 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPLe: Token-Wise Adaptive for Multi-Modal Prompt Learning
Jan 23, 2024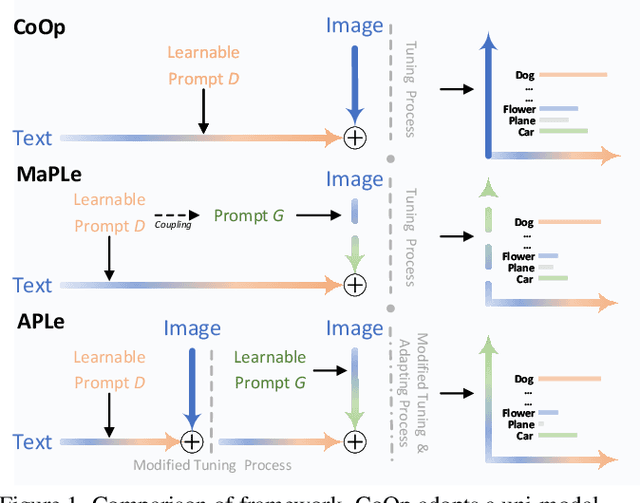
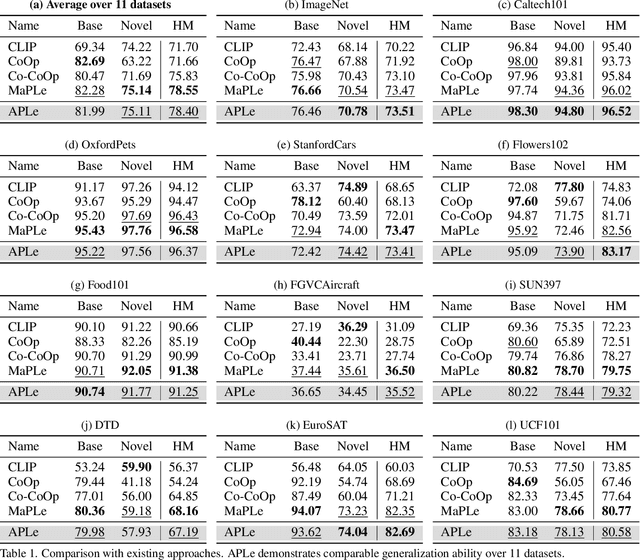
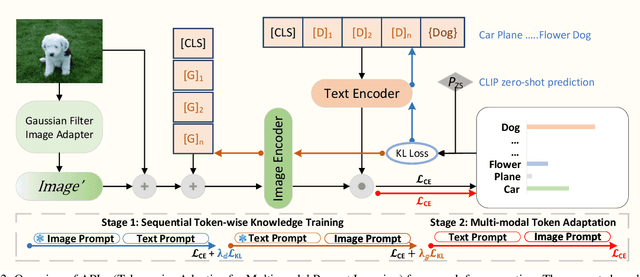
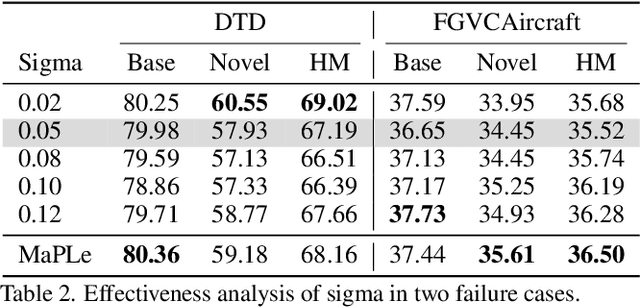
Pre-trained Vision-Language (V-L) models set the benchmark for generalization to downstream tasks among the noteworthy contenders. Many characteristics of the V-L model have been explored in existing research including the challenge of the sensitivity to text input and the tuning process across multi-modal prompts. With the advanced utilization of the V-L model like CLIP, recent approaches deploy learnable prompts instead of hand-craft prompts to boost the generalization performance and address the aforementioned challenges. Inspired by layer-wise training, which is wildly used in image fusion, we note that using a sequential training process to adapt different modalities branches of CLIP efficiently facilitates the improvement of generalization. In the context of addressing the multi-modal prompting challenge, we propose Token-wise Adaptive for Multi-modal Prompt Learning (APLe) for tuning both modalities prompts, vision and language, as tokens in a sequential manner. APLe addresses the challenges in V-L models to promote prompt learning across both modalities, which indicates a competitive generalization performance in line with the state-of-the-art. Preeminently, APLe shows robustness and favourable performance in prompt-length experiments with an absolute advantage in adopting the V-L models.
Progression-Guided Temporal Action Detection in Videos
Aug 18, 2023



