 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating topology biases in Graph Diffusion via Counterfactual Intervention
Mar 02, 2026Graph diffusion models have gained significant attention in graph generation tasks, but they often inherit and amplify topology biases from sensitive attributes (e.g. gender, age, region), leading to unfair synthetic graphs. Existing fair graph generation using diffusion models is limited to specific graph-based applications with complete labels or requires simultaneous updates for graph structure and node attributes, making them unsuitable for general usage. To relax these limitations by applying the debiasing method directly on graph topology, we propose Fair Graph Diffusion Model (FairGDiff), a counterfactual-based one-step solution that mitigates topology biases while balancing fairness and utility. In detail, we construct a causal model to capture the relationship between sensitive attributes, biased link formation, and the generated graph structure. By answering the counterfactual question "Would the graph structure change if the sensitive attribute were different?", we estimate an unbiased treatment and incorporate it into the diffusion process. FairGDiff integrates counterfactual learning into both forward diffusion and backward denoising, ensuring that the generated graphs are independent of sensitive attributes while preserving structural integrity. Extensive experiments on real-world datasets demonstrate that FairGDiff achieves a superior trade-off between fairness and utility, outperforming existing fair graph generation methods while maintaining scalability.
DeepEraser: Deep Iterative Context Mining for Generic Text Eraser
Feb 29, 2024



In this work, we present DeepEraser, an effective deep network for generic text removal. DeepEraser utilizes a recurrent architecture that erases the text in an image via iterative operations. Our idea comes from the process of erasing pencil script, where the text area designated for removal is subject to continuous monitoring and the text is attenuated progressively, ensuring a thorough and clean erasure. Technically, at each iteration, an innovative erasing module is deployed, which not only explicitly aggregates the previous erasing progress but also mines additional semantic context to erase the target text. Through iterative refinements, the text regions are progressively replaced with more appropriate content and finally converge to a relatively accurate status. Furthermore, a custom mask generation strategy is introduced to improve the capability of DeepEraser for adaptive text removal, as opposed to indiscriminately removing all the text in an image. Our DeepEraser is notably compact with only 1.4M parameters and trained in an end-to-end manner. To verify its effectiveness, extensive experiments are conducted on several prevalent benchmarks, including SCUT-Syn, SCUT-EnsText, and Oxford Synthetic text dataset. The quantitative and qualitative results demonstrate the effectiveness of our DeepEraser over the state-of-the-art methods, as well as its strong generalization ability in custom mask text removal. The codes and pre-trained models are available at https://github.com/fh2019ustc/DeepEraser
SimFIR: A Simple Framework for Fisheye Image Rectification with Self-supervised Representation Learning
Aug 17, 2023In fisheye images, rich distinct distortion patterns are regularly distributed in the image plane. These distortion patterns are independent of the visual content and provide informative cues for rectification. To make the best of such rectification cues, we introduce SimFIR, a simple framework for fisheye image rectification based on self-supervised representation learning. Technically, we first split a fisheye image into multiple patches and extract their representations with a Vision Transformer (ViT). To learn fine-grained distortion representations, we then associate different image patches with their specific distortion patterns based on the fisheye model, and further subtly design an innovative unified distortion-aware pretext task for their learning. The transfer performance on the downstream rectification task is remarkably boosted, which verifies the effectiveness of the learned representations. Extensive experiments are conducted, and the quantitative and qualitative results demonstrate the superiority of our method over the state-of-the-art algorithms as well as its strong generalization ability on real-world fisheye images.
Serial-parallel Multi-Scale Feature Fusion for Anatomy-Oriented Hand Joint Detection
Feb 19, 2021

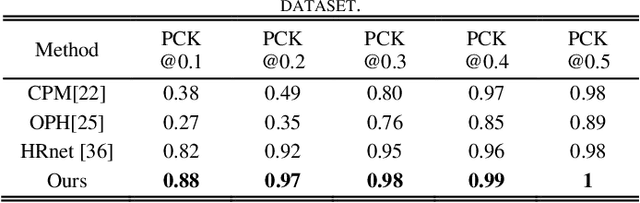

Accurate hand joints detection from images is a fundamental topic which is essential for many applications in computer vision and human computer interaction. This paper presents a two stage network for hand joints detection from single unmarked image by using serial-parallel multi-scale feature fusion. In stage I, the hand regions are located by a pre-trained network, and the features of each detected hand region are extracted by a shallow spatial hand features representation module. The extracted hand features are then fed into stage II, which consists of serially connected feature extraction modules with similar structures, called "multi-scale feature fusion" (MSFF). A MSFF contains parallel multi-scale feature extraction branches, which generate initial hand joint heatmaps. The initial heatmaps are then mutually reinforced by the anatomic relationship between hand joints. The experimental results on five hand joints datasets show that the proposed network overperforms the state-of-the-art methods.
Assertion-based QA with Question-Aware Open Information Extraction
Jan 23, 2018
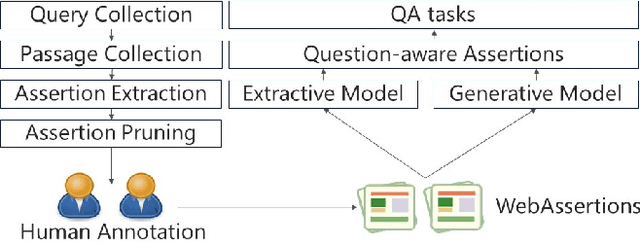

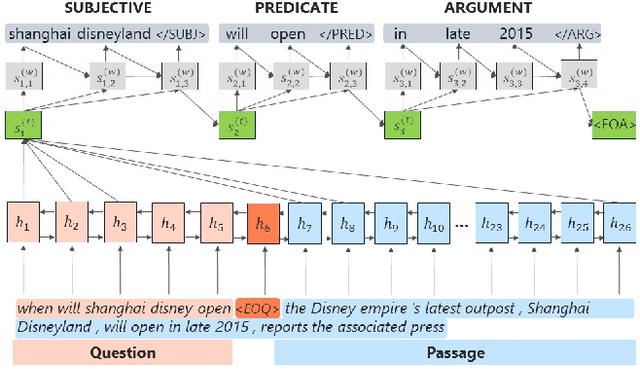
We present assertion based question answering (ABQA), an open domain question answering task that takes a question and a passage as inputs, and outputs a semi-structured assertion consisting of a subject, a predicate and a list of arguments. An assertion conveys more evidences than a short answer span in reading comprehension, and it is more concise than a tedious passage in passage-based QA. These advantages make ABQA more suitable for human-computer interaction scenarios such as voice-controlled speakers. Further progress towards improving ABQA requires richer supervised dataset and powerful models of text understanding. To remedy this, we introduce a new dataset called WebAssertions, which includes hand-annotated QA labels for 358,427 assertions in 55,960 web passages. To address ABQA, we develop both generative and extractive approaches. The backbone of our generative approach is sequence to sequence learning. In order to capture the structure of the output assertion, we introduce a hierarchical decoder that first generates the structure of the assertion and then generates the words of each field. The extractive approach is based on learning to rank. Features at different levels of granularity are designed to measure the semantic relevance between a question and an assertion. Experimental results show that our approaches have the ability to infer question-aware assertions from a passage. We further evaluate our approaches by incorporating the ABQA results as additional features in passage-based QA. Results on two datasets show that ABQA features significantly improve the accuracy on passage-based~QA.