 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal-GuideNet: Gaze-Probe Bidirectional Guidance in Obstetric Ultrasound Scanning
Paper and Code
Jul 26, 2022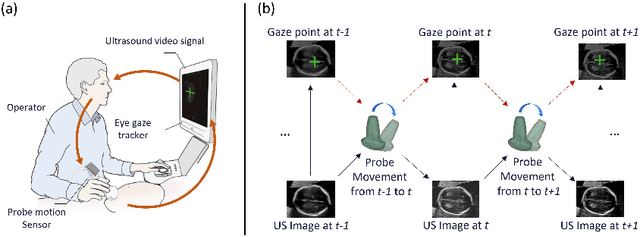
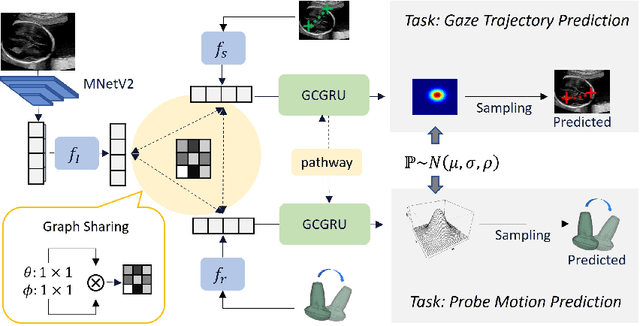
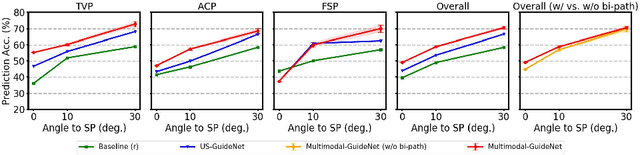
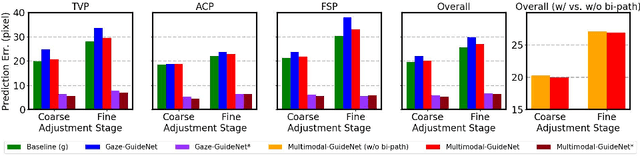
Eye trackers can provide visual guidance to sonographers during ultrasound (US) scanning. Such guidance is potentially valuable for less experienced operators to improve their scanning skills on how to manipulate the probe to achieve the desired plane. In this paper, a multimodal guidance approach (Multimodal-GuideNet) is proposed to capture the stepwise dependency between a real-world US video signal, synchronized gaze, and probe motion within a unified framework. To understand the causal relationship between gaze movement and probe motion, our model exploits multitask learning to jointly learn two related tasks: predicting gaze movements and probe signals that an experienced sonographer would perform in routine obstetric scanning. The two tasks are associated by a modality-aware spatial graph to detect the co-occurrence among the multi-modality inputs and share useful cross-modal information. Instead of a deterministic scanning path, Multimodal-GuideNet allows for scanning diversity by estimating the probability distribution of real scans. Experiments performed with three typical obstetric scanning examinations show that the new approach outperforms single-task learning for both probe motion guidance and gaze movement prediction. Multimodal-GuideNet also provides a visual guidance signal with an error rate of less than 10 pixels for a 224x288 US image.