 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEEL: A Framework for Evaluating Emotional Support Capability with Large Language Models
Mar 23, 2024Emotional Support Conversation (ESC) is a typical dialogue that can effec-tively assist the user in mitigating emotional pressures. However, owing to the inherent subjectivity involved in analyzing emotions, current non-artificial methodologies face challenges in effectively appraising the emo-tional support capability. These metrics exhibit a low correlation with human judgments. Concurrently, manual evaluation methods extremely will cause high costs. To solve these problems, we propose a novel model FEEL (Framework for Evaluating Emotional Support Capability with Large Lan-guage Models), employing Large Language Models (LLMs) as evaluators to assess emotional support capabilities. The model meticulously considers var-ious evaluative aspects of ESC to apply a more comprehensive and accurate evaluation method for ESC. Additionally, it employs a probability distribu-tion approach for a more stable result and integrates an ensemble learning strategy, leveraging multiple LLMs with assigned weights to enhance evalua-tion accuracy. To appraise the performance of FEEL, we conduct extensive experiments on existing ESC model dialogues. Experimental results demon-strate our model exhibits a substantial enhancement in alignment with human evaluations compared to the baselines. Our source code is available at https://github.com/Ansisy/FEEL.
APLe: Token-Wise Adaptive for Multi-Modal Prompt Learning
Jan 23, 2024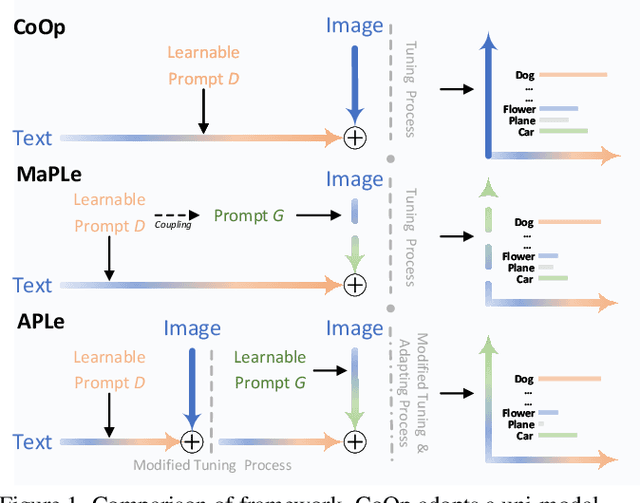
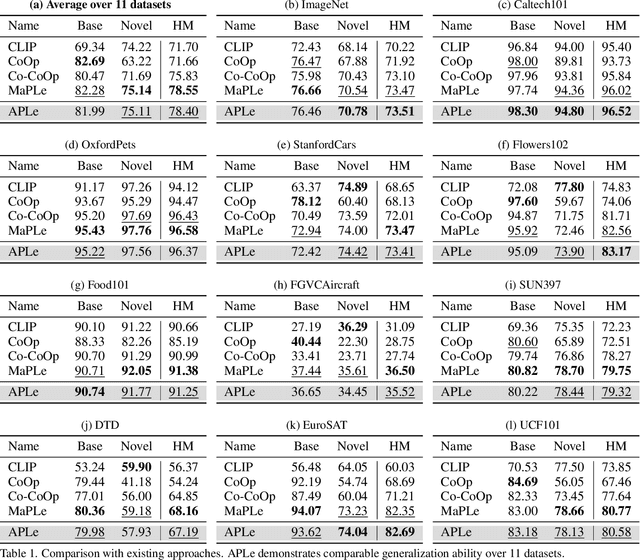
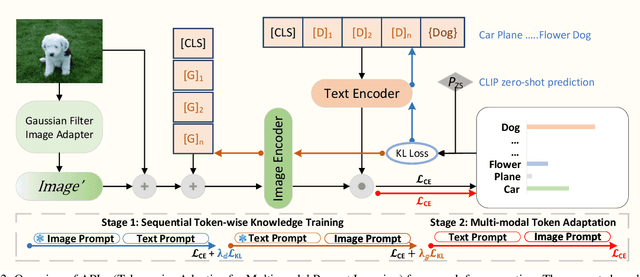
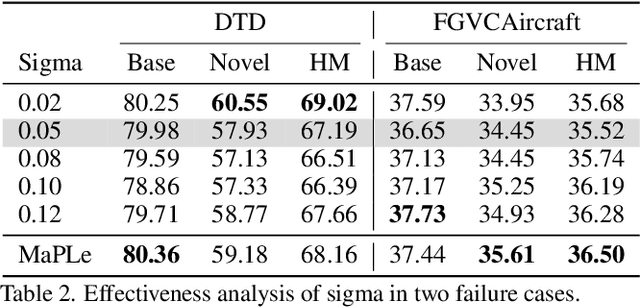
Pre-trained Vision-Language (V-L) models set the benchmark for generalization to downstream tasks among the noteworthy contenders. Many characteristics of the V-L model have been explored in existing research including the challenge of the sensitivity to text input and the tuning process across multi-modal prompts. With the advanced utilization of the V-L model like CLIP, recent approaches deploy learnable prompts instead of hand-craft prompts to boost the generalization performance and address the