 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocR1: Evidence Page-Guided GRPO for Multi-Page Document Understanding
Aug 10, 2025Understanding multi-page documents poses a significant challenge for multimodal large language models (MLLMs), as it requires fine-grained visual comprehension and multi-hop reasoning across pages. While prior work has explored reinforcement learning (RL) for enhancing advanced reasoning in MLLMs, its application to multi-page document understanding remains underexplored. In this paper, we introduce DocR1, an MLLM trained with a novel RL framework, Evidence Page-Guided GRPO (EviGRPO). EviGRPO incorporates an evidence-aware reward mechanism that promotes a coarse-to-fine reasoning strategy, guiding the model to first retrieve relevant pages before generating answers. This training paradigm enables us to build high-quality models with limited supervision. To support this, we design a two-stage annotation pipeline and a curriculum learning strategy, based on which we construct two datasets: EviBench, a high-quality training set with 4.8k examples, and ArxivFullQA, an evaluation benchmark with 8.6k QA pairs based on scientific papers. Extensive experiments across a wide range of benchmarks demonstrate that DocR1 achieves state-of-the-art performance on multi-page tasks, while consistently maintaining strong results on single-page benchmarks.
ROOT: VLM based System for Indoor Scene Understanding and Beyond
Nov 24, 2024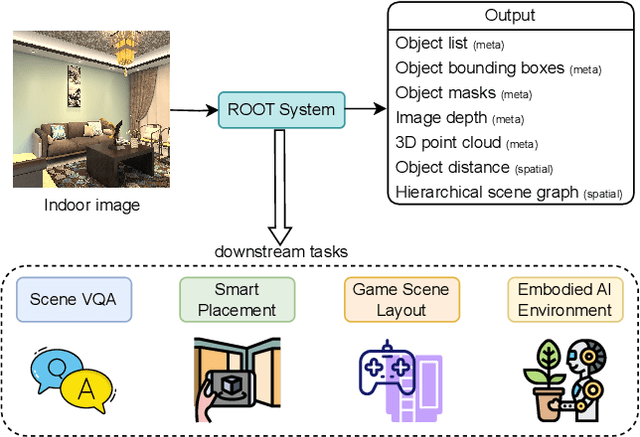
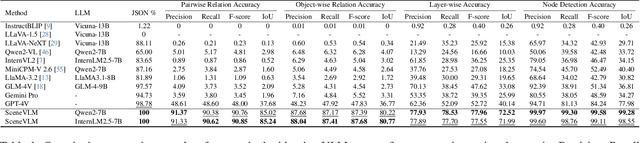
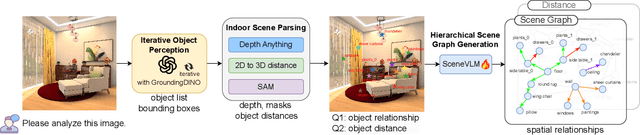
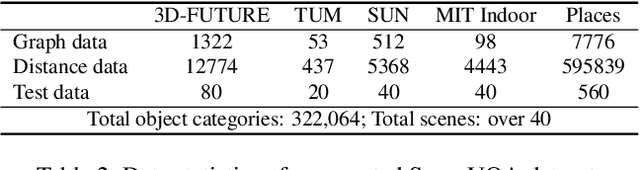
Recently, Vision Language Models (VLMs) have experienced significant advancements, yet these models still face challenges in spatial hierarchical reasoning within indoor scenes. In this study, we introduce ROOT, a VLM-based system designed to enhance the analysis of indoor scenes. Specifically, we first develop an iterative object perception algorithm using GPT-4V to detect object entities within indoor scenes. This is followed by employing vision foundation models to acquire additional meta-information about the scene, such as bounding boxes. Building on this foundational data, we propose a specialized VLM, SceneVLM, which is capable of generating spatial hierarchical scene graphs and providing distance information for objects within indoor environments. This information enhances our understanding of the spatial arrangement of indoor scenes. To train our SceneVLM, we collect over 610,000 images from various public indoor datasets and implement a scene data generation pipeline with a semi-automated technique to establish relationships and estimate distances among indoor objects. By utilizing this enriched data, we conduct various training recipes and finish SceneVLM. Our experiments demonstrate that \rootname facilitates indoor scene understanding and proves effective in diverse downstream applications, such as 3D scene generation and embodied AI. The code will be released at \url{https://github.com/harrytea/ROOT}.
