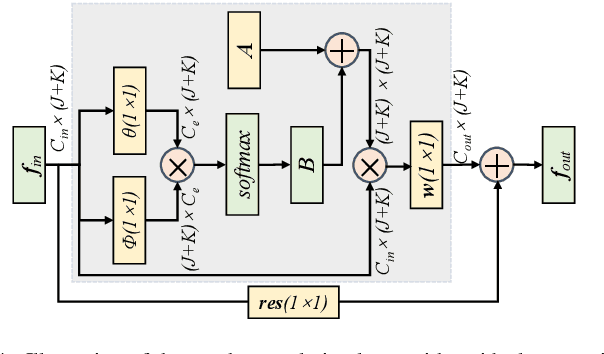
Detecting human-object interactions is essential for comprehensive understanding of visual scenes. In particular, spatial connections between humans and objects are important cues for reasoning interactions. To this end, we propose a skeleton-aware graph convolutional network for human-object interaction detection, named SGCN4HOI. Our network exploits the spatial connections between human keypoints and object keypoints to capture their fine-grained structural interactions via graph convolutions. It fuses such geometric features with visual features and spatial configuration features obtained from human-object pairs. Furthermore, to better preserve the object structural information and facilitate human-object interaction detection, we propose a novel skeleton-based object keypoints representation. The performance of SGCN4HOI is evaluated in the public benchmark V-COCO dataset. Experimental results show that the proposed approach outperforms the state-of-the-art pose-based models and achieves competitive performance against other models.
Interpreting Deep Learning based Cerebral Palsy Prediction with Channel Attention
Jun 08, 2021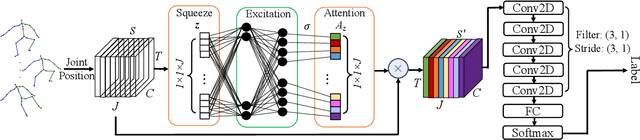
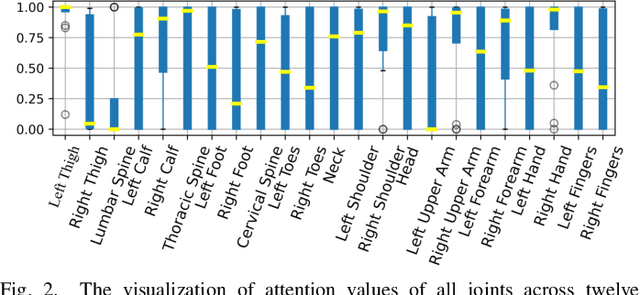
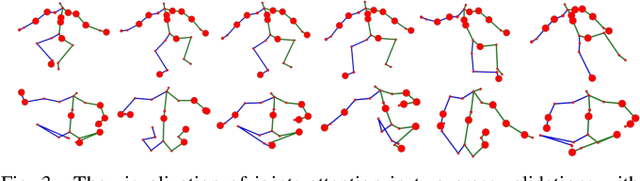
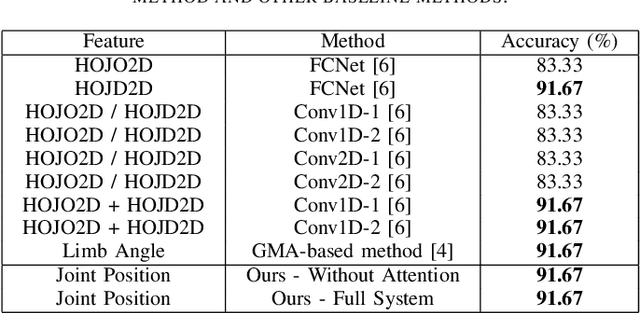
Early prediction of cerebral palsy is essential as it leads to early treatment and monitoring. Deep learning has shown promising results in biomedical engineering thanks to its capacity of modelling complicated data with its non-linear architecture. However, due to their complex structure, deep learning models are generally not interpretable by humans, making it difficult for clinicians to rely on the findings. In this paper, we propose a channel attention module for deep learning models to predict cerebral palsy from infants' body movements, which highlights the key features (i.e. body joints) the model identifies as important, thereby indicating why certain diagnostic results are found. To highlight the capacity of the deep network in modelling input features, we utilize raw joint positions instead of hand-crafted features. We validate our system with a real-world infant movement dataset. Our proposed channel attention module enables the visualization of the vital joints to this disease that the network considers. Our system achieves 91.67% accuracy, suppressing other state-of-the-art deep learning methods.