 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBookNet: Book Image Rectification via Cross-Page Attention Network
Jan 29, 2026Book image rectification presents unique challenges in document image processing due to complex geometric distortions from binding constraints, where left and right pages exhibit distinctly asymmetric curvature patterns. However, existing single-page document image rectification methods fail to capture the coupled geometric relationships between adjacent pages in books. In this work, we introduce BookNet, the first end-to-end deep learning framework specifically designed for dual-page book image rectification. BookNet adopts a dual-branch architecture with cross-page attention mechanisms, enabling it to estimate warping flows for both individual pages and the complete book spread, explicitly modeling how left and right pages influence each other. Moreover, to address the absence of specialized datasets, we present Book3D, a large-scale synthetic dataset for training, and Book100, a comprehensive real-world benchmark for evaluation. Extensive experiments demonstrate that BookNet outperforms existing state-of-the-art methods on book image rectification. Code and dataset will be made publicly available.
Multi-Cue Adaptive Visual Token Pruning for Large Vision-Language Models
Mar 11, 2025As the computational needs of Large Vision-Language Models (LVLMs) increase, visual token pruning has proven effective in improving inference speed and memory efficiency. Traditional pruning methods in LVLMs predominantly focus on attention scores to determine token relevance, overlooking critical aspects such as spatial position and token similarity. To this end, we introduce AdaptPrune, a novel plug-and-play training-free pruning method that builds on conventional attention-based pruning by integrating spatial distance and token similarity with an adaptive NMS approach. Our method is based on several observed phenomena in large models: the positional bias in the model's image attention and the redundancy of token information ignored by previous approaches. By integrating attention, spatial, and similarity information, our approach ensures a comprehensive evaluation of token importance and substantially refines the pruning decisions. Our method has been extensively tested across various LVLMs and benchmarks, confirming its robustness and adaptability. The results demonstrate that AdaptPrune consistently outperforms existing methods across various pruning ratios. Code is available at https://github.com/bzluan/AdaptPrune.
TextCoT: Zoom In for Enhanced Multimodal Text-Rich Image Understanding
Apr 15, 2024The advent of Large Multimodal Models (LMMs) has sparked a surge in research aimed at harnessing their remarkable reasoning abilities. However, for understanding text-rich images, challenges persist in fully leveraging the potential of LMMs, and existing methods struggle with effectively processing high-resolution images. In this work, we propose TextCoT, a novel Chain-of-Thought framework for text-rich image understanding. TextCoT utilizes the captioning ability of LMMs to grasp the global context of the image and the grounding capability to examine local textual regions. This allows for the extraction of both global and local visual information, facilitating more accurate question-answering. Technically, TextCoT consists of three stages, including image overview, coarse localization, and fine-grained observation. The image overview stage provides a comprehensive understanding of the global scene information, and the coarse localization stage approximates the image area containing the answer based on the question asked. Then, integrating the obtained global image descriptions, the final stage further examines specific regions to provide accurate answers. Our method is free of extra training, offering immediate plug-and-play functionality. Extensive experiments are conducted on a series of text-rich image question-answering benchmark datasets based on several advanced LMMs, and the results demonstrate the effectiveness and strong generalization ability of our method. Code is available at https://github.com/bzluan/TextCoT.
Improving Handwritten OCR with Training Samples Generated by Glyph Conditional Denoising Diffusion Probabilistic Model
May 31, 2023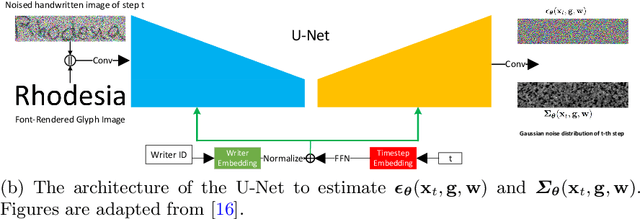
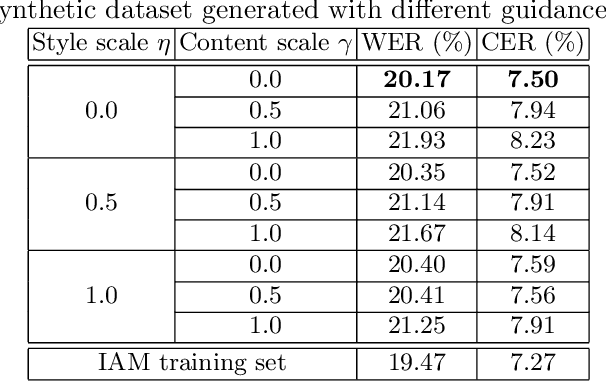

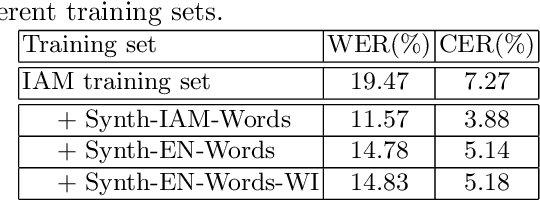
Constructing a highly accurate handwritten OCR system requires large amounts of representative training data, which is both time-consuming and expensive to collect. To mitigate the issue, we propose a denoising diffusion probabilistic model (DDPM) to generate training samples. This model conditions on a printed glyph image and creates mappings between printed characters and handwritten images, thus enabling the generation of photo-realistic handwritten samples with diverse styles and unseen text contents. However, the text contents in synthetic images are not always consistent with the glyph conditional images, leading to unreliable labels of synthetic samples. To address this issue, we further propose a progressive data filtering strategy to add those samples with a high confidence of correctness to the training set. Experimental results on IAM benchmark task show that OCR model trained with augmented DDPM-synthesized training samples can achieve about 45% relative word error rate reduction compared with the one trained on real data only.