AdaptVision: Dynamic Input Scaling in MLLMs for Versatile Scene Understanding
Aug 30, 2024



Over the past few years, the advancement of Multimodal Large Language Models (MLLMs) has captured the wide interest of researchers, leading to numerous innovations to enhance MLLMs' comprehension. In this paper, we present AdaptVision, a multimodal large language model specifically designed to dynamically process input images at varying resolutions. We hypothesize that the requisite number of visual tokens for the model is contingent upon both the resolution and content of the input image. Generally, natural images with a lower information density can be effectively interpreted by the model using fewer visual tokens at reduced resolutions. In contrast, images containing textual content, such as documents with rich text, necessitate a higher number of visual tokens for accurate text interpretation due to their higher information density. Building on this insight, we devise a dynamic image partitioning module that adjusts the number of visual tokens according to the size and aspect ratio of images. This method mitigates distortion effects that arise from resizing images to a uniform resolution and dynamically optimizing the visual tokens input to the LLMs. Our model is capable of processing images with resolutions up to $1008\times 1008$. Extensive experiments across various datasets demonstrate that our method achieves impressive performance in handling vision-language tasks in both natural and text-related scenes. The source code and dataset are now publicly available at \url{https://github.com/harrytea/AdaptVision}.
LaneTCA: Enhancing Video Lane Detection with Temporal Context Aggregation
Aug 25, 2024In video lane detection, there are rich temporal contexts among successive frames, which is under-explored in existing lane detectors. In this work, we propose LaneTCA to bridge the individual video frames and explore how to effectively aggregate the temporal context. Technically, we develop an accumulative attention module and an adjacent attention module to abstract the long-term and short-term temporal context, respectively. The accumulative attention module continuously accumulates visual information during the journey of a vehicle, while the adjacent attention module propagates this lane information from the previous frame to the current frame. The two modules are meticulously designed based on the transformer architecture. Finally, these long-short context features are fused with the current frame features to predict the lane lines in the current frame. Extensive quantitative and qualitative experiments are conducted on two prevalent benchmark datasets. The results demonstrate the effectiveness of our method, achieving several new state-of-the-art records. The codes and models are available at https://github.com/Alex-1337/LaneTCA
SwinShadow: Shifted Window for Ambiguous Adjacent Shadow Detection
Aug 07, 2024
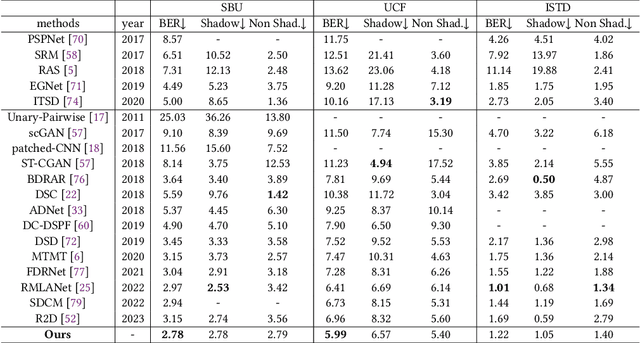


Shadow detection is a fundamental and challenging task in many computer vision applications. Intuitively, most shadows come from the occlusion of light by the object itself, resulting in the object and its shadow being contiguous (referred to as the adjacent shadow in this paper). In this case, when the color of the object is similar to that of the shadow, existing methods struggle to achieve accurate detection. To address this problem, we present SwinShadow, a transformer-based architecture that fully utilizes the powerful shifted window mechanism for detecting adjacent shadows. The mechanism operates in two steps. Initially, it applies local self-attention within a single window, enabling the network to focus on local details. Subsequently, it shifts the attention windows to facilitate inter-window attention, enabling the capture of a broader range of adjacent information. These combined steps significantly improve the network's capacity to distinguish shadows from nearby objects. And the whole process can be divided into three parts: encoder, decoder, and feature integration. During encoding, we adopt Swin Transformer to acquire hierarchical features. Then during decoding, for shallow layers, we propose a deep supervision (DS) module to suppress the false positives and boost the representation capability of shadow features for subsequent processing, while for deep layers, we leverage a double attention (DA) module to integrate local and shifted window in one stage to achieve a larger receptive field and enhance the continuity of information. Ultimately, a new multi-level aggregation (MLA) mechanism is applied to fuse the decoded features for mask prediction. Extensive experiments on three shadow detection benchmark datasets, SBU, UCF, and ISTD, demonstrate that our network achieves good performance in terms of balance error rate (BER).
