 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Skeleton-aware Graph Convolutional Network for Human-Object Interaction Detection
Paper and Code
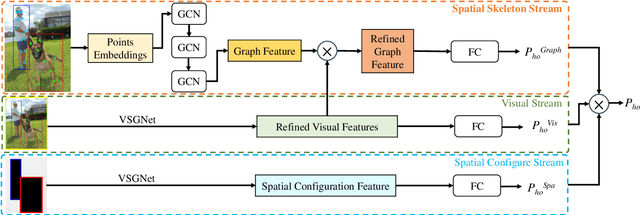


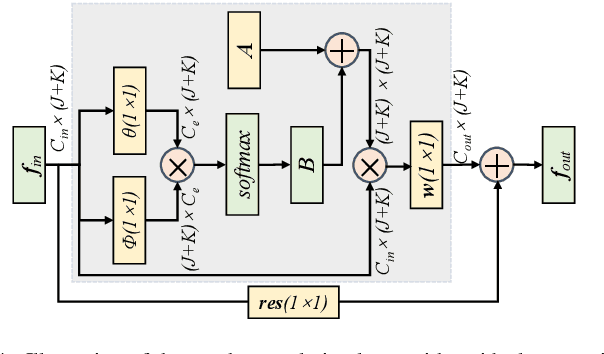
Detecting human-object interactions is essential for comprehensive understanding of visual scenes. In particular, spatial connections between humans and objects are important cues for reasoning interactions. To this end, we propose a skeleton-aware graph convolutional network for human-object interaction detection, named SGCN4HOI. Our network exploits the spatial connections between human keypoints and object keypoints to capture their fine-grained structural interactions via graph convolutions. It fuses such geometric features with visual features and spatial configuration features obtained from human-object pairs. Furthermore, to better preserve the object structural information and facilitate human-object interaction detection, we propose a novel skeleton-based object keypoints representation. The performance of SGCN4HOI is evaluated in the public benchmark V-COCO dataset. Experimental results show that the proposed approach outperforms the state-of-the-art pose-based models and achieves competitive performance against other models.