aforementioned challenges. Inspired by layer-wise training, which is wildly used in image fusion, we note that using a sequential training process to adapt different modalities branches of CLIP efficiently facilitates the improvement of generalization. In the context of addressing the multi-modal prompting challenge, we propose Token-wise Adaptive for Multi-modal Prompt Learning (APLe) for tuning both modalities prompts, vision and language, as tokens in a sequential manner. APLe addresses the challenges in V-L models to promote prompt learning across both modalities, which indicates a competitive generalization performance in line with the state-of-the-art. Preeminently, APLe shows robustness and favourable performance in prompt-length experiments with an absolute advantage in adopting the V-L models.
Erasing Self-Supervised Learning Backdoor by Cluster Activation Masking
Dec 13, 2023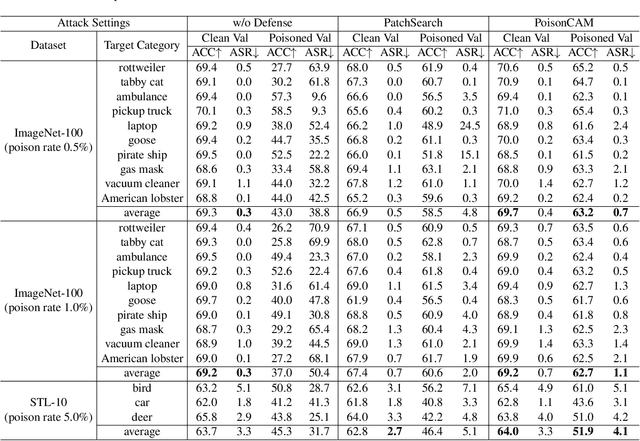
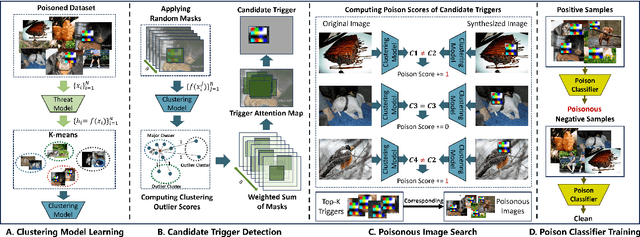

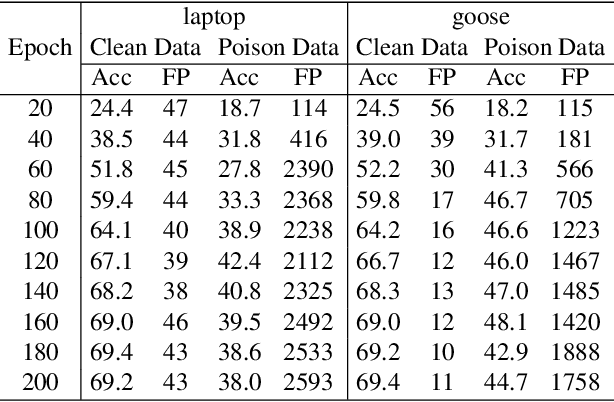
Researchers have recently found that Self-Supervised Learning (SSL) is vulnerable to backdoor attacks. The attacker can embed hidden SSL backdoors via a few poisoned examples in the training dataset and maliciously manipulate the behavior of downstream models. To defend against SSL backdoor attacks, a feasible route is to detect and remove the poisonous samples in the training set. However, the existing SSL backdoor defense method fails to detect the poisonous samples precisely. In this paper, we propose to erase the SSL backdoor by cluster activation masking and propose a novel PoisonCAM method. After obtaining the threat model trained on the poisoned dataset, our method can precisely detect poisonous samples based on the assumption that masking the backdoor trigger can effectively change the activation of a downstream clustering model. In experiments, our PoisonCAM achieves 96% accuracy for backdoor trigger detection compared to 3% of the state-of-the-art method on poisoned ImageNet-100. Moreover, our proposed PoisonCAM significantly improves the performance of the trained SSL model under backdoor attacks compared to the state-of-the-art method. Our code will be available at https://github.com/LivXue/PoisonCAM.