TextCoT: Zoom In for Enhanced Multimodal Text-Rich Image Understanding
Apr 15, 2024The advent of Large Multimodal Models (LMMs) has sparked a surge in research aimed at harnessing their remarkable reasoning abilities. However, for understanding text-rich images, challenges persist in fully leveraging the potential of LMMs, and existing methods struggle with effectively processing high-resolution images. In this work, we propose TextCoT, a novel Chain-of-Thought framework for text-rich image understanding. TextCoT utilizes the captioning ability of LMMs to grasp the global context of the image and the grounding capability to examine local textual regions. This allows for the extraction of both global and local visual information, facilitating more accurate question-answering. Technically, TextCoT consists of three stages, including image overview, coarse localization, and fine-grained observation. The image overview stage provides a comprehensive understanding of the global scene information, and the coarse localization stage approximates the image area containing the answer based on the question asked. Then, integrating the obtained global image descriptions, the final stage further examines specific regions to provide accurate answers. Our method is free of extra training, offering immediate plug-and-play functionality. Extensive experiments are conducted on a series of text-rich image question-answering benchmark datasets based on several advanced LMMs, and the results demonstrate the effectiveness and strong generalization ability of our method. Code is available at https://github.com/bzluan/TextCoT.
Towards Improving Document Understanding: An Exploration on Text-Grounding via MLLMs
Nov 22, 2023In the field of document understanding, significant advances have been made in the fine-tuning of Multimodal Large Language Models (MLLMs) with instruction-following data. Nevertheless, the potential of text-grounding capability within text-rich scenarios remains underexplored. In this paper, we present a text-grounding document understanding model, termed TGDoc, which addresses this deficiency by enhancing MLLMs with the ability to discern the spatial positioning of text within images. Empirical evidence suggests that text-grounding improves the model's interpretation of textual content, thereby elevating its proficiency in comprehending text-rich images. Specifically, we compile a dataset containing 99K PowerPoint presentations sourced from the internet. We formulate instruction tuning tasks including text detection, recognition, and spotting to facilitate the cohesive alignment between the visual encoder and large language model. Moreover, we curate a collection of text-rich images and prompt the text-only GPT-4 to generate 12K high-quality conversations, featuring textual locations within text-rich scenarios. By integrating text location data into the instructions, TGDoc is adept at discerning text locations during the visual question process. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple text-rich benchmarks, validating the effectiveness of our method.