We present a novel framework, Action Progression Network (APN), for temporal action detection (TAD) in videos. The framework locates actions in videos by detecting the action evolution process. To encode the action evolution, we quantify a complete action process into 101 ordered stages (0\%, 1\%, ..., 100\%), referred to as action progressions. We then train a neural network to recognize the action progressions. The framework detects action boundaries by detecting complete action processes in the videos, e.g., a video segment with detected action progressions closely follow the sequence 0\%, 1\%, ..., 100\%. The framework offers three major advantages: (1) Our neural networks are trained end-to-end, contrasting conventional methods that optimize modules separately; (2) The APN is trained using action frames exclusively, enabling models to be trained on action classification datasets and robust to videos with temporal background styles differing from those in training; (3) Our framework effectively avoids detecting incomplete actions and excels in detecting long-lasting actions due to the fine-grained and explicit encoding of the temporal structure of actions. Leveraging these advantages, the APN achieves competitive performance and significantly surpasses its counterparts in detecting long-lasting actions. With an IoU threshold of 0.5, the APN achieves a mean Average Precision (mAP) of 58.3\% on the THUMOS14 dataset and 98.9\% mAP on the DFMAD70 dataset.
Serial-parallel Multi-Scale Feature Fusion for Anatomy-Oriented Hand Joint Detection
Feb 19, 2021

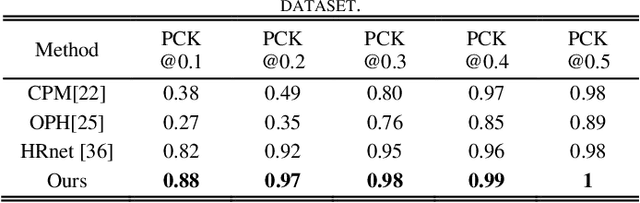

Accurate hand joints detection from images is a fundamental topic which is essential for many applications in computer vision and human computer interaction. This paper presents a two stage network for hand joints detection from single unmarked image by using serial-parallel multi-scale feature fusion. In stage I, the hand regions are located by a pre-trained network, and the features of each detected hand region are extracted by a shallow spatial hand features representation module. The extracted hand features are then fed into stage II, which consists of serially connected feature extraction modules with similar structures, called "multi-scale feature fusion" (MSFF). A MSFF contains parallel multi-scale feature extraction branches, which generate initial hand joint heatmaps. The initial heatmaps are then mutually reinforced by the anatomic relationship between hand joints. The experimental results on five hand joints datasets show that the proposed network overperforms the state-of-the-art methods.
Centrality Graph Convolutional Networks for Skeleton-based Action Recognition
Mar 06, 2020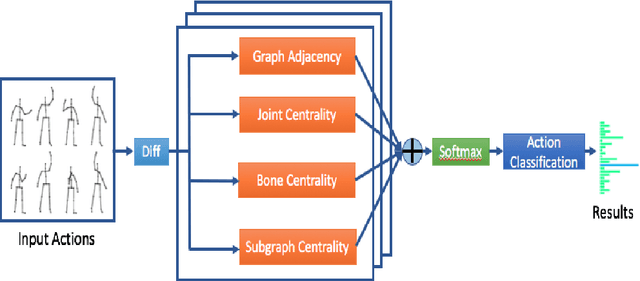

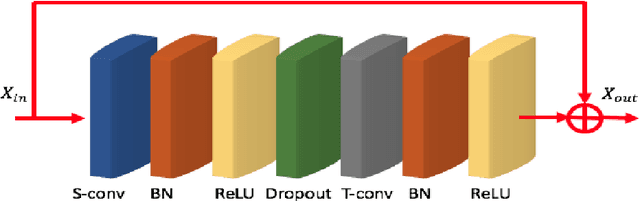

The topological structure of skeleton data plays a significant role in human action recognition. Combining the topological structure with graph convolutional networks has achieved remarkable performance. In existing methods, modeling the topological structure of skeleton data only considered the connections between the joints and bones, and directly use physical information. However, there exists an unknown problem to investigate the key joints, bones and body parts in every human action. In this paper, we propose the centrality graph convolutional networks to uncover the overlooked topological information, and best take advantage of the information to distinguish key joints, bones, and body parts. A novel centrality graph convolutional network firstly highlights the effects of the key joints and bones to bring a definite improvement. Besides, the topological information of the skeleton sequence is explored and combined to further enhance the performance in a four-channel framework. Moreover, the reconstructed graph is implemented by the adaptive methods on the training process, which further yields improvements. Our model is validated by two large-scale datasets, NTU-RGB+D and Kinetics, and outperforms the state-of-the-art methods.