Efficient Graph Deep Learning in TensorFlow with tf_geometric
Jan 27, 2021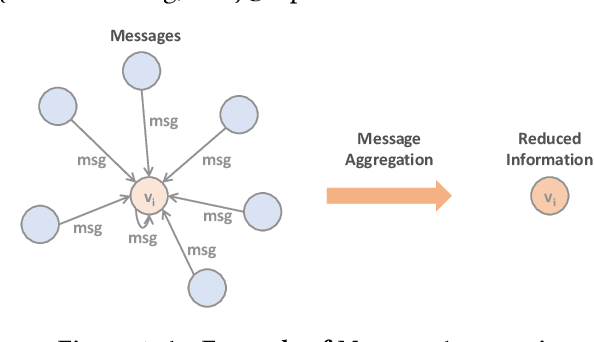
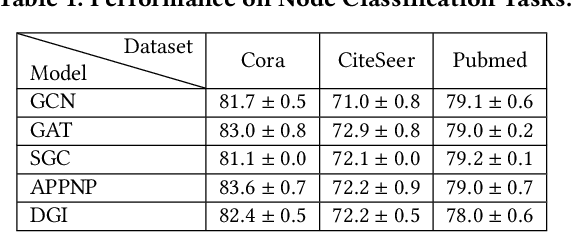
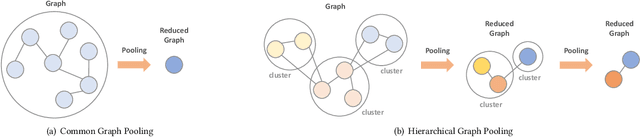
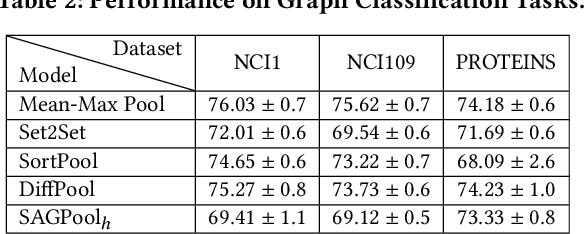
We introduce tf_geometric, an efficient and friendly library for graph deep learning, which is compatible with both TensorFlow 1.x and 2.x. tf_geometric provides kernel libraries for building Graph Neural Networks (GNNs) as well as implementations of popular GNNs. The kernel libraries consist of infrastructures for building efficient GNNs, including graph data structures, graph map-reduce framework, graph mini-batch strategy, etc. These infrastructures enable tf_geometric to support single-graph computation, multi-graph computation, graph mini-batch, distributed training, etc.; therefore, tf_geometric can be used for a variety of graph deep learning tasks, such as transductive node classification, inductive node classification, link prediction, and graph classification. Based on the kernel libraries, tf_geometric implements a variety of popular GNN models for different tasks. To facilitate the implementation of GNNs, tf_geometric also provides some other libraries for dataset management, graph sampling, etc. Different from existing popular GNN libraries, tf_geometric provides not only Object-Oriented Programming (OOP) APIs, but also Functional APIs, which enable tf_geometric to handle advanced graph deep learning tasks such as graph meta-learning. The APIs of tf_geometric are friendly, and they are suitable for both beginners and experts. In this paper, we first present an overview of tf_geometric's framework. Then, we conduct experiments on some benchmark datasets and report the performance of several popular GNN models implemented by tf_geometric.