 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHulluEdit: Single-Pass Evidence-Consistent Subspace Editing for Mitigating Hallucinations in Large Vision-Language Models
Feb 26, 2026Object hallucination in Large Vision-Language Models (LVLMs) significantly hinders their reliable deployment. Existing methods struggle to balance efficiency and accuracy: they often require expensive reference models and multiple forward passes, or apply static edits that risk suppressing genuine visual evidence. To address this, we introduce HulluEdit, a single-pass, reference-free intervention framework. Our core innovation is orthogonal subspace editing: we decompose the hidden states of the model into orthogonal subspaces - visual evidence, conflicting priors, and residual uncertainty - enabling selective suppression of hallucinatory patterns without interfering with visual grounding. This approach mathematically guarantees that edits applied to the prior subspace leave the visual component entirely unaffected. Extensive experiments show that HulluEdit achieves state-of-the-art hallucination reduction on benchmarks including POPE and CHAIR across diverse architectures, while preserving general capabilities on MME and maintaining efficient inference. Our method consistently outperforms contrastive decoding and static subspace editing baselines, offering a new pathway toward more trustworthy LVLMs.
Modality-Guided Mixture of Graph Experts with Entropy-Triggered Routing for Multimodal Recommendation
Feb 26, 2026Multimodal recommendation enhances ranking by integrating user-item interactions with item content, which is particularly effective under sparse feedback and long-tail distributions. However, multimodal signals are inherently heterogeneous and can conflict in specific contexts, making effective fusion both crucial and challenging. Existing approaches often rely on shared fusion pathways, leading to entangled representations and modality imbalance. To address these issues, we propose MAGNET, a Modality-Guided Mixture of Adaptive Graph Experts Network with Progressive Entropy-Triggered Routing for Multimodal Recommendation, designed to enhance controllability, stability, and interpretability in multimodal fusion. MAGNET couples interaction-conditioned expert routing with structure-aware graph augmentation, so that both what to fuse and how to fuse are explicitly controlled and interpretable. At the representation level, a dual-view graph learning module augments the interaction graph with content-induced edges, improving coverage for sparse and long-tail items while preserving collaborative structure via parallel encoding and lightweight fusion. At the fusion level, MAGNET employs structured experts with explicit modality roles-dominant, balanced, and complementary-enabling a more interpretable and adaptive combination of behavioral, visual, and textual cues. To further stabilize sparse routing and prevent expert collapse, we introduce a two-stage entropy-weighting mechanism that monitors routing entropy. This mechanism automatically transitions training from an early coverage-oriented regime to a later specialization-oriented regime, progressively balancing expert utilization and routing confidence. Extensive experiments on public benchmarks demonstrate consistent improvements over strong baselines.
Cross-Modal Attention Network with Dual Graph Learning in Multimodal Recommendation
Jan 16, 2026Multimedia recommendation systems leverage user-item interactions and multimodal information to capture user preferences, enabling more accurate and personalized recommendations. Despite notable advancements, existing approaches still face two critical limitations: first, shallow modality fusion often relies on simple concatenation, failing to exploit rich synergic intra- and inter-modal relationships; second, asymmetric feature treatment-where users are only characterized by interaction IDs while items benefit from rich multimodal content-hinders the learning of a shared semantic space. To address these issues, we propose a Cross-modal Recursive Attention Network with dual graph Embedding (CRANE). To tackle shallow fusion, we design a core Recursive Cross-Modal Attention (RCA) mechanism that iteratively refines modality features based on cross-correlations in a joint latent space, effectively capturing high-order intra- and inter-modal dependencies. For symmetric multimodal learning, we explicitly construct users' multimodal profiles by aggregating features of their interacted items. Furthermore, CRANE integrates a symmetric dual-graph framework-comprising a heterogeneous user-item interaction graph and a homogeneous item-item semantic graph-unified by a self-supervised contrastive learning objective to fuse behavioral and semantic signals. Despite these complex modeling capabilities, CRANE maintains high computational efficiency. Theoretical and empirical analyses confirm its scalability and high practical efficiency, achieving faster convergence on small datasets and superior performance ceilings on large-scale ones. Comprehensive experiments on four public real-world datasets validate an average 5% improvement in key metrics over state-of-the-art baselines.
