 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBookNet: Book Image Rectification via Cross-Page Attention Network
Jan 29, 2026Book image rectification presents unique challenges in document image processing due to complex geometric distortions from binding constraints, where left and right pages exhibit distinctly asymmetric curvature patterns. However, existing single-page document image rectification methods fail to capture the coupled geometric relationships between adjacent pages in books. In this work, we introduce BookNet, the first end-to-end deep learning framework specifically designed for dual-page book image rectification. BookNet adopts a dual-branch architecture with cross-page attention mechanisms, enabling it to estimate warping flows for both individual pages and the complete book spread, explicitly modeling how left and right pages influence each other. Moreover, to address the absence of specialized datasets, we present Book3D, a large-scale synthetic dataset for training, and Book100, a comprehensive real-world benchmark for evaluation. Extensive experiments demonstrate that BookNet outperforms existing state-of-the-art methods on book image rectification. Code and dataset will be made publicly available.
SwinShadow: Shifted Window for Ambiguous Adjacent Shadow Detection
Aug 07, 2024
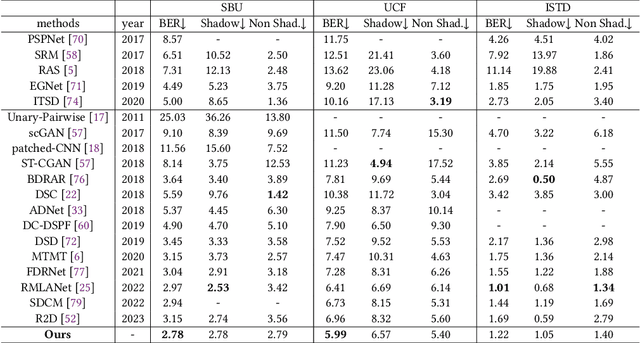


Shadow detection is a fundamental and challenging task in many computer vision applications. Intuitively, most shadows come from the occlusion of light by the object itself, resulting in the object and its shadow being contiguous (referred to as the adjacent shadow in this paper). In this case, when the color of the object is similar to that of the shadow, existing methods struggle to achieve accurate detection. To address this problem, we present SwinShadow, a transformer-based architecture that fully utilizes the powerful shifted window mechanism for detecting adjacent shadows. The mechanism operates in two steps. Initially, it applies local self-attention within a single window, enabling the network to focus on local details. Subsequently, it shifts the attention windows to facilitate inter-window attention, enabling the capture of a broader range of adjacent information. These combined steps significantly improve the network's capacity to distinguish shadows from nearby objects. And the whole process can be divided into three parts: encoder, decoder, and feature integration. During encoding, we adopt Swin Transformer to acquire hierarchical features. Then during decoding, for shallow layers, we propose a deep supervision (DS) module to suppress the false positives and boost the representation capability of shadow features for subsequent processing, while for deep layers, we leverage a double attention (DA) module to integrate local and shifted window in one stage to achieve a larger receptive field and enhance the continuity of information. Ultimately, a new multi-level aggregation (MLA) mechanism is applied to fuse the decoded features for mask prediction. Extensive experiments on three shadow detection benchmark datasets, SBU, UCF, and ISTD, demonstrate that our network achieves good performance in terms of balance error rate (BER).
RoFIR: Robust Fisheye Image Rectification Framework Impervious to Optical Center Deviation
Jun 27, 2024



Fisheye images are categorized fisheye into central and deviated based on the optical center position. Existing rectification methods are limited to central fisheye images, while this paper proposes a novel method that extends to deviated fisheye image rectification. The challenge lies in the variant global distortion distribution pattern caused by the random optical center position. To address this challenge, we propose a distortion vector map (DVM) that measures the degree and direction of local distortion. By learning the DVM, the model can independently identify local distortions at each pixel without relying on global distortion patterns. The model adopts a pre-training and fine-tuning training paradigm. In the pre-training stage, it predicts the distortion vector map and perceives the local distortion features of each pixel. In the fine-tuning stage, it predicts a pixel-wise flow map for deviated fisheye image rectification. We also propose a data augmentation method mixing central, deviated, and distorted-free images. Such data augmentation promotes the model performance in rectifying both central and deviated fisheye images, compared with models trained on single-type fisheye images. Extensive experiments demonstrate the effectiveness and superiority of the proposed method.
DeepEraser: Deep Iterative Context Mining for Generic Text Eraser
Feb 29, 2024