Progressive Recurrent Network for Shadow Removal
Nov 01, 2023
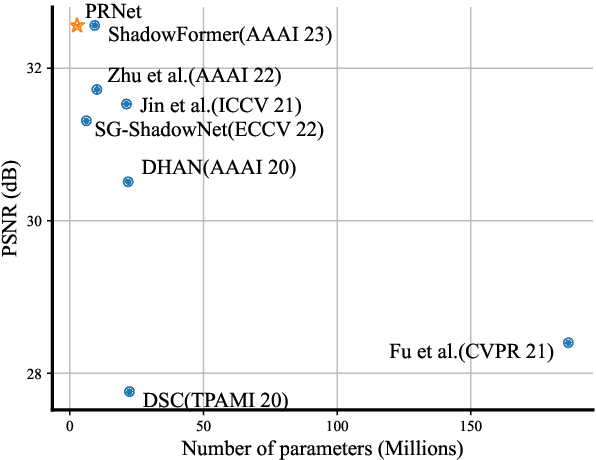
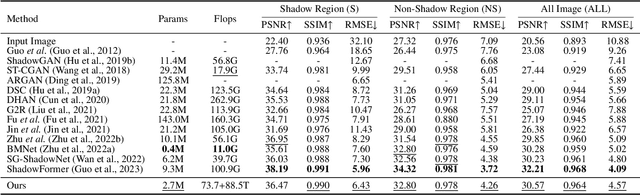
Single-image shadow removal is a significant task that is still unresolved. Most existing deep learning-based approaches attempt to remove the shadow directly, which can not deal with the shadow well. To handle this issue, we consider removing the shadow in a coarse-to-fine fashion and propose a simple but effective Progressive Recurrent Network (PRNet). The network aims to remove the shadow progressively, enabing us to flexibly adjust the number of iterations to strike a balance between performance and time. Our network comprises two parts: shadow feature extraction and progressive shadow removal. Specifically, the first part is a shallow ResNet which constructs the representations of the input shadow image on its original size, preventing the loss of high-frequency details caused by the downsampling operation. The second part has two critical components: the re-integration module and the update module. The proposed re-integration module can fully use the outputs of the previous iteration, providing input for the update module for further shadow removal. In this way, the proposed PRNet makes the whole process more concise and only uses 29% network parameters than the best published method. Extensive experiments on the three benchmarks, ISTD, ISTD+, and SRD, demonstrate that our method can effectively remove shadows and achieve superior performance.
Detect Any Shadow: Segment Anything for Video Shadow Detection
May 26, 2023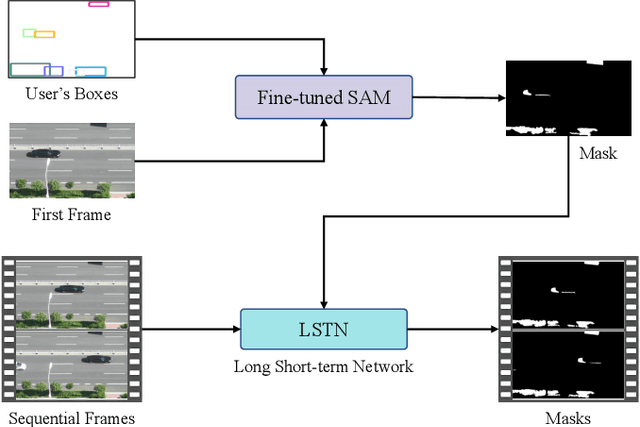



Segment anything model (SAM) has achieved great success in the field of natural image segmentation. Nevertheless, SAM tends to classify shadows as background, resulting in poor segmentation performance for shadow detection task. In this paper, we propose an simple but effective approach for fine tuning SAM to detect shadows. Additionally, we also combine it with long short-term attention mechanism to extend its capabilities to video shadow detection. Specifically, we first fine tune SAM by utilizing shadow data combined with sparse prompts and apply the fine-tuned model to detect a specific frame (e.g., first frame) in the video with a little user assistance. Subsequently, using the detected frame as a reference, we employ a long short-term network to learn spatial correlations between distant frames and temporal consistency between contiguous frames, thereby achieving shadow information propagation across frames. Extensive experimental results demonstrate that our method outperforms the state-of-the-art techniques, with improvements of 17.2% and 3.3% in terms of MAE and IoU, respectively, validating the effectiveness of our method.
