 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROOT: VLM based System for Indoor Scene Understanding and Beyond
Nov 24, 2024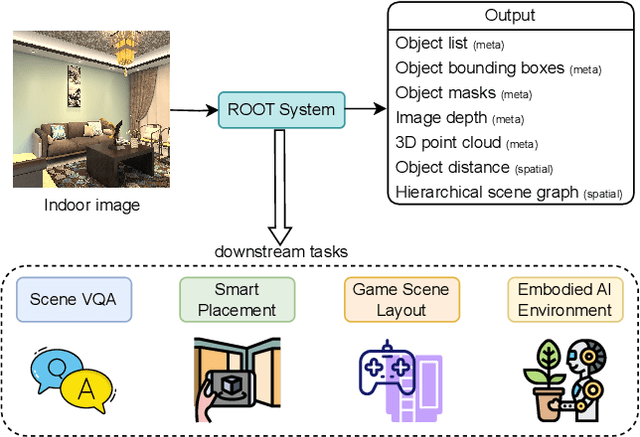
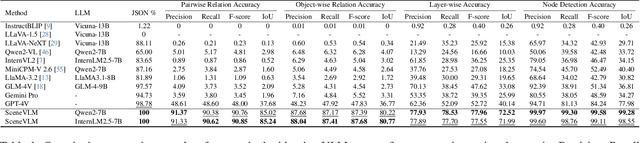
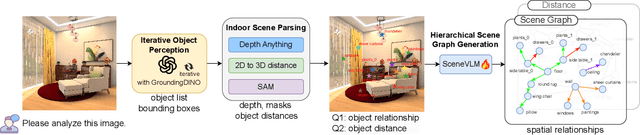
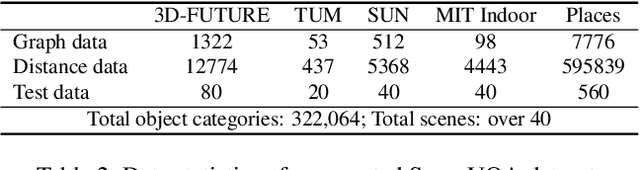
Recently, Vision Language Models (VLMs) have experienced significant advancements, yet these models still face challenges in spatial hierarchical reasoning within indoor scenes. In this study, we introduce ROOT, a VLM-based system designed to enhance the analysis of indoor scenes. Specifically, we first develop an iterative object perception algorithm using GPT-4V to detect object entities within indoor scenes. This is followed by employing vision foundation models to acquire additional meta-information about the scene, such as bounding boxes. Building on this foundational data, we propose a specialized VLM, SceneVLM, which is capable of generating spatial hierarchical scene graphs and providing distance information for objects within indoor environments. This information enhances our understanding of the spatial arrangement of indoor scenes. To train our SceneVLM, we collect over 610,000 images from various public indoor datasets and implement a scene data generation pipeline with a semi-automated technique to establish relationships and estimate distances among indoor objects. By utilizing this enriched data, we conduct various training recipes and finish SceneVLM. Our experiments demonstrate that \rootname facilitates indoor scene understanding and proves effective in diverse downstream applications, such as 3D scene generation and embodied AI. The code will be released at \url{https://github.com/harrytea/ROOT}.
Virtual-Taobao: Virtualizing Real-world Online Retail Environment for Reinforcement Learning
May 25, 2018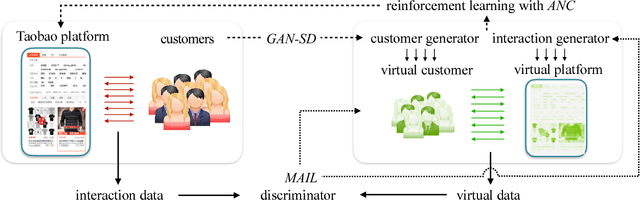
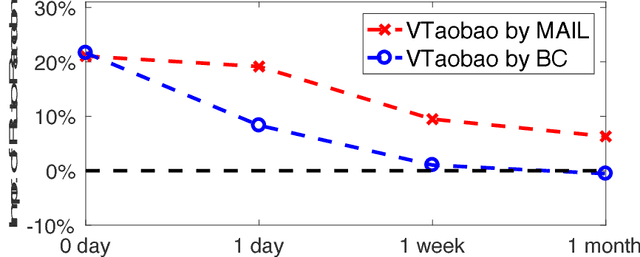
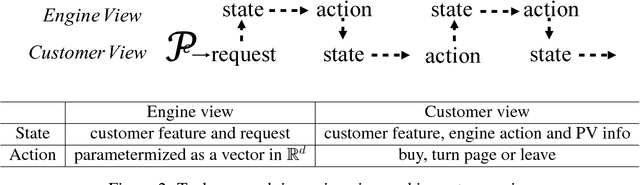

Applying reinforcement learning in physical-world tasks is extremely challenging. It is commonly infeasible to sample a large number of trials, as required by current reinforcement learning methods, in a physical environment. This paper reports our project on using reinforcement learning for better commodity search in Taobao, one of the largest online retail platforms and meanwhile a physical environment with a high sampling cost. Instead of training reinforcement learning in Taobao directly, we present our approach: first we build Virtual Taobao, a simulator learned from historical customer behavior data through the proposed GAN-SD (GAN for Simulating Distributions) and MAIL (multi-agent adversarial imitation learning), and then we train policies in Virtual Taobao with no physical costs in which ANC (Action Norm Constraint) strategy is proposed to reduce over-fitting. In experiments, Virtual Taobao is trained from hundreds of millions of customers' records, and its properties are compared with the real environment. The results disclose that Virtual Taobao faithfully recovers important properties of the real environment. We also show that the policies trained in Virtual Taobao can have significantly superior online performance to the traditional supervised approaches. We hope our work could shed some light on reinforcement learning applications in complex physical environments.