Knots: A Large-Scale Multi-Agent Enhanced Expert-Annotated Dataset and LLM Prompt Optimization for NOTAM Semantic Parsing
Nov 16, 2025Notice to Air Missions (NOTAMs) serve as a critical channel for disseminating key flight safety information, yet their complex linguistic structures and implicit reasoning pose significant challenges for automated parsing. Existing research mainly focuses on surface-level tasks such as classification and named entity recognition, lacking deep semantic understanding. To address this gap, we propose NOTAM semantic parsing, a task emphasizing semantic inference and the integration of aviation domain knowledge to produce structured, inference-rich outputs. To support this task, we construct Knots (Knowledge and NOTAM Semantics), a high-quality dataset of 12,347 expert-annotated NOTAMs covering 194 Flight Information Regions, enhanced through a multi-agent collaborative framework for comprehensive field discovery. We systematically evaluate a wide range of prompt-engineering strategies and model-adaptation techniques, achieving substantial improvements in aviation text understanding and processing. Our experimental results demonstrate the effectiveness of the proposed approach and offer valuable insights for automated NOTAM analysis systems. Our code is available at: https://github.com/Estrellajer/Knots.
NOTAM-Evolve: A Knowledge-Guided Self-Evolving Optimization Framework with LLMs for NOTAM Interpretation
Nov 11, 2025Accurate interpretation of Notices to Airmen (NOTAMs) is critical for aviation safety, yet their condensed and cryptic language poses significant challenges to both manual and automated processing. Existing automated systems are typically limited to shallow parsing, failing to extract the actionable intelligence needed for operational decisions. We formalize the complete interpretation task as deep parsing, a dual-reasoning challenge requiring both dynamic knowledge grounding (linking the NOTAM to evolving real-world aeronautical data) and schema-based inference (applying static domain rules to deduce operational status). To tackle this challenge, we propose NOTAM-Evolve, a self-evolving framework that enables a large language model (LLM) to autonomously master complex NOTAM interpretation. Leveraging a knowledge graph-enhanced retrieval module for data grounding, the framework introduces a closed-loop learning process where the LLM progressively improves from its own outputs, minimizing the need for extensive human-annotated reasoning traces. In conjunction with this framework, we introduce a new benchmark dataset of 10,000 expert-annotated NOTAMs. Our experiments demonstrate that NOTAM-Evolve achieves a 30.4% absolute accuracy improvement over the base LLM, establishing a new state of the art on the task of structured NOTAM interpretation.
Stance-Driven Multimodal Controlled Statement Generation: New Dataset and Task
Apr 04, 2025



Formulating statements that support diverse or controversial stances on specific topics is vital for platforms that enable user expression, reshape political discourse, and drive social critique and information dissemination. With the rise of Large Language Models (LLMs), controllable text generation towards specific stances has become a promising research area with applications in shaping public opinion and commercial marketing. However, current datasets often focus solely on pure texts, lacking multimodal content and effective context, particularly in the context of stance detection. In this paper, we formally define and study the new problem of stance-driven controllable content generation for tweets with text and images, where given a multimodal post (text and image/video), a model generates a stance-controlled response. To this end, we create the Multimodal Stance Generation Dataset (StanceGen2024), the first resource explicitly designed for multimodal stance-controllable text generation in political discourse. It includes posts and user comments from the 2024 U.S. presidential election, featuring text, images, videos, and stance annotations to explore how multimodal political content shapes stance expression. Furthermore, we propose a Stance-Driven Multimodal Generation (SDMG) framework that integrates weighted fusion of multimodal features and stance guidance to improve semantic consistency and stance control. We release the dataset and code (https://anonymous.4open.science/r/StanceGen-BE9D) for public use and further research.
