 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssertion-based QA with Question-Aware Open Information Extraction
Paper and Code
Jan 23, 2018
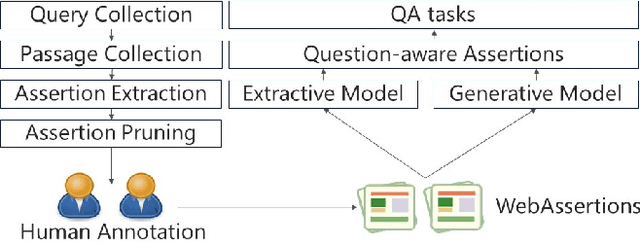

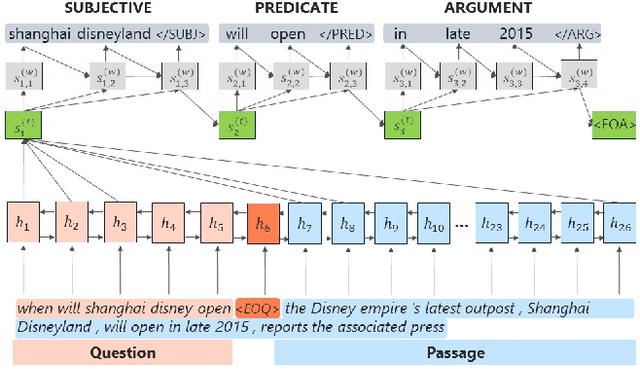
We present assertion based question answering (ABQA), an open domain question answering task that takes a question and a passage as inputs, and outputs a semi-structured assertion consisting of a subject, a predicate and a list of arguments. An assertion conveys more evidences than a short answer span in reading comprehension, and it is more concise than a tedious passage in passage-based QA. These advantages make ABQA more suitable for human-computer interaction scenarios such as voice-controlled speakers. Further progress towards improving ABQA requires richer supervised dataset and powerful models of text understanding. To remedy this, we introduce a new dataset called WebAssertions, which includes hand-annotated QA labels for 358,427 assertions in 55,960 web passages. To address ABQA, we develop both generative and extractive approaches. The backbone of our generative approach is sequence to sequence learning. In order to capture the structure of the output assertion, we introduce a hierarchical decoder that first generates the structure of the assertion and then generates the words of each field. The extractive approach is based on learning to rank. Features at different levels of granularity are designed to measure the semantic relevance between a question and an assertion. Experimental results show that our approaches have the ability to infer question-aware assertions from a passage. We further evaluate our approaches by incorporating the ABQA results as additional features in passage-based QA. Results on two datasets show that ABQA features significantly improve the accuracy on passage-based~QA.