In this work, we present DeepEraser, an effective deep network for generic text removal. DeepEraser utilizes a recurrent architecture that erases the text in an image via iterative operations. Our idea comes from the process of erasing pencil script, where the text area designated for removal is subject to continuous monitoring and the text is attenuated progressively, ensuring a thorough and clean erasure. Technically, at each iteration, an innovative erasing module is deployed, which not only explicitly aggregates the previous erasing progress but also mines additional semantic context to erase the target text. Through iterative refinements, the text regions are progressively replaced with more appropriate content and finally converge to a relatively accurate status. Furthermore, a custom mask generation strategy is introduced to improve the capability of DeepEraser for adaptive text removal, as opposed to indiscriminately removing all the text in an image. Our DeepEraser is notably compact with only 1.4M parameters and trained in an end-to-end manner. To verify its effectiveness, extensive experiments are conducted on several prevalent benchmarks, including SCUT-Syn, SCUT-EnsText, and Oxford Synthetic text dataset. The quantitative and qualitative results demonstrate the effectiveness of our DeepEraser over the state-of-the-art methods, as well as its strong generalization ability in custom mask text removal. The codes and pre-trained models are available at https://github.com/fh2019ustc/DeepEraser
DocMAE: Document Image Rectification via Self-supervised Representation Learning
Apr 20, 2023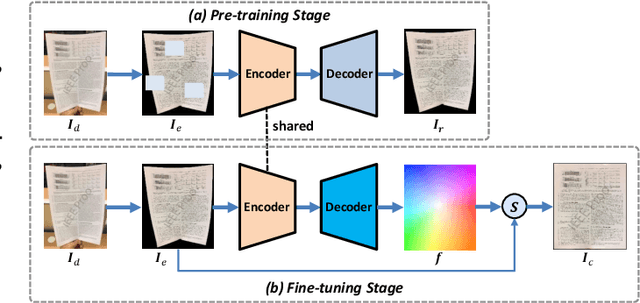


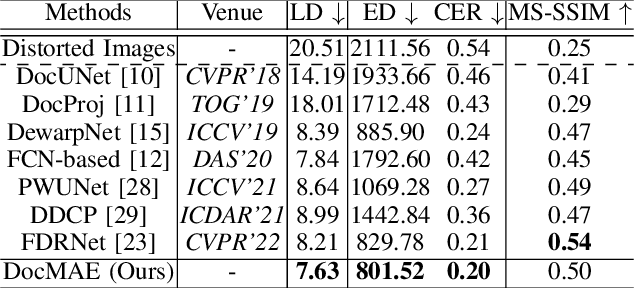
Tremendous efforts have been made on document image rectification, but how to learn effective representation of such distorted images is still under-explored. In this paper, we present DocMAE, a novel self-supervised framework for document image rectification. Our motivation is to encode the structural cues in document images by leveraging masked autoencoder to benefit the rectification, i.e., the document boundaries, and text lines. Specifically, we first mask random patches of the background-excluded document images and then reconstruct the missing pixels. With such a self-supervised learning approach, the network is encouraged to learn the intrinsic structure of deformed documents by restoring document boundaries and missing text lines. Transfer performance in the downstream rectification task validates the effectiveness of our method. Extensive experiments are conducted to demonstrate the effectiveness of our method.
Deep Unrestricted Document Image Rectification
Apr 18, 2023In recent years, tremendous efforts have been made on document image rectification, but existing advanced algorithms are limited to processing restricted document images, i.e., the input images must incorporate a complete document. Once the captured image merely involves a local text region, its rectification quality is degraded and unsatisfactory. Our previously proposed DocTr, a transformer-assisted network for document image rectification, also suffers from this limitation. In this work, we present DocTr++, a novel unified framework for document image rectification, without any restrictions on the input distorted images. Our major technical improvements can be concluded in three aspects. Firstly, we upgrade the original architecture by adopting a hierarchical encoder-decoder structure for multi-scale representation extraction and parsing. Secondly, we reformulate the pixel-wise mapping relationship between the unrestricted distorted document images and the distortion-free counterparts. The obtained data is used to train our DocTr++ for unrestricted document image rectification. Thirdly, we contribute a real-world test set and metrics applicable for evaluating the rectification quality. To our best knowledge, this is the first learning-based method for the rectification of unrestricted document images. Extensive experiments are conducted, and the results demonstrate the effectiveness and superiority of our method. We hope our DocTr++ will serve as a strong baseline for generic document image rectification, prompting the further advancement and application of learning-based algorithms. The source code and the proposed dataset are publicly available at https://github.com/fh2019ustc/DocTr-Plus.