ASFT: Aligned Supervised Fine-Tuning through Absolute Likelihood
Sep 14, 2024



Direct Preference Optimization (DPO) is a method for enhancing model performance by directly optimizing for the preferences or rankings of outcomes, instead of traditional loss functions. This approach has proven effective in aligning Large Language Models (LLMs) with human preferences. Despite its widespread use across various tasks, DPO has been criticized for its sensitivity to the effectiveness of Supervised Fine-Tuning (SFT) and its limitations in enabling models to learn human-preferred responses, leading to less satisfactory performance. To address these limitations, we propose Aligned Supervised Fine-Tuning (ASFT), an effective approach that better aligns LLMs with pair-wise datasets by optimizing absolute likelihood for each response, rather than using the Bradley-Terry model, and eliminates the need for a reference model. Through theoretical gradient analysis, we demonstrate that ASFT mitigates the issue where the DPO loss function decreases the probability of generating human-dispreferred data at a faster rate than it increases the probability of producing preferred data. Additionally, we compare ASFT to DPO and its latest variants, such as the single-step approach ORPO, using the latest instruction-tuned model Llama3, which has been fine-tuned on UltraFeedback and HH-RLHF. We evaluated performance on instruction-following benchmarks like MT-Bench and traditional text generation metrics such as BLEU-4 and ROUGE-L. Extensive experiments demonstrate that ASFT is an effective alignment approach, consistently outperforming existing methods.
MGDCF: Distance Learning via Markov Graph Diffusion for Neural Collaborative Filtering
Apr 05, 2022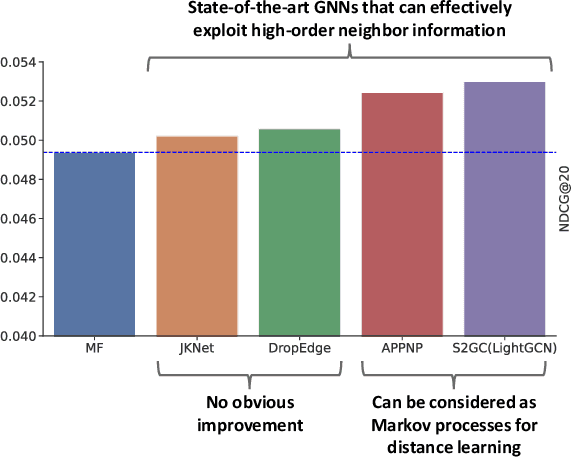
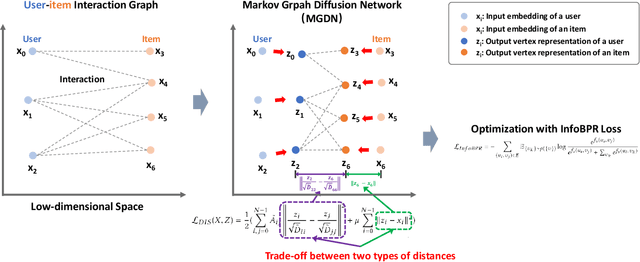

Collaborative filtering (CF) is widely used by personalized recommendation systems, which aims to predict the preference of users with historical user-item interactions. In recent years, Graph Neural Networks (GNNs) have been utilized to build CF models and have shown promising performance. Recent state-of-the-art GNN-based CF approaches simply attribute their performance improvement to the high-order neighbor aggregation ability of GNNs. However, we observe that some powerful deep GNNs such as JKNet and DropEdge, can effectively exploit high-order neighbor information on other graph tasks but perform poorly on CF tasks, which conflicts with the explanation of these GNN-based CF research. Different from these research, we investigate the GNN-based CF from the perspective of Markov processes for distance learning with a unified framework named Markov Graph Diffusion Collaborative Filtering (MGDCF). We design a Markov Graph Diffusion Network (MGDN) as MGDCF's GNN encoder, which learns vertex representations by trading off two types of distances via a Markov process. We show the theoretical equivalence between MGDN's output and the optimal solution of a distance loss function, which can boost the optimization of CF models. MGDN can generalize state-of-the-art models such as LightGCN and APPNP, which are heterogeneous GNNs. In addition, MGDN can be extended to homogeneous GNNs with our sparsification technique. For optimizing MGDCF, we propose the InfoBPR loss function, which extends the widely used BPR loss to exploit multiple negative samples for better performance. We conduct experiments to perform detailed analysis on MGDCF. The source code is publicly available at https://github.com/hujunxianligong/MGDCF.