UDoc-GAN: Unpaired Document Illumination Correction with Background Light Prior
Oct 15, 2022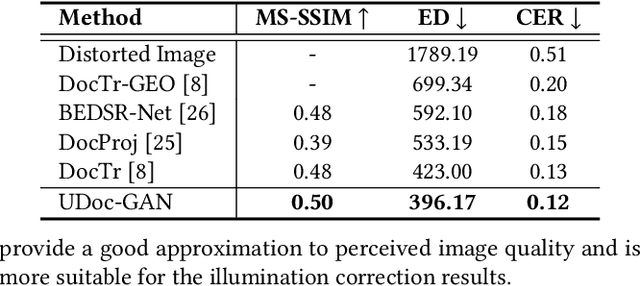
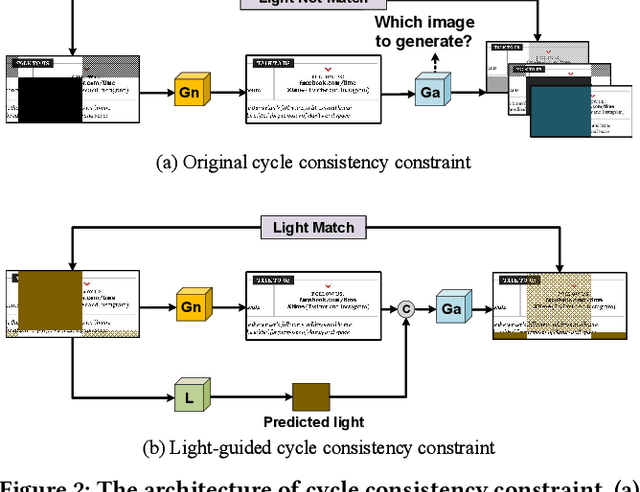
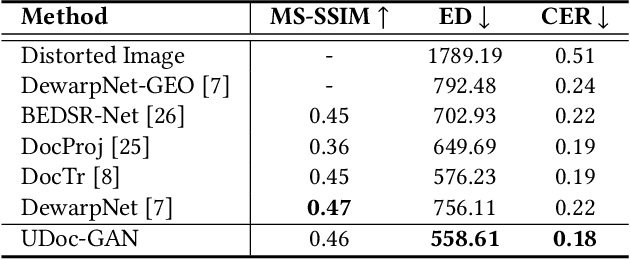
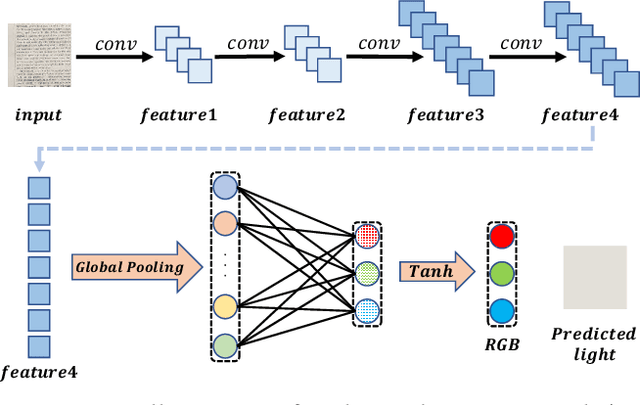
Document images captured by mobile devices are usually degraded by uncontrollable illumination, which hampers the clarity of document content. Recently, a series of research efforts have been devoted to correcting the uneven document illumination. However, existing methods rarely consider the use of ambient light information, and usually rely on paired samples including degraded and the corrected ground-truth images which are not always accessible. To this end, we propose UDoc-GAN, the first framework to address the problem of document illumination correction under the unpaired setting. Specifically, we first predict the ambient light features of the document. Then, according to the characteristics of different level of ambient lights, we re-formulate the cycle consistency constraint to learn the underlying relationship between normal and abnormal illumination domains. To prove the effectiveness of our approach, we conduct extensive experiments on DocProj dataset under the unpaired setting. Compared with the state-of-the-art approaches, our method demonstrates promising performance in terms of character error rate (CER) and edit distance (ED), together with better qualitative results for textual detail preservation. The source code is now publicly available at https://github.com/harrytea/UDoc-GAN.