GRecX: An Efficient and Unified Benchmark for GNN-based Recommendation
Dec 03, 2021
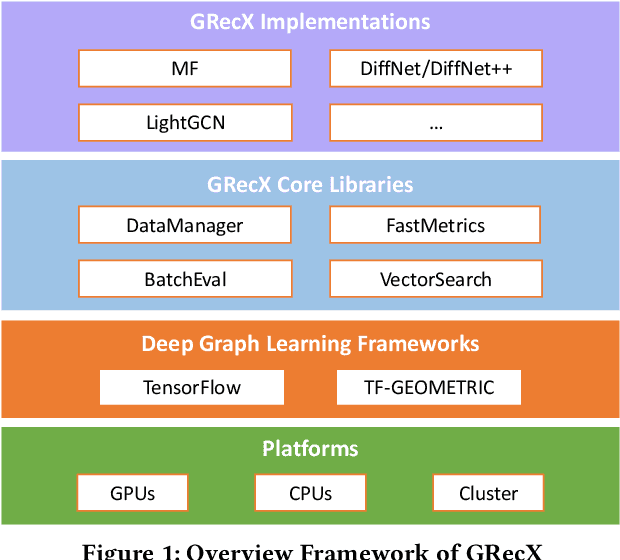
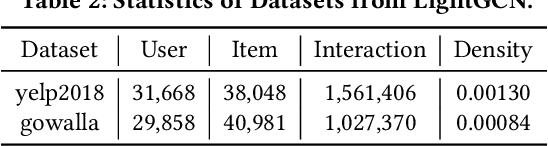
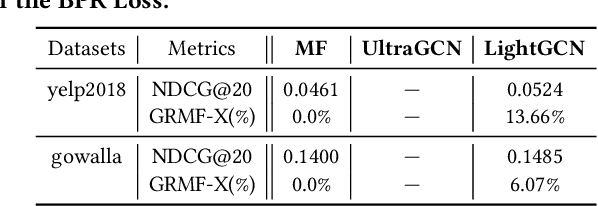
In this paper, we present GRecX, an open-source TensorFlow framework for benchmarking GNN-based recommendation models in an efficient and unified way. GRecX consists of core libraries for building GNN-based recommendation benchmarks, as well as the implementations of popular GNN-based recommendation models. The core libraries provide essential components for building efficient and unified benchmarks, including FastMetrics (efficient metrics computation libraries), VectorSearch (efficient similarity search libraries for dense vectors), BatchEval (efficient mini-batch evaluation libraries), and DataManager (unified dataset management libraries). Especially, to provide a unified benchmark for the fair comparison of different complex GNN-based recommendation models, we design a new metric GRMF-X and integrate it into the FastMetrics component. Based on a TensorFlow GNN library tf_geometric, GRecX carefully implements a variety of popular GNN-based recommendation models. We carefully implement these baseline models to reproduce the performance reported in the literature, and our implementations are usually more efficient and friendly. In conclusion, GRecX enables uses to train and benchmark GNN-based recommendation baselines in an efficient and unified way. We conduct experiments with GRecX, and the experimental results show that GRecX allows us to train and benchmark GNN-based recommendation baselines in an efficient and unified way. The source code of GRecX is available at https://github.com/maenzhier/GRecX.
Contrastive Adaptive Propagation Graph Neural Networks for Efficient Graph Learning
Dec 02, 2021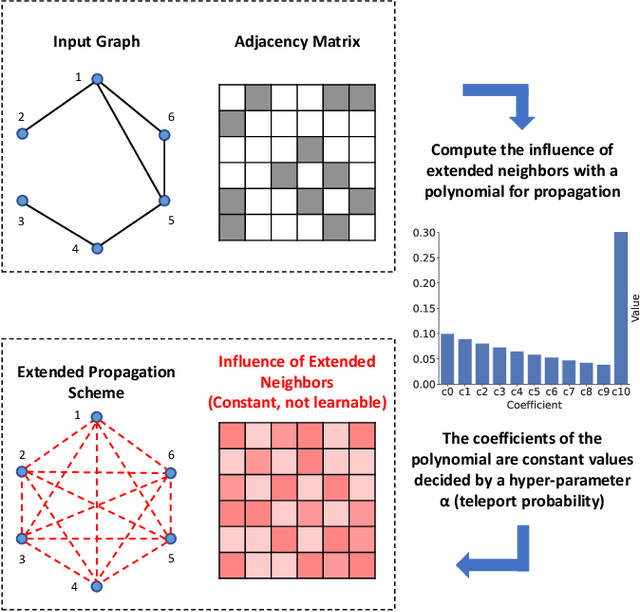
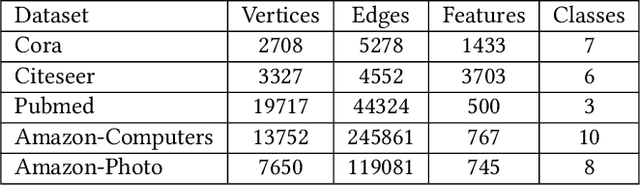
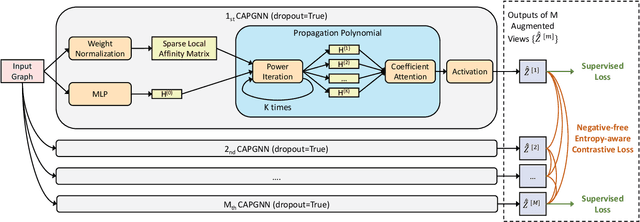

Graph Neural Networks (GNNs) have achieved great success in processing graph data by extracting and propagating structure-aware features. Existing GNN research designs various propagation schemes to guide the aggregation of neighbor information. Recently the field has advanced from local propagation schemes that focus on local neighbors towards extended propagation schemes that can directly deal with extended neighbors consisting of both local and high-order neighbors. Despite the impressive performance, existing approaches are still insufficient to build an efficient and learnable extended propagation scheme that can adaptively adjust the influence of local and high-order neighbors. This paper proposes an efficient yet effective end-to-end framework, namely Contrastive Adaptive Propagation Graph Neural Networks (CAPGNN), to address these issues by combining Personalized PageRank and attention techniques. CAPGNN models the learnable extended propagation scheme with a polynomial of a sparse local affinity matrix, where the polynomial relies on Personalized PageRank to provide superior initial coefficients. In order to adaptively adjust the influence of both local and high-order neighbors, a coefficient-attention model is introduced to learn to adjust the coefficients of the polynomial. In addition, we leverage self-supervised learning techniques and design a negative-free entropy-aware contrastive loss to explicitly take advantage of unlabeled data for training. We implement CAPGNN as two different versions named CAPGCN and CAPGAT, which use static and dynamic sparse local affinity matrices, respectively. Experiments on graph benchmark datasets suggest that CAPGNN can consistently outperform or match state-of-the-art baselines. The source code is publicly available at https://github.com/hujunxianligong/